こんにちは,米国データサイエンティストのかめ(@usdatascientist)です
データサイエンスのためのPython入門第8回です(講座の目次はこちら).今回は,NumPyを使って様々な行列(ndarray)を作ってみたいと思います.
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
そんなに難しい内容ではなく,どれも理解しやすいものだと思います.
また,全ての関数を覚える必要は全くありません.必要な時にググって使えればいいのです.関数名は無理して覚えなくてOK!
なお,前回の記事は重要度が高いです.まだ読んでない方はぜひ一読ください↓
様々なndarrayを作る
前回と前々回の記事では, np.array() でndarrayを作りました.(ndarrayというのは多次元のarrayです.)
|
1 2 |
ndarray = np.array([1, 2, 3]) print(ndarray) |
NumPyには様々なndarrayを作る関数が用意されているので紹介します.
- np.arange([start,] stop[, step])
よく使います.start以上stop未満の値をstepずつ増加させた値のarrayです.ちなみに↑の関数の引数の表記で,[]は省略可能を意味します.つまり,startとstepは省略可能で,それぞれ0と1がデフォルトで入ります.
説明するより使ってみた方が早いです.↓の例をみてください.
 np.arange(0, 5, 2)は0~0.49999…の値を2で区切った値のリストが返されています.
np.arange(0, 5, 2)は0~0.49999…の値を2で区切った値のリストが返されています.
np.arange(5)もnp.arange(0, 5)も0~0.49999…の値を1で区切った値のリストが返されています.
np.arange(0, 5, 1)も同じarrayが作れられます.試してみてください.
np.arange(0, 5, 0.1)なども試しに作ってみてください.なんとなくわかるはずです.
これは様々なところで使います.例えばある閾値をたくさん用意してその結果がどう変わるか見る場合に,np.arange()で閾値のリストを作ることができます.
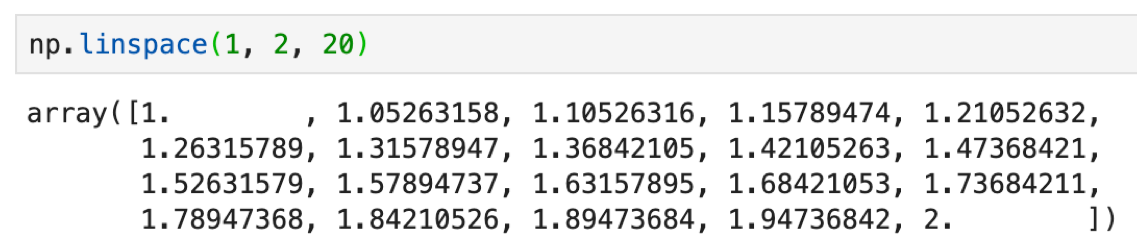
- np.linspace(start, stop, num=50)
np.arange()がstepだったのに対し,np.linspace()は要素の数(num)を指定します.startからstopまでの値をnum等分した値がarrayで返されます.stepを指定したい時はnp.arange()で,stepはなんでもいいが特定の数だけほしいという場合はnp.linspace()を使いましょう.stopの値を含むことに注意しましょう.
- .copy()
arrayをコピーします.本当にそれだけです.コピーされたarrayは全く別のオブジェクトになります.
|
1 2 3 4 5 6 7 8 9 |
ndarray = np.arange(0, 5) ndarray_copy = ndarray.copy() print("original array's id is {}".format(id(ndarray))) print("copied array's id is {}".format(id(ndarray_copy))) #changing original array ndarray[:] = 100 print('original array:\n', ndarray) print('copied array:\n', ndarray_copy) |
|
1 2 3 4 5 6 |
original array's id is 140485118824896 copied array's id is 140485120929104 original array: [100 100 100 100 100] copied array: [0 1 2 3 4] |
Pythonでは基本は参照渡しです.NumPy Arrayはmutableなオブジェクトなので,関数内で変更されると,元の変数にも影響があることに気をつけましょう.値渡しにしたいときに.copy()をよく使います.
参照渡しと値渡しについて一度復習しましょう.初心者が最初につまづくところかもしれません.以下の例をみてください.
|
1 2 3 4 5 6 |
def myfunc(n): print(id(n)) a = 'test' print(id(a)) myfunc(a) |
|
1 2 |
140080215091824 140080215091824 |
myfuncにa=’test’の文字列の変数を入れました.aと言う変数はid(a)から140080215091824というIDが割り当てられていて,メモリに保存されています.
myfunc(a)を実行したときに,myfuncの引数paramにaの情報が渡されるわけですが,このparamのIDをみても,同じIDが割り当てられていますね.
つまり,Pythonでは,関数に引数を渡す際には,値をコピーして渡しているのではなく,メモリの参照先(アドレス)を渡しているんですね.これを参照渡しといい,逆に値をコピーして渡すやり方を値渡しと言います.
さて,それでは以下の例をみてみてください.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def add_world(hello): hello += ' world' return hello h_str = 'hello' h_list = ['h', 'e', 'l', 'l', 'o'] output_str = add_world(h_str) output_list = add_world(h_list) print('output_str: {}'.format(output_str)) print('output_list: {}'.format(output_list)) print('h_str: {}'.format(h_str)) print('h_list: {}'.format(h_list)) |
|
1 2 3 4 |
output_str: hello world output_list: ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'] h_str: hello h_list: ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'] |
引数に’ world’を追加して返すという関数を作り,そこにstringsとlistsの二つをそれぞれ渡してみました.
結果はどちらにも’ world’が追加されているのはOKですが,もとのh_strとh_listをみると,h_strは’hello’のままなのに,h_listは’ world’の文字が追加されている状態になります.
この挙動の違いは,引数に渡しているオブジェクトがimmutableかmutableかの違いにあります.(mutableというのは’変わりやすい’, immutableは’不変の’と言う意味)
mutable: list, set, dict
immutable: int, float, bool, str, tuple
immutableのオブジェクトは後で値を変更することができないため,関数内で新しい値が代入されると,別の保管場所にその新しい値を保存し,そこを参照するようになります.
逆にmutableのオブジェクトではそのまま元の変数が変更されます.
h_strはStringsでimmutableなのに対し,h_listはListなのでmutableです.そのため, add_world() 内の hello に入った h_listが直接更新されています.
基本的な考え方としては,データ量が巨大になる可能性があるものはmutable,そうでなければimmutableと考えていいと思います.
immutableのオブジェクトを引数に渡して関数内でそれを更新する場合は,結局内部でコピーを作るので値渡しのような挙動になります.NumPyとかListsってたくさんの値を保持することが多いのでデータ量が巨大になりがちです.それをいちいちコピーしてたら大変なので参照渡しの挙動になると考えましょう.
以下はNumPy Arrayの例です. .copy() をしないと直接もとの変数を上書きしてしまうので超注意です.初心者がよくやるバグの原因です.以下の例をみてください.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def change_hundred(array): array[0] = 100 return array def change_hundred_copy(array): array_copy = array.copy() array_copy[0] = 100 return array_copy array_1 = np.arange(0, 4) array_2 = np.arange(0, 4) output_array = change_hundred(array_1) output_array_copy = change_hundred_copy(array_2) print('original array_1:\n', array_1) print('original array_2:\n', array_2) |
|
1 2 3 4 |
original array_1: [100 1 2 3] original array_2: [0 1 2 3] |
arrayをそのまま更新している関数(change_hundred)に対して,copyしてから更新している関数(change_hundred_copy)ではもとのarrayが更新されていないです.
関数内で直接arrayを更新する時は気をつけましょう.メモリに余裕があると思ったら .copy() して値渡しにすることを検討しましょう.
- np.zeros(shape)
こちらも頻出です.いわゆる零行列をつくります.要素が全て0のndarrayです. shapeをタプルで渡しましょう. np.zeros(4) など,タプルではなくintegerを入れるとその数文の一列の零行列ができます.( [0, 0, 0, 0] )
|
1 2 3 |
shape = (2, 3, 5) zeros = np.zeros(shape) print(zeros) |
|
1 2 3 4 5 6 7 |
[[[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]]] |
あらかじめndarrayの箱を確保したい時に使います.一旦零行列作ってから要素を変更していって新たな行列を作るイメージです.
- np.ones(shape)
np.zerosの「1」版です.全ての要素が「1」になります.以上.
|
1 2 3 4 5 6 |
shape = (2, 3, 5) ones_array_1 = np.ones(shape) ones_array_2 = np.ones(4) print(ones_array_1) print(ones_array_2) |
|
1 2 3 4 5 6 7 8 |
[[[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]] [[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]]] [1. 1. 1. 1.] |
- np.eye(N)
N x Nの単位行列を作ります.単位行列というのは対角成分が全て1となる正方行列です.
|
1 |
np.eye(3) |
|
1 2 3 |
array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]]) |
行列演算を自分で作る時に,単位行列が必要になるケースはよくあります.また, np.eye(N, M) とすると,N行M列の行列を作ることもできます.(滅多に使いませんが)
|
1 |
np.eye(3, 5) |
|
1 2 3 |
array([[1., 0., 0., 0., 0.], [0., 1., 0., 0., 0.], [0., 0., 1., 0., 0.]]) |
- np.random.rand()
0 ~ 1からランダムな数字で行列を作ることができます.引数を入れなければfloatが,引数の数によって返されるarrayの次元が変わります.
|
1 2 3 4 5 6 7 |
random_float = np.random.rand() random_1d = np.random.rand(3) random_2d = np.random.rand(3, 4) print('random_float: {}\n'.format(random_float)) print('random_1d: {}\n'.format(random_1d)) print('random_2d: {}\n'.format(random_2d)) |
|
1 2 3 4 5 6 7 |
random_float: 0.9218349229406412 random_1d: [0.26679042 0.0467733 0.78577218] random_2d: [[0.38787893 0.99595073 0.88157402 0.87572593] [0.38667271 0.23264086 0.34513122 0.04279471] [0.5219918 0.07765906 0.95201212 0.45909354]] |
データサイエンスでは乱数が必要になるケースは非常に多いです.たとえばあるデータ分布からランダムサンプリングするときなんかに使えます.
覚えておきましょう.
- np.random.randn()
|
1 2 3 4 5 6 7 |
random_float = np.random.randn() random_1d = np.random.randn(3) random_2d = np.random.randn(3, 4) print('random_float: {}\n'.format(random_float)) print('random_1d: {}\n'.format(random_1d)) print('random_2d: {}\n'.format(random_2d)) |
|
1 2 3 4 5 6 7 |
random_float: 1.560300224901678 random_1d: [-0.00151081 0.27836971 0.25211814] random_2d: [[ 0.15934305 -1.23794774 0.80006652 3.66460739] [ 0.8712341 0.4665787 -0.9481771 -0.42839369] [ 0.9801417 -0.57378352 -0.1091506 0.30167029]] |
- np.random.randint(low[, high] [, size])
これが,ランダム系で一番使うかもしれません.low以上hight未満のintegerからランダムに,指定したsizeのndarrayを返します.(sizeを指定しなかった場合はintegerを返す)
|
1 |
np.random.randint(10, 50, size=(2, 4, 3)) |
|
1 2 3 4 5 6 7 8 9 |
array([[[35, 41, 21], [24, 33, 15], [18, 34, 22], [37, 46, 47]], [[43, 48, 32], [14, 32, 30], [34, 16, 18], [47, 45, 45]]]) |
↑こんな感じで使えます.実際にランダム値を使う時って,ランダムなindexが必要だったりと,0 ~ 1の間のランダム値よりも指定した範囲のintegerのランダム値を使うことの方が多いです.データサイエンス頻出です.
- .reshape(shape)
超超超頻出です.あるndarrayのshapeを任意のshapeに変換(reshape)します.以下の例をみてください.
|
1 2 3 4 5 6 7 |
array = np.arange(0, 10) print('array:\n{}'.format(array)) new_shape = (2, 5) reshaped_array = array.reshape(new_shape) print('reshaped array:\n{} '.format(reshaped_array)) print("reshaped array's is:\n{} ".format(reshaped_array.shape)) print('original array is NOT changed:\n{}'.format(array)) |
|
1 2 3 4 5 6 7 8 9 |
array: [0 1 2 3 4 5 6 7 8 9] reshaped array: [[0 1 2 3 4] [5 6 7 8 9]] reshaped array's is: (2, 5) original array is NOT changed: [0 1 2 3 4 5 6 7 8 9] |
.reshape()によりもとのarrayは更新されません.新しいarrayが返されることに注意しましょう.
また,新しいshapeはarrayの要素数と合ってないといけません.以下はエラーになります.
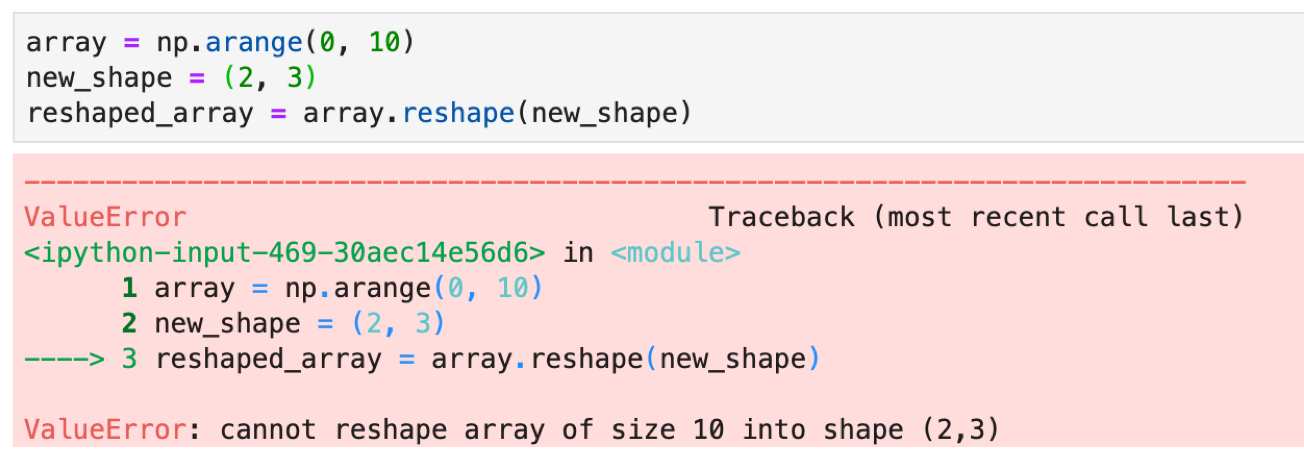
要素数が10個のarrayに対しshape=(2, 3)の行列は要素数が6個なので足りませんね.
.reshape()はとくに画像を扱っているとかなりの頻度で使います.行列演算をするときにも,行列の数を合わせるのに使ったりします.
まとめ
色々紹介しましたが,どれも重要で結構な頻度で出てくると思います.
しかし全部を覚えるのは大変なので,必要に応じてググったりこのページに戻ってきて,その都度覚えるようにしましょう.
- np.arange([start,] stop[, step]) : start以上stop未満の値をstepずつ増加させた値のarrayを生成
- np.linspace(start, stop, num=50) : start以上stop未満の値を均等にnum個等分した値のarrayを生成
- .copy() : NumPy arrayをコピー
- np.zeros(shape) : 要素が全て0のndarrayを生成
- np.ones(shape) : 要素が全て1のndarrayを生成
- np.eye(N) : N x Nの単位行列を生成
- np.random.rand() : 0 ~ 1からランダムな数字で行列を生成
- np.random.randn() : 標準正規分布から値をとって行列を生成
- np.random.randint(low[, hight] [, size]) : low以上hight未満のintegerからランダムに,指定したsizeのndarrayを生成
- .reshape(shape) : ndarrayのshapeを任意のshapeに変換
試しに自分で色々なndarrayを作ってみてください!
次回もまだNumPyが続きます.それでは!
↓次回記事書きました.NumPyの色々な関数を使ってみます!