こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第30回です(講座の目次はこちら).今回は大量のデータを処理する際にプログレスバーを表示するtqdmというモジュールについて解説します!
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
tqdm… 変な名前ですね.どうでもいいですが,アラビア語のtaqaddum (تقدّم) (progressの意味)から由来されているらしいです.
以下のgifがtqdmが何者であるのかを理解するのにわかりやすいので貼っておきます.(元ネタはGithubから)
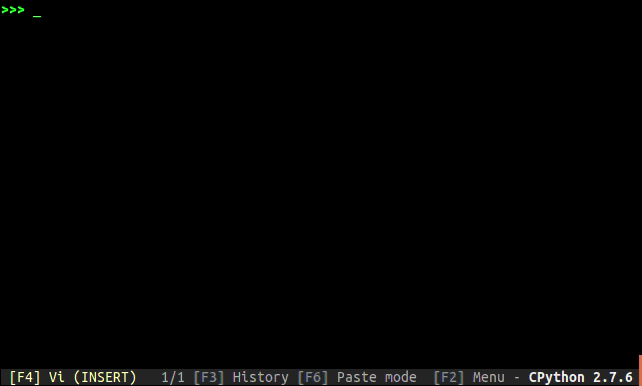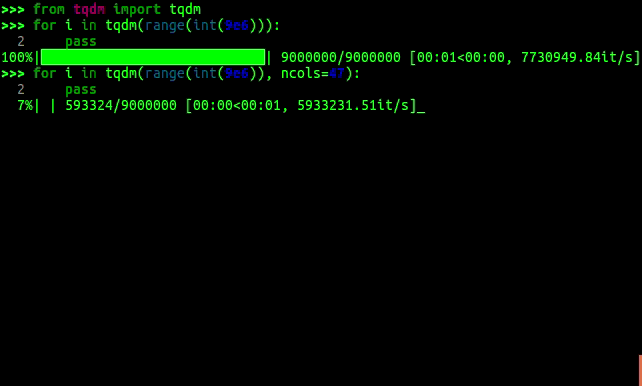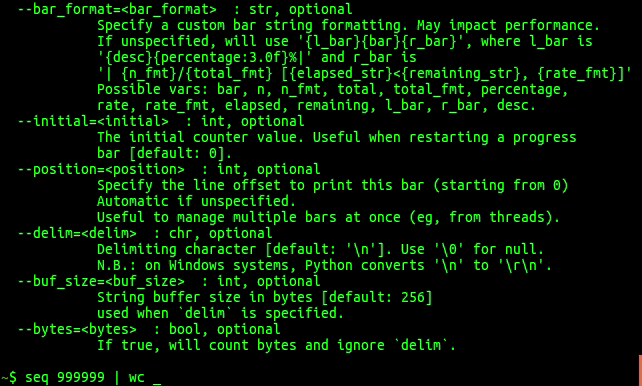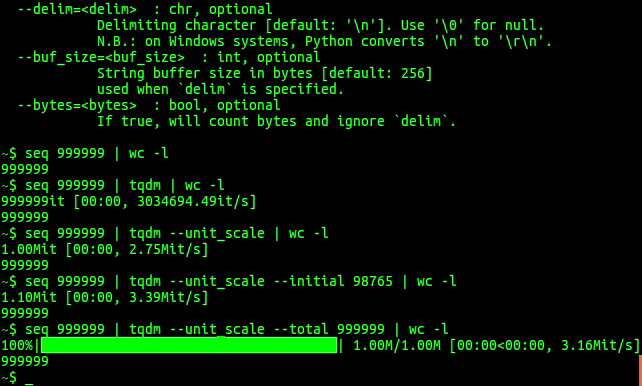 from tqdm import tqdm でtqdm関数をインポートして,for文と組み合わせて使うことでプログレスバーが表示されているのがわかると思います.
from tqdm import tqdm でtqdm関数をインポートして,for文と組み合わせて使うことでプログレスバーが表示されているのがわかると思います.
これ,めちゃくちゃ便利です.データサイエンティストが業務で処理するデータって,数千件,時には数万件になるので処理が終わるのに時間がかかります.
特に画像データを扱っていると,forループを終えるのに数時間かかることだってあります.
そんなときに「あとどれくらいで終わるのか」がわかると心が安定しますよね?tqdmを使わないで巨大forループを回すことは,好きな子へのメールがちゃんと届いているかもわからない状態でその返信を待ち続けるようなものです.
苦痛でしょ!
てことで今回は超便利なtqdmの使い方を超わかりやすく説明します!
目次
tqdmをインストール&インポート
tqdmはAnacondaに入っているので特にインストールする必要はありません.別途インストールが必要な場合は $pip install tqdm でインストールが可能です.
インポートは先ほど説明したとおり, from tqdm import tqdm でインポートしましょう.(前回紹介したglobと違ってimport tqdmでインポートしtqdm.tqdmと使う人はあまり見ません)
|
1 |
from tqdm import tqdm |
tqdmの基本的な使い方
tqdmは基本的にfor文と組み合わせて使います.for文については第4回で説明しているので,アヤシイ人は見てね!
まずノーマルなfor文は以下のような感じですよね?
|
1 2 3 4 |
sum = 0 for i in range(0, 10000000): sum +=i print(sum) |
|
1 |
49999995000000 |
実行すると数秒かかると思います.
tqdmを使ってプログレスバーを表示させましょう!
一番簡単なのは上の例のfor文のrange(0, 10000000)の部分をtqdm()に入れるだけです.(range()のようにfor文に使ってイテレーションできるものをPythonではイテレータと呼びます.)
|
1 2 3 4 |
sum = 0 for i in tqdm(range(0, 10000000)): sum += i print(sum) |
![]()
するとプログレスバーと時間が表示されると思います.
めちゃくちゃ簡単ですよね!
tqdmを使うことで各イテレージョンの処理が遅くなり,結果時間が余計にかかります.ただ,大抵中の処理が重い場合に使うので,普通はそこまで影響はないです.
total引数を使って,データ数を表示する
使い方によって,データ数が表示されないケースがあります.よくあるのが,DataFrameのイテレーションに使うときです.total引数に処理するデータの総数を入れることで,解決できます.
前回使った眼底写真のデータを使ってみましょう.復習だと思って自分で同じDataFrameを作ってみるといいかも
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np import pandas as pd from glob import glob # 全ての.pngファイルパスのリストを取得 all_png_list = glob('gaussian_filtered_images/*/*.png') # 内包表記を使ってフォルダ名のリストを作成 type_list = [p.split('/')[1] for p in all_png_list] # 同様に拡張子のリストを作成 extension_list = [p.split('.')[-1] for p in all_png_list] df = pd.DataFrame({'filepath': all_png_list, 'type': type_list, 'extension': extension_list}) df.head() |

このDataFrameに対して,ループ処理を書いてみます.特にやりたいことはないので,何も処理をしない’pass’を使います.
|
1 2 |
for idx, row in tqdm(df.iterrows()): pass |

tqdmはデフォルトではDataFrameの全行数を取得してくれないので,データ数がわかりません.これだと,プログレスバーは表示されません.
この場合は,total引数にlen(df)を指定します.
|
1 2 |
for idx, row in tqdm(df.iterrows(), total=len(df)): pass |

これで正しくプログレスバーが表示されます.
他にも色々と引数を指定することができますが(先のgif参照),私はあまり使わないです.本記事で紹介している内容でほとんど問題ないと思います.
*今回の例のように一行で表示されず数行に分けてプログレスバーが表示されるケースがありますが,原因はよくわかってません.誰かご存知のかたいらっしゃいましたら教えてください.
頻出例:データIO処理でよく使う
このtqdmは特に,データを読み込んで処理して保存するようなIO処理でよく使います.
今回は例の眼底写真をnpyで保存する処理を書いてみましょう!pngデータをnpyデータで保存する処理は深層学習でよく使います.多くの深層学習のフレームワークは学習データとしてnpyデータを使うからです.
全体のコードは以下のようになります.今回やりたい事は「pngファイルを.npy形式のデータにして,それらを全て同じフォルダに保存する」です.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import cv2 # NumPy Arrayをsaveするフォルダ save_base_path = 'gaussian_filtered_nparrays/' for p in tqdm(glob('gaussian_filtered_images/*/*.png')): #pngデータをopencvでロード im = cv2.imread(p) #pngのファイル名をそのまま.npyファイルのファイル名にする file_name = p.split('/')[-1].split('.png')[0] save_path = save_base_path + file_name #全てのnpyファイルを同じフォルダに格納 np.save(save_path, im) |
このコードを実行する前に save_base_path に指定したgaussian_filtered_nparraysフォルダを作成しましょう.(次回の記事で,Pythonでフォルダを作成する方法を紹介しています.)
特に説明は不要かと思いますが,cv2.imread()は第28回を,.split()については第5回を,np.save()については第9回を,glob()については前回を参照してください.今までの積み上げでいろんな事ができるようになってますね〜〜
本コードは10分以上かかるかもしれません.途中でとめてもいいですし,glob()の後に[:10]のように要素数を指定してもOKです.
まとめ
- tqdmを使う事でループ処理にプログレスバーを表示できる
- from tqdm import tqdmで tqdmをインポート
- for i in tqdm(list)のように,tqdmにイテレータを入れる
- プログレスバーが表示されない場合はtotal引数で総データ数を指定する
tqdmも,独学ではなかなか出会わない関数かもしれません.
データサイエンスでは大量のデータを解析するので,プログレスバーは必須です.なるべく使う癖をつけましょう.
自分のコードを見ると,ほとんどのforループでtqdmを使っています.それくらい頻出です.簡単に使えるので是非使ってみてください.
それでは!
次回はより安全にpathを操作したり,フォルダを作ったりする方法を紹介します.
データサイエンスのためのPython入門31〜osモジュールとpathlibモジュールを使って安全にPath操作をする〜