こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第24回です(講座の目次はこちら).今回からSeabornというplot用ライブラリを紹介します!!
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
前回まで扱っていたmatplotlibは,Pythonのplotの超基本となるライブラリなんですが,デフォルトで描画される図が結構ダサいんですよね
Seabornを使えば↓のようなお洒落なグラフが簡単に作れます!
うぅ...どれも美しすぎてつい見とれてしまいますね...
いかに美しくわかりやすいグラフを描画するかがデータサイエンティストの腕の見せ所ですが,Seabornを使えばめちゃくちゃ簡単に上のようなセクシーなグラフが描けちゃいます!
基本はSeabornを使えるようにしましょう.matplotlibも時々使いますが,わたしはほとんどのケースでSeabornを使ってますし,私のチームのメンバーもみんなSeabornを愛用してます.
これから数回にわけて,いろんなグラフの作り方を紹介するのでぜひ読んでみてください!
目次
Seabornをimportする
Seabornも,他のライブラリと同様Anacondaパッケージに入っています.第一回の記事に従って環境構築した人は,特にインストールは不要です.(ほんと,Anaconda最強です.)
もし,別途インストールする必要がある人は $pip install seaborn でインストールすればOK
では,早速Seabornをimportします.numpy は np, pandas は pd, matplotlib は pltでimportしましたが,Seabornは sns で importするのが習わしです.理由は聞かないでください.
|
1 2 |
import seaborn as sns %matplotlib inline |
( %matplotlib inline については第20回で紹介したおまじないですね)
これで準備完了です.snsを使っていろんな関数を呼び出してplotしていきます.
一番頻出のsns.distplot()
ヒストグラムです.一番使います.とりあえず,あるデータの分布がみたい時にこれを呼びます.(ヒストグラムについては前回の記事を参考にしてください.)
追記)
.distplot() は,新しいバージョンのseabornではdeprecated(つまり将来なくなる関数)とされています(公式ドキュメント参照).
もし
.distplot() したときにdeprecatedのwarningがでる場合は,代わりに
.displot() もしくは
.histplot() を使ってください.
今回もタイタニックのデータを例にplotしてみましょう!タイタニックデータについては第11回を参照してください.
|
1 2 3 4 |
import pandas as pd df = pd.read_csv('train.csv') df = df.dropna(subset=['Age']) sns.distplot(df['Age']) |
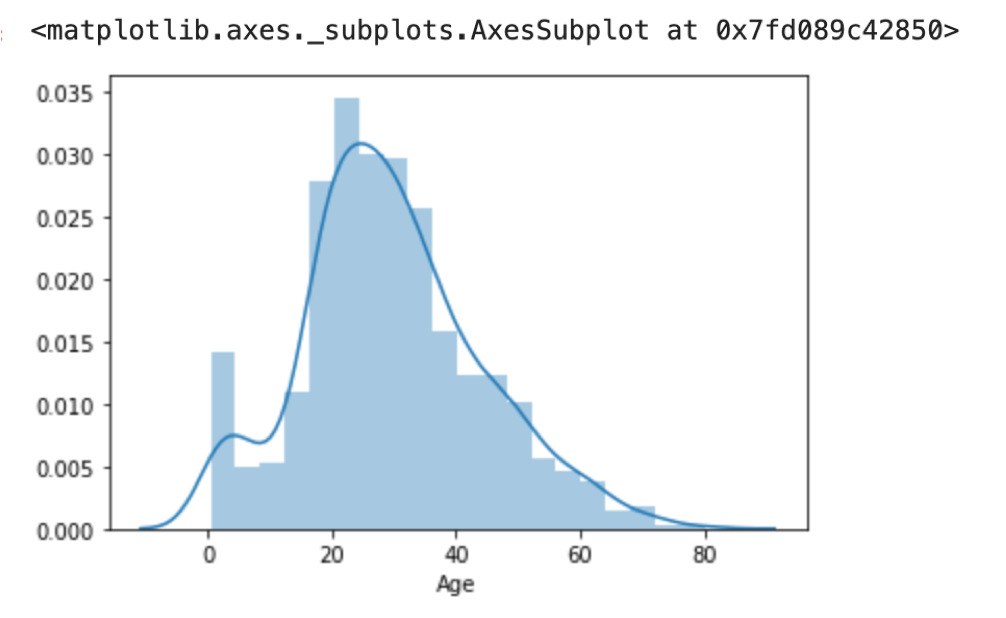
線がひかれていますが,これは,KDE(Kernel Density Estimation)(カーネル密度推定)という手法でPDF(Probability Density Function)(確率密度関数)を推定したものです.KDEもPDFもデータサイエンスでよく出てくる統計用語ですが,ここでは分布に応じてそれっぽく線を引いているとでも思えばOKです.今後の統計講座で詳しく解説します.kde=Falseを指定すると消えます.
...え?あんまりかっこよくない?
という人は sns.set() 関数でSeabornのStyleをセットしましょう.引数で色々指定できますが,今回はデフォルトで実行します. sns.set() については第27回で説明します.
|
1 2 |
sns.set() sns.distplot(df['Age']) |
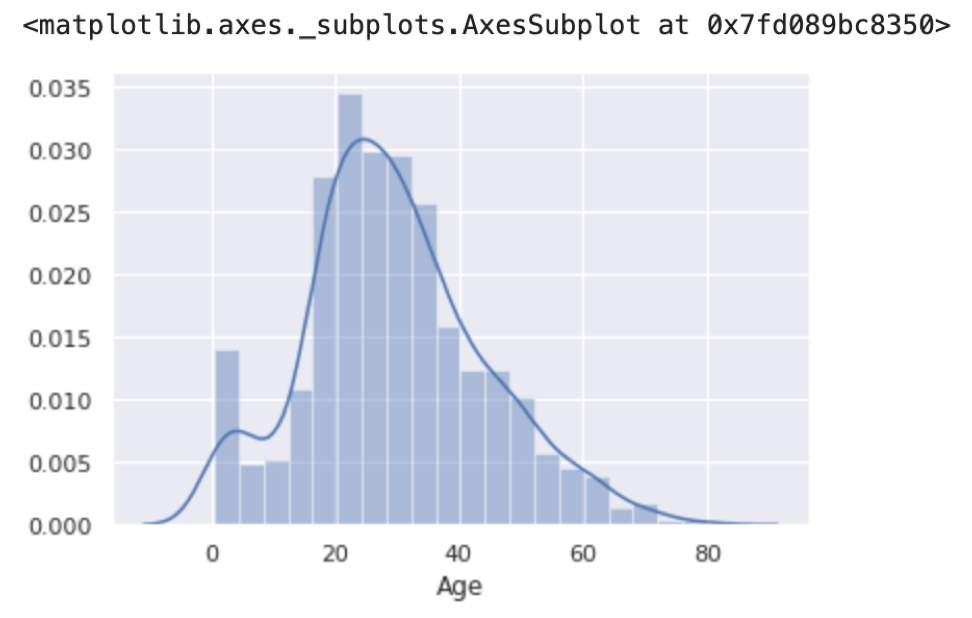
こんな感じに変わると思います.こっちの方が断然かっこいい気がします.
前回のplt.hist()同様,bins引数を指定することでbin幅を変えることができます.試してみてください.
sns.jointplot()で2変数の分布をみる
先の例ではAgeの1変数のみの分布をみましたが,前回紹介したplt.scatterのような2変数の分布をみるにはsns.jointplot()が便利です.散布図に加えてそれぞれの変数のヒストグラムを脇に表示してくれます.
使い方は,data引数にDataFrameを入れて,x, yにそれぞれカラム名を入れます.
|
1 |
sns.jointplot(x='Age', y='Fare', data=df) |
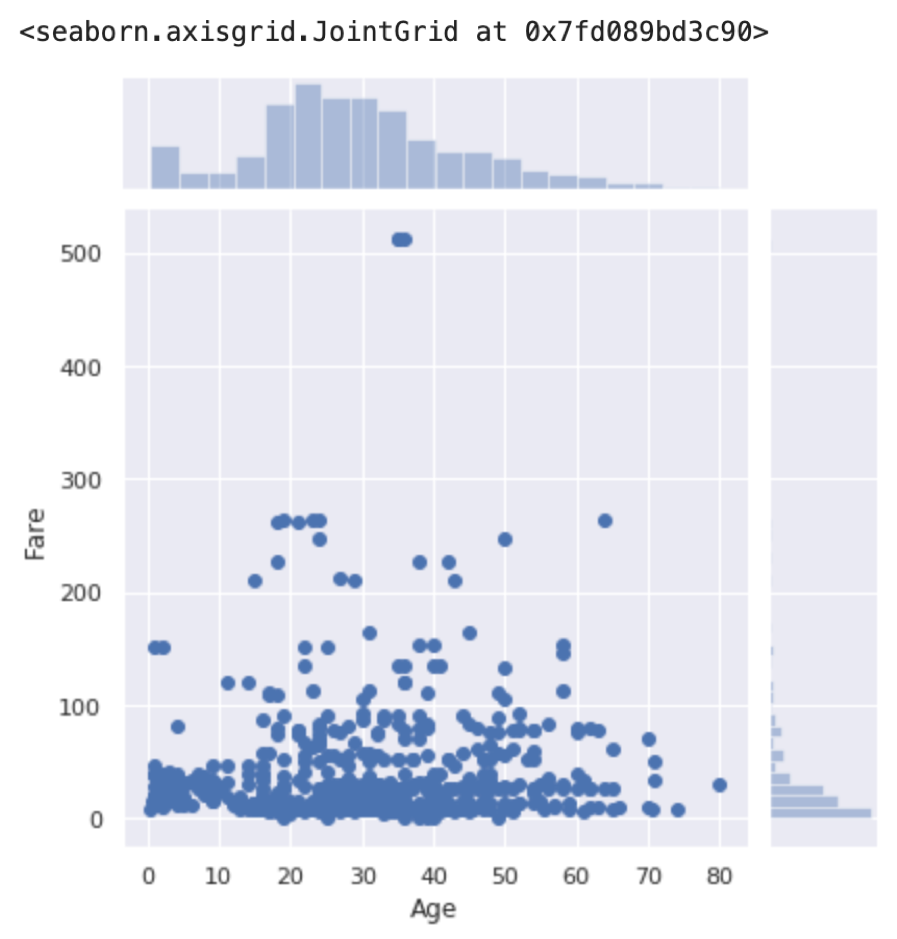
かっこよさげ!
前回の記事ではplotの重なりがわかりにくかったのでalphaを指定して透明にしました.ここでは図の種類をkind引数で変えてみます.デフォルトだと上図の通りscatterになってます.kind=’hex’を指定すると,plotの重なりがわかりやすくなって便利です.(もちろん,alphaを指定することも可能です.試してみてください.)
|
1 |
sns.jointplot(x='Age', y='Fare', data=df, kind='hex') |
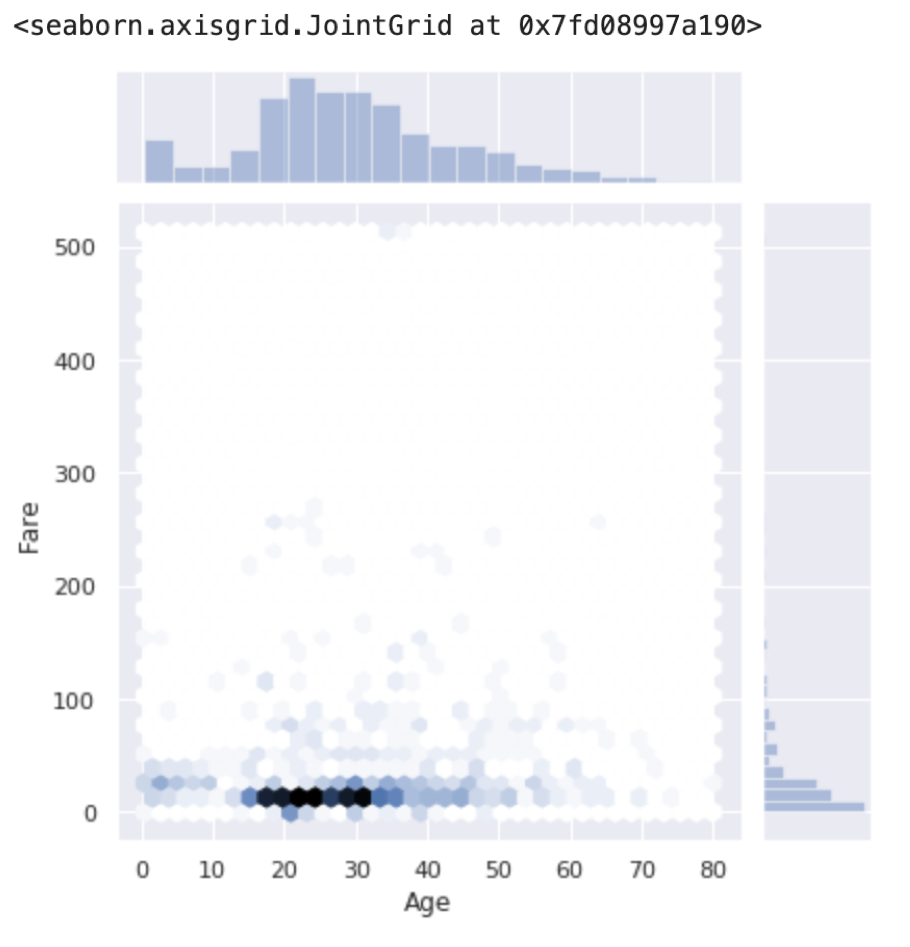
Fareの外れ値のせいであんまりいい図ではないですが笑
他の種類も試してみてください.(Shift+Tabでリファレンスを参照ください)
(重要)sns.pairplot()で複数のカラムの分布を一発で表示
Seabornでもっとも重要な関数だと思います. sns.jointplot() では2変数の関係をみることができましたが,多くのカラム情報があるデータに対して,全ての2変数組み合わせ(pair)の散布図を見たい場合がよくあります.
例えばタイタニックでも,AgeとFareに限らず他のカラムのペアを確認したくなると思います.(タイタニックは数値カラムがAgeとFareしかないので例としてはいまいちですがw)
そんな時に sns.pairplot() が便利です.とにかく全てのペアのplotを表示してくれます.
|
1 |
sns.pairplot(df) |
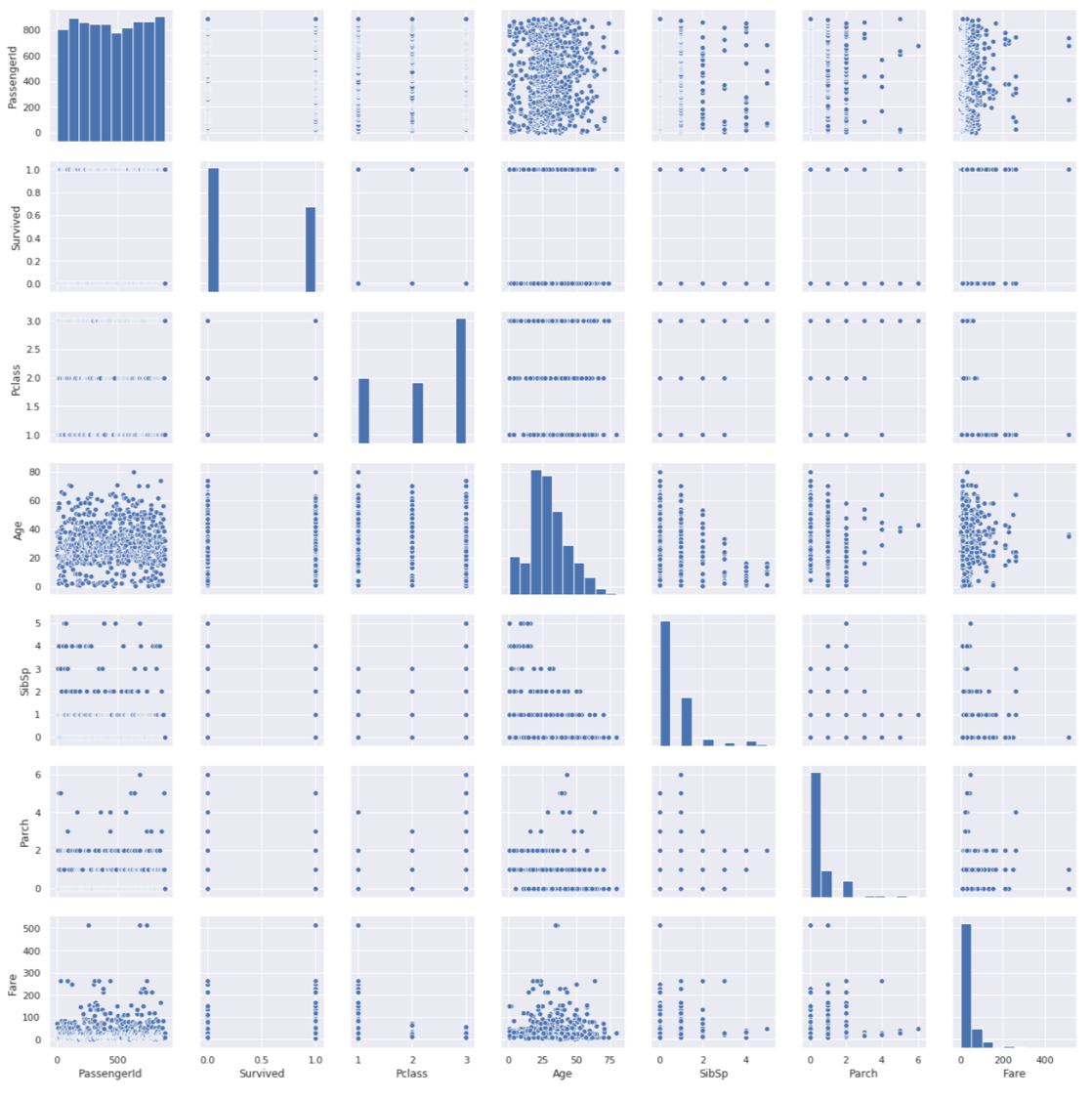
・・・いきなりこれみてもなにがなんだかって感じですよね笑
縦軸と横軸にカラムが並んでいて,そのカラム間の散布図を表示してます.
同じカラムが交差するところには,そのカラムのヒストグラムが表示されます.
つまり,例えば縦軸Fare,横軸Ageの散布図をみると先ほどのjointplotの例で出したplotと同じですし,縦軸Age, 横軸Ageのグラフをみると,Ageのヒストグラムになってます.(bin幅が違うので先の例とはあまり似てませんが,)
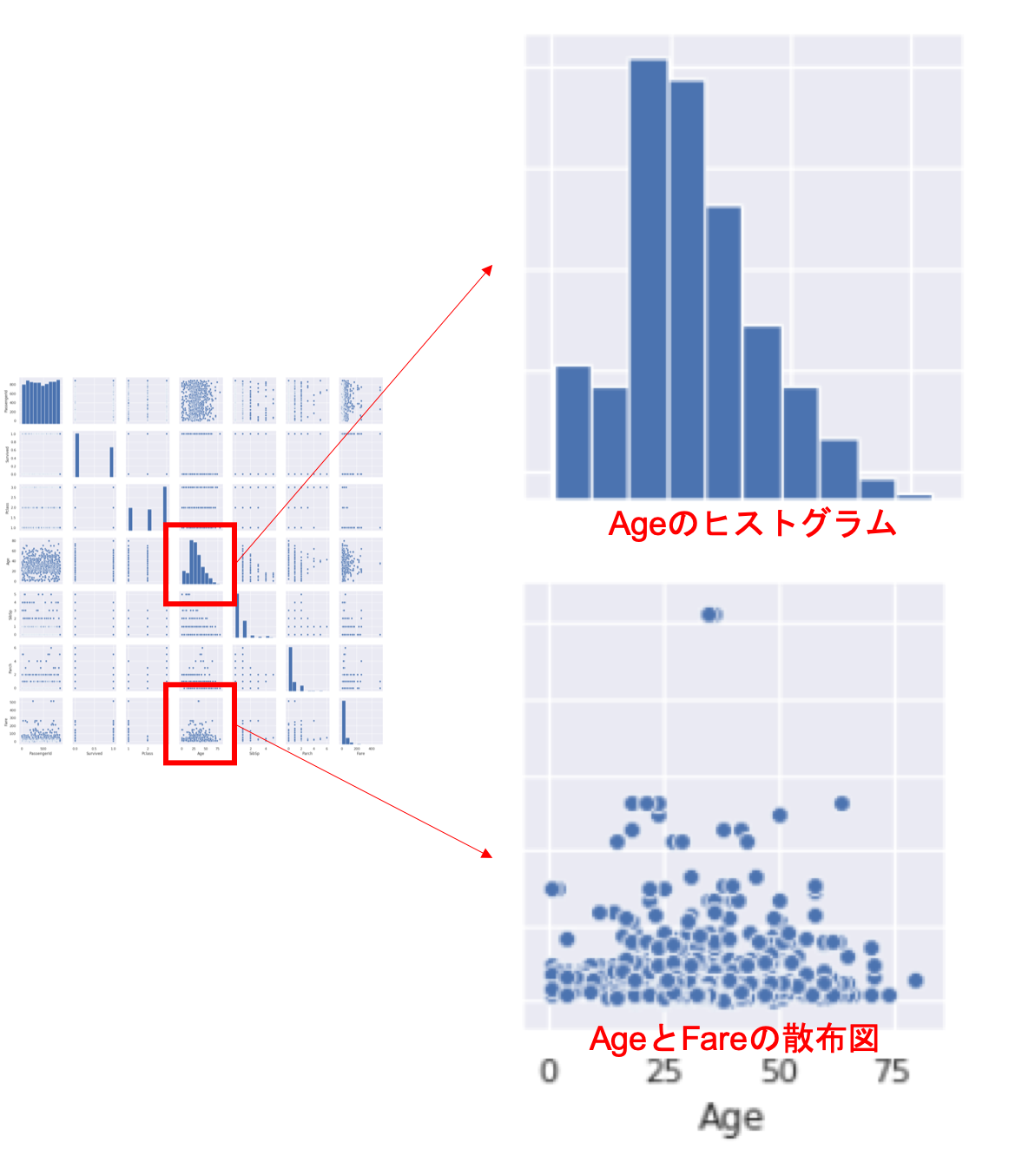
なんとなくわかりましたか?このpairplotはめちゃくちゃ使うので必ず覚えておきましょう.
このpairplotではhue引数を使ってデータの色分けをすることが多いです.
こんな感じです↓.hue引数に’Survived’を指定して,生死の分布をそれぞれのカラム毎に確認することができます.
|
1 |
sns.pairplot(df, hue='Survived', kind='scatter', plot_kws={'alpha':0.5}) |
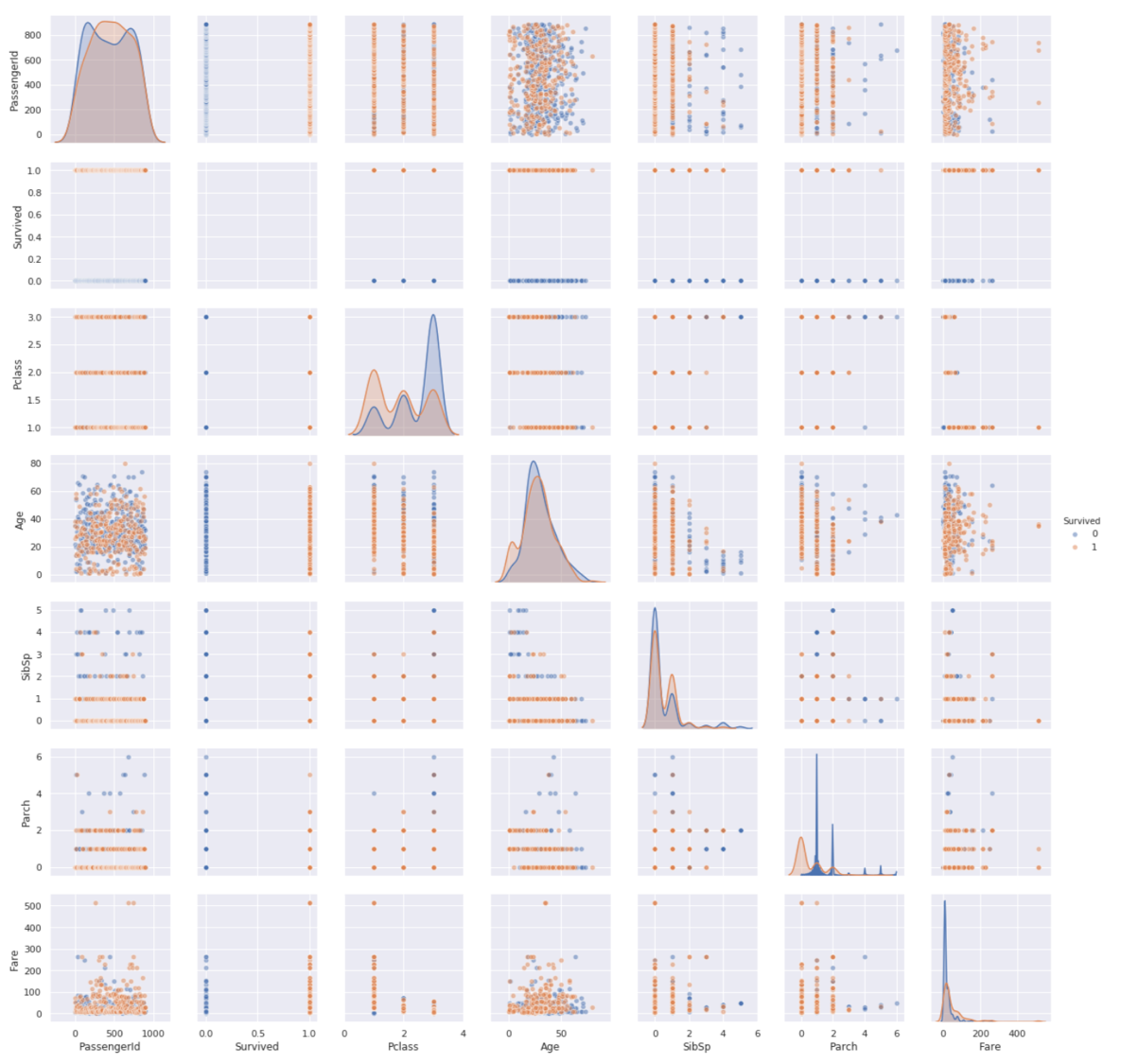
重なっている部分がわかりにくいので,alphaパラメータを指定しています.
前回紹介した装飾パラメータをpariplotで使いたい場合は,plot_kws(kwsはkeywords)引数にパラメータ名をkey,値をvalueにしたdictionaryを入れます.
pairplotでalphaを指定したい時がよくあるので覚えておきましょう.
また,タイタニックデータだとPassengerIdも数値として入っていますが.実際には数値情報ではない(ただのIDなので・・・)のでpairplot()には不要ですよね.
必要なカラムだけ抽出してpairplot()に入れるのが一般的な使い方です.
|
1 |
sns.pairplot(df[['Age', 'Fare', 'Pclass', 'Survived']], hue='Survived', plot_kws={'alpha':0.5}) |

まとめ
今回はSeabornを使ったplotを紹介しました.実業務では,ほとんどのケースに対してSeabornを使ってplotすることになると思います.なので,plotライブラリのど本命って感じですね.
- import seaborn as sns でSeabornをimportする
- sns.set()でSeabornのStyleを設定
- sns.distplot(Series)で,ヒストグラムをplot
- sns.jointplot(x=’カラム1′, y=’カラム2′, data=df)で,二つのカラム間の散布図などをplotする
- sns.pairplot(df)で,全てのカラムの組み合わせ(pair)をplotする
慣れてくると,pd.read_csv -> df.head() -> sns.pairplot(df)の流れでまずデータの分布をざっと確認するようになると思います.
なのでpairplotは超重要です.覚えておきましょう!
それでは!
追記)次回の記事書きました.次回はSeabornを使ってカテゴリー別にある値をグラフで表すCategorical Plotについて触れていきます.boxplotやswarmplotなど,重要なplotがでてくるので押さえておきましょう!
データサイエンスのためのPython入門25〜Seabornで簡単にお洒落な図を描画する【barplot, boxplot, swarmplot等】〜