こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第29回です(講座の目次はこちら).今回はデータの処理によく使うglob関数を紹介したいと思います.
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
globは「引数のパターンにマッチするファイルパスをリストで取得する」関数です.
本当によく使うんですが,入門時に習わないとそれ以降習う機会が少ないモジュールです.(NumPyやPandasなどのくくりに入らないですからね!)
使い方はすごく簡単なのでやってみましょう!
目次
データ準備
今回は大量の画像データを処理してみたいと思います.
サンプルデータとして,Kaggleの「Diabetic Retinopathyデータセット」を使います.もし現在このデータセットが利用できない場合は,なんでもいいのでいくつかのフォルダの中にいくつかの画像ファイルを入れたデータを用意してください.
トップページの「Download」をクリックするとデータをダウンロードできます.Kaggleに登録していない人は第11回を参考に登録してください.
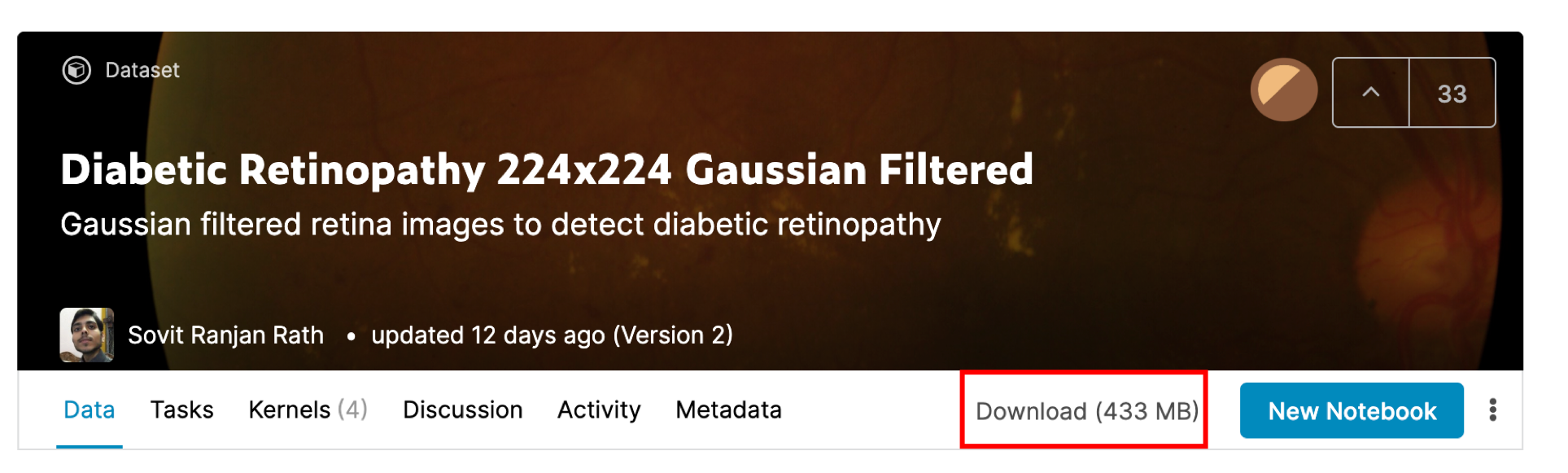
Downloadすると以下のようなフォルダ構造になっており,それぞれのフォルダにpreprocessされた眼底写真が保存されています.トップフォルダをコンテナからアクセスできる場所に移しておきましょう.私の場合は~/Deskltop/ds_ptyhon/です.第一回に従った人は同じだと思います.docker run時の-vオプションに指定したフォルダがそれです.

本データセットはKaggleのAPTOS 2019 Blindness Detectionコンペのデータを処理した画像データセットです.
このコンペは,眼底写真からDiabetic Retinopathy(糖尿病網膜症)をDetectする画像認識アルゴリズムの精度を競います.
糖尿病網膜症というのは,糖尿病患者が患う目の疾患で,視力の低下や失明になる恐れがある非常に怖い病気です.
また,眼底写真というのは専用の機械で網膜の写真をとった画像です.通常,散瞳して撮ります.
本データセットにはその眼底写真に処理をした画像がたくさん入っています.
医用画像は通常撮影機器や撮影条件によって画像が大きく変わってしまうものが多いですが,眼底写真は医用画像のなかで特に標準化がされており,機器や撮影条件によらず一定の品質を保ちます.
そのため,少なくない企業が眼底写真を使ったAI機器の開発に乗り出しています.
IDxという米国のスタートアップが,すでに眼底写真から糖尿病網膜症をDetectするAI医療機器でFDA認可を取得しています.
*今回の記事ではこのデータセットを使ってファイルパスを取得するだけです.別に眼底写真である必要はありません.
globを使って対象のファイルパスをリスト化する
glob関数を使って,パターンにマッチしたファイルパスのリストを作る事ができます.今回のように大量のファイルを扱う際によく使います.ファイルパスのリストに対して,例えばforループでなにか処理したりします.
glob関数はglobモジュールに入っています.以下のようにして取り出しましょう.( import globして glob.glob() と使う人も多いです)
|
1 |
from glob import glob |
glob() に,取り出したいファイルパスのパターンを指定します.
よく使うのが「 * 」です.これは0文字以上の任意の文字列を意味します.いわゆるワイルドカードってやつです.
例えば’hello wo*ld’は,’hello world’も’hello worrrrrld’も’hello wold’も’hello wodhfidahfuvrld’もマッチします.
他にも1文字だけであれば「 ? 」を使ったり,「 [] 」(square brackets)に文字を入れると,その文字のグループがマッチします.よく使うのは数字です. [0-9] と指定すると数字一文字をマッチします.
それでは,例をみてみましょう!
|
1 2 |
from glob import glob glob('gaussian_filtered_images/Mild/*') |
Mildフォルダ内のファイルパスがズラーっとリストに格納され,表示されるかと思います.
|
1 |
glob('gaussian_filtered_images/Mild/*[0-9].png') |
このようにパターンを指定すると,Mildフォルダ配下のファイル名の最後が数字で終わっているpngファイルのファイルパスのリストを取得できます.
なんとなくわかりました?ほとんど * (アスタリスク)しか使わないと思いますが,他のパターンを知りたい人はひとまずwikiで学べると思いますの参考までに.この手のものは一つ一つ覚えるのではなく,都度調べればOKです.
(実用例)globを使って,ファイルパスリストからDataFrameを作る
この「glob」の実用例を一つ紹介します.このように大量のファイルを扱う際にまずやりたいのが「DataFrameを作ってファイルの情報を管理したい」というもの.この流れは本当によく出てきます.
今回の画像ファイルパスの情報で’filepath’, ‘type’, ‘extension’のカラムを持ったDataFrameを作りましょう
それぞれのリストを作ってDataFrameにすればOKです.
まず,それぞれのリストは以下のように作れます.
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np # 全ての.pngファイルパスのリストを取得 all_png_list = glob('gaussian_filtered_images/*/*.png') # 内包表記を使ってフォルダ名のリストを作成 type_list = [p.split('/')[1] for p in all_png_list] # フォルダ名が取れているか確認 print(np.unique(type_list)) # 同様に拡張子のリストを作成 extension_list = [p.split('.')[-1] for p in all_png_list] # 拡張子が取れているか確認 print(np.unique(extension_list)) |
...少しややこしいですね.
まず1つ目の all_png_list = glob('gaussian_filtered_images/*/*.png') はいいですね.先ほどの例で説明した通りです.
2つ目の type_list = [p.split('/')[1] for p in all_png_list]は,まずリストの内包表記を使っています.内包表記については第4回で解説してます.
まず内包表記の内側 for p in all_png_list をみましょう. p には all_png_list の各要素が入ります.つまり,それぞれのpngファイルのファイルパスです.その p に対して.split()関数で1階層上のフォルダ名を取り出しています.
例えば p には 'gaussian_filtered_images/Mild/2d7666b8884f.png' のような文字列が入ります.これに対して p.split('/') をすると ['gaussian_filtered_images', 'Mild', '2d7666b8884f.png'] というリストが取得できます.その2つ目の要素をindex=1で取り出しているのです.そうすることでフォルダ名を取得できsdます.
split関数については第5回でも少し説明しているので参照ください.
ちょっとややこしいですかね笑
今の説明をコードにするとこんな感じです↓
|
1 2 3 4 5 |
p = all_png_list[0] print(p) split_list = p.split('/') print(split_list) print(split_list[1]) |
ステップバイステップでコードを書いていくとわかってくると思います.ぜひ自分で一つ一つ変数を作って実装してみてください.
3つ目の extension_list = [p.split('.')[-1] for p in all_png_list] も同じ要領です.こちらも自分で一つ一つコードを書いて試してみてください.
さて,これらのリストでDataFrameを作ります.DataFrameの作り方は第11回で紹介しましたが,今回はdictionaryのkeyにカラム名,valueにそのカラムのリストを指定して作ります.
|
1 2 3 |
import pandas as pd df = pd.DataFrame({'filepath': all_png_list, 'type': type_list, 'extension': extension_list}) df.head() |

これでフォルダ構造のDataFrameを作ることができました.
この一連の流れ,データサイエンスではめちゃくちゃ頻出です.
当然ですが大量のファイルを処理するので,その大量のファイルをどこかのフォルダに入れて,それらのメタ情報をこのようにDataFrameで持っておくと重宝します.
例えばフォルダ別にいくつのファイルが入っているか確認したければ
|
1 |
df['type'].value_counts() |
|
1 2 3 4 5 6 |
No_DR 1805 Moderate 999 Mild 370 Proliferate_DR 295 Severe 193 Name: type_list, dtype: int64 |
.value_counts() 関数 で一発!(第17回参照)
Seabornを使ってグラフも簡単に書けちゃいます.
|
1 2 3 4 |
import seaborn as sns %matplotlib inline sns.countplot(x='type', data=df) |
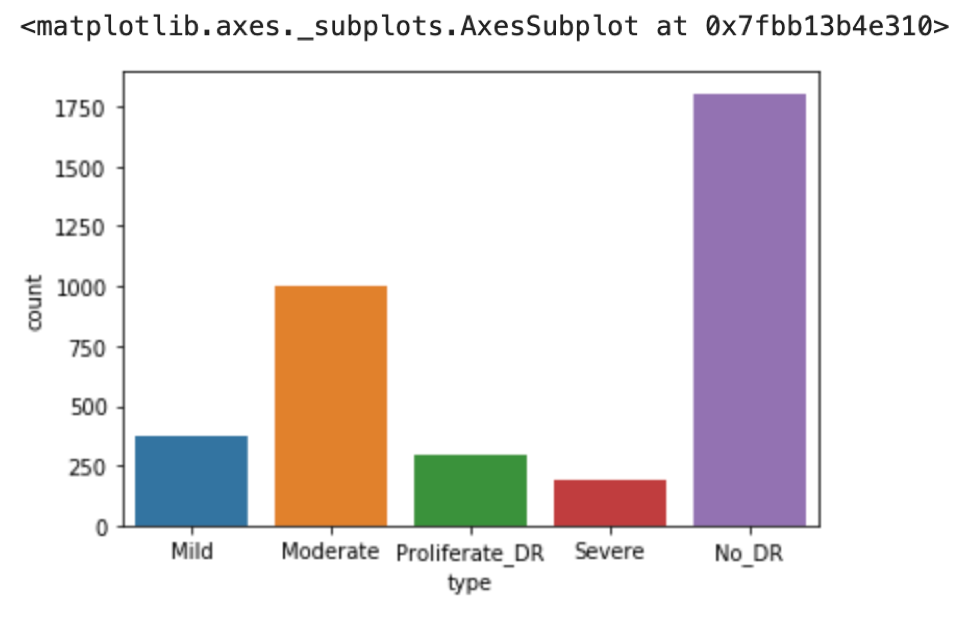
Python素晴らしいでしょ??
こんなに簡単にグラフも書けちゃうし表も作れちゃうんです.
まとめ
今回はglobの紹介をしましたが,globを使ってDataFrameを作ってグラフを表示してと,,かなり実践的になってきました.
これらができるのも,今までの講座で学んだことを積み上げているからです.積み上げ大事
一回一回の記事で,できることが少しづつ増えていき,気づいたらかなり自由にPythonを使えているのではないでしょうか?
本講座で紹介しているツールは,米国の最先端で働く多くのデータサイエンティストが使っているツールです.私も使っています.
完全に業界標準となっているので,これらを学ぶことは2020年現在絶対に間違ってないと私は思います.
今回学んだのは以下です.
- from glob import glob で glob() 関数を使う.( import glob して, glob.glob() で関数を使う人も多いです.)
- glob() のなかにパターンを入れて,マッチしたファイルパスをリストとして受け取る.
- よく使うのが' * ‘(アスタリスク).0文字以上のあらゆる文字列がマッチされる
データサイエンスにおいて,リストの内包表記を使うのは概ね今回のようなケースです.今回のようにglob()でファイルパスをリストで取得してそれをDataFrameにする流れは頻出なので是非なんどか自分で作ってみてください!
また,今回は文字列を直接操作してフォルダ名を取得したりファイル名を取得しましたが,pathはOSによって変わったり,スラッシュ( / )をつけ忘れたりして文字列操作だとバグの元になる可能性があります.第31回でosモジュールとpathlibモジュールを使ってより安全にpath操作をする方法を紹介しているので,製品開発などで使う時はこちらを使うといいと思います.
それでは!
次回はforループでプログレスバーを表示する関数「tqdm」を紹介します!