







こんにちは,米国データサイエンティストのかめ(@usdatascientist)です
データサイエンスのためのPython入門第11回目です(講座の目次はこちら).前回に引き続き,今回もPandasを使っていきます.(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
今回はデータサイエンスのPythonでもっとも重要なデータ構造の一つであるDataFrameを扱っていきます.
前回の記事でも紹介したDataFrameですが,これ,本当に重要でめちゃくちゃ出てきます.私はリアルに毎日使っているものなので,今回の記事でちゃんと使えるようにしましょう!何も難しいことはありません.超簡単に表形式のデータを扱えちゃいます.
今回はDataFrameを以下の三つの方法で作ってみようと思います.
- ndarrayから作る
- dictionaryから作る
- ファイルから読み込む
DataFrameの作り方
- ndarrayから作る
それでは,早速DataFrameを作ってみましょう.DataFrameは表形式のデータ構造です.作ってみたらその意味がわかると思います. pd.DataFrame() で作ってみましょう.
新しい関数を使うときは,Jupyterで関数名を打ったあとにshift+tabを押してリファレンスをみてどんな引数をとるか確認するといいでしょう.
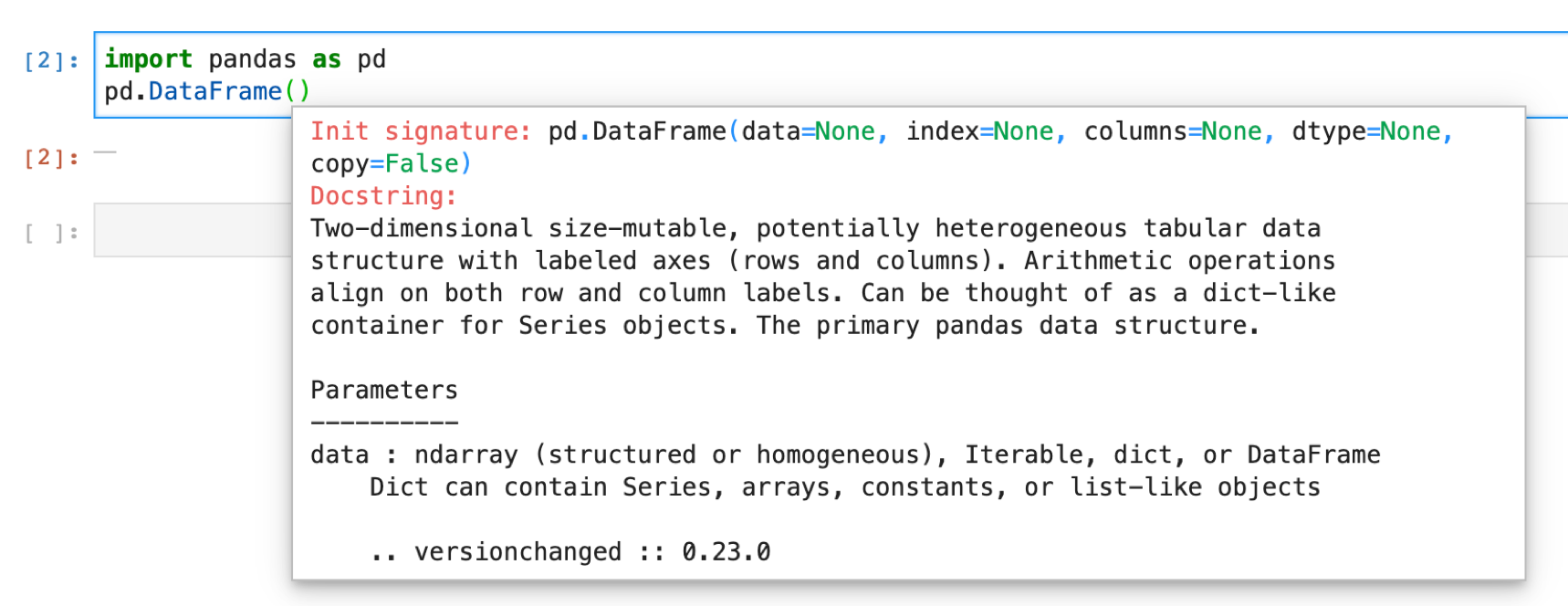
ふむふむ,,, dataとindex,columnsとdtypeとcopyという引数をとるらしい.
その下をみるとParametersの定義が書いてあるのでみてみると,dataにはndarrayやdictionaryなどを取ることができる.ということがわかります.
ここではまず,numpyでNxMの行列を作ってDataFrameを作ってみます.表形式ですからね,二次元arrayを作ります.
|
1 2 3 |
import numpy as np ndarray = np.random.randint(5, size=(5, 4)) pd.DataFrame(data=ndarray) |
実行すると
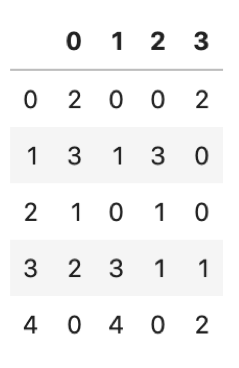
こんな感じで表ができると思います.これにindexとcolumnsをリストで指定してあげると
|
1 2 3 |
columns = ['a', 'b', 'c', 'd'] index = np.arange(0, 50, 10) pd.DataFrame(data=ndarray, index=index, columns=columns) |

indexとcolumnsが指定した値になってますね.
- dictionaryから作る
次はdictionaryから作ってみましょう. dictionaryのリストをいれると,それがそのままDataFrameになります.普段はndarrayよりdictionaryから作ることの方が圧倒的に多いです.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
data1 = { 'name':'John', 'sex':'male', 'age':22 } data2 = { 'name':'Zack', 'sex':'male', 'age':30 } data3 = { 'name':'Emily', 'sex':'female', 'age':32 } pd.DataFrame([data1, data2, data3]) |
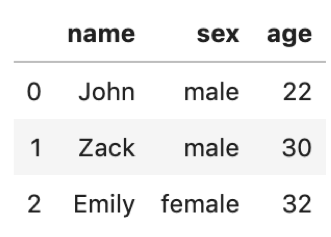
簡単ですね.
- ファイルから読み込む
そしてもっとも多いのがcsvやexcelから読み込む方法です.
今回はkaggleの有名な「タイタニックデータセット」を使ってみましょう.実データを使ってやった方がより実践的な学びを得ることができると思います.
kaggleというのはデータサイエンスのGoogleの傘下にあるコンペプラットフォームです.常にいくつかのコンペを開催しており,参加者はインターネット上でコンペに参加し予測モデルの精度を競います.
参加者はkaggle上でソリューションを公開することができ,kaggleを通して参加者同士でアルゴリズムについて議論することができます.非常に勉強になりますのである程度データサイエンスの知識がついたらぜひチャレンジしてみてください.
今回はkaggleで特に有名な「タイタニックのデータセット」を使います.タイタニックの乗客とその生死データです.
どういう乗客が生き延びて,どういう乗客が死んでいるのかがこれを見るとわかります.結構面白いですよ.
ちなみにこのデータは偽物です,データサイエンスに興味を持たせるために作ったものです.あと,この事故で実際に亡くなられた方がいることを忘れてはいけません.私も普段亡くなられた方や重症患者のリアルな医療データを日々扱っていますが,その裏に壮絶なドラマがあることを忘れてはいけないと思ってます.
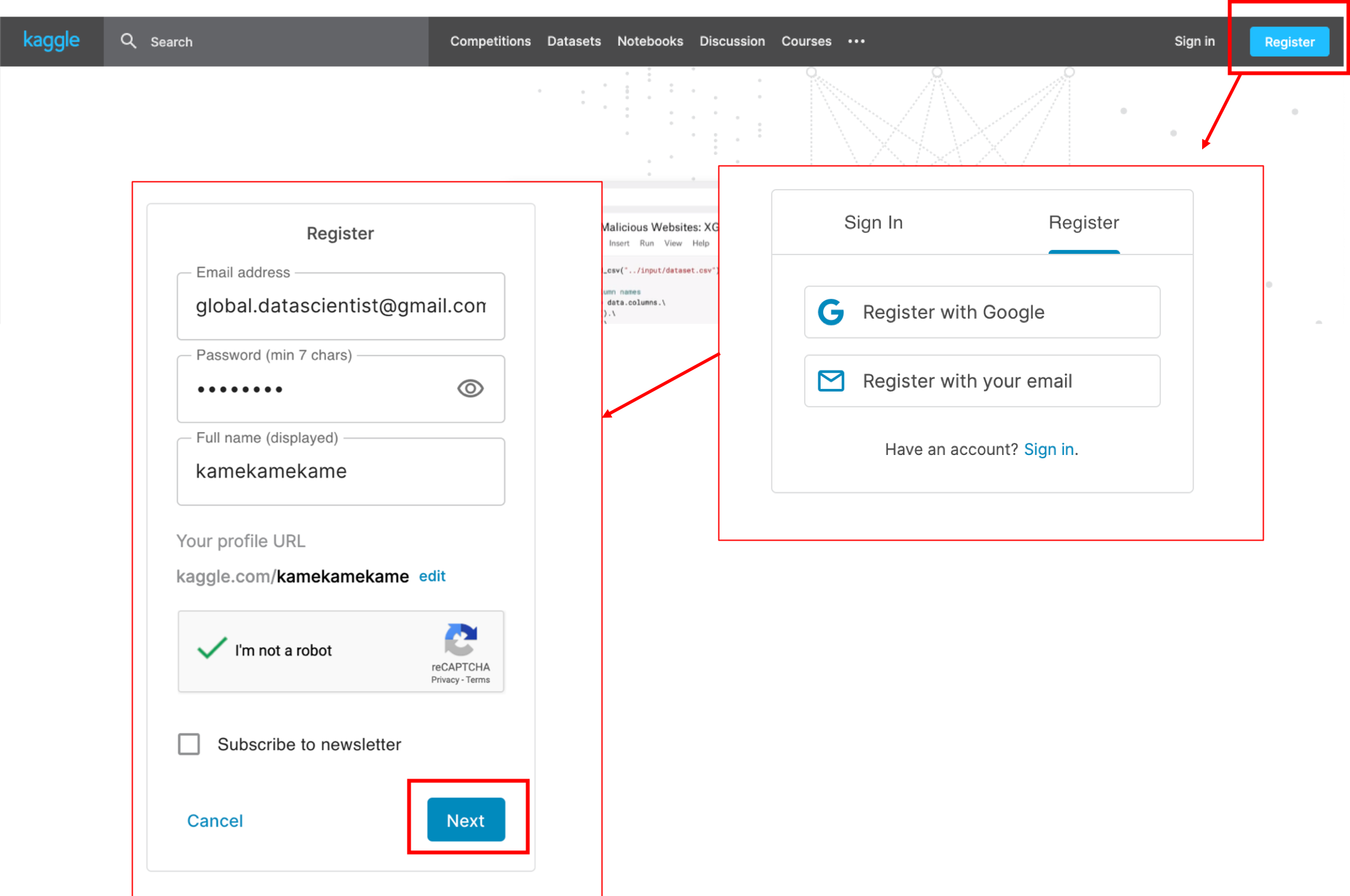
それではまず,kaggleに登録しましょう.
kaggleのサイトに行き,「Register」をクリックし登録します.特に迷うことはないと思います.ちなみにFull nameはあとで変更可能です.「Next」を押したらprivacy policyに関する誓約書があるのでそれにagreeをするとemailがきますので,「click here」をクリックすれば登録完了です.
↓こんな感じのメールがきてます↓
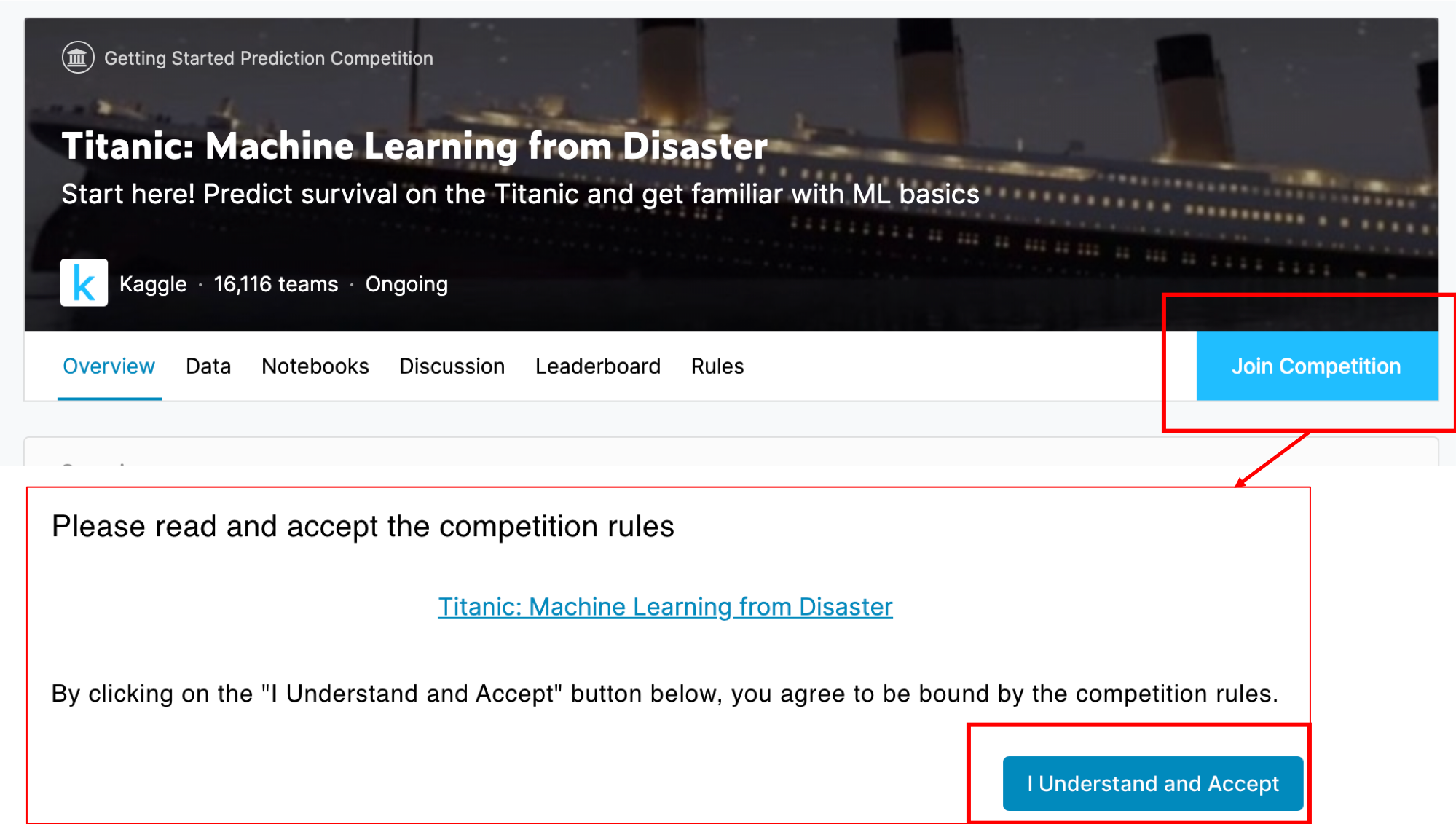
登録が完了したらら,タイタニックのコンペページにアクセスして「Join Competition」をクリックしましょう.ルールの説明があるので,「I Understand and Accept」をクリックすればエントリーできます.
「Data」タブをクリックし「train.csv」をダウンロードしてください.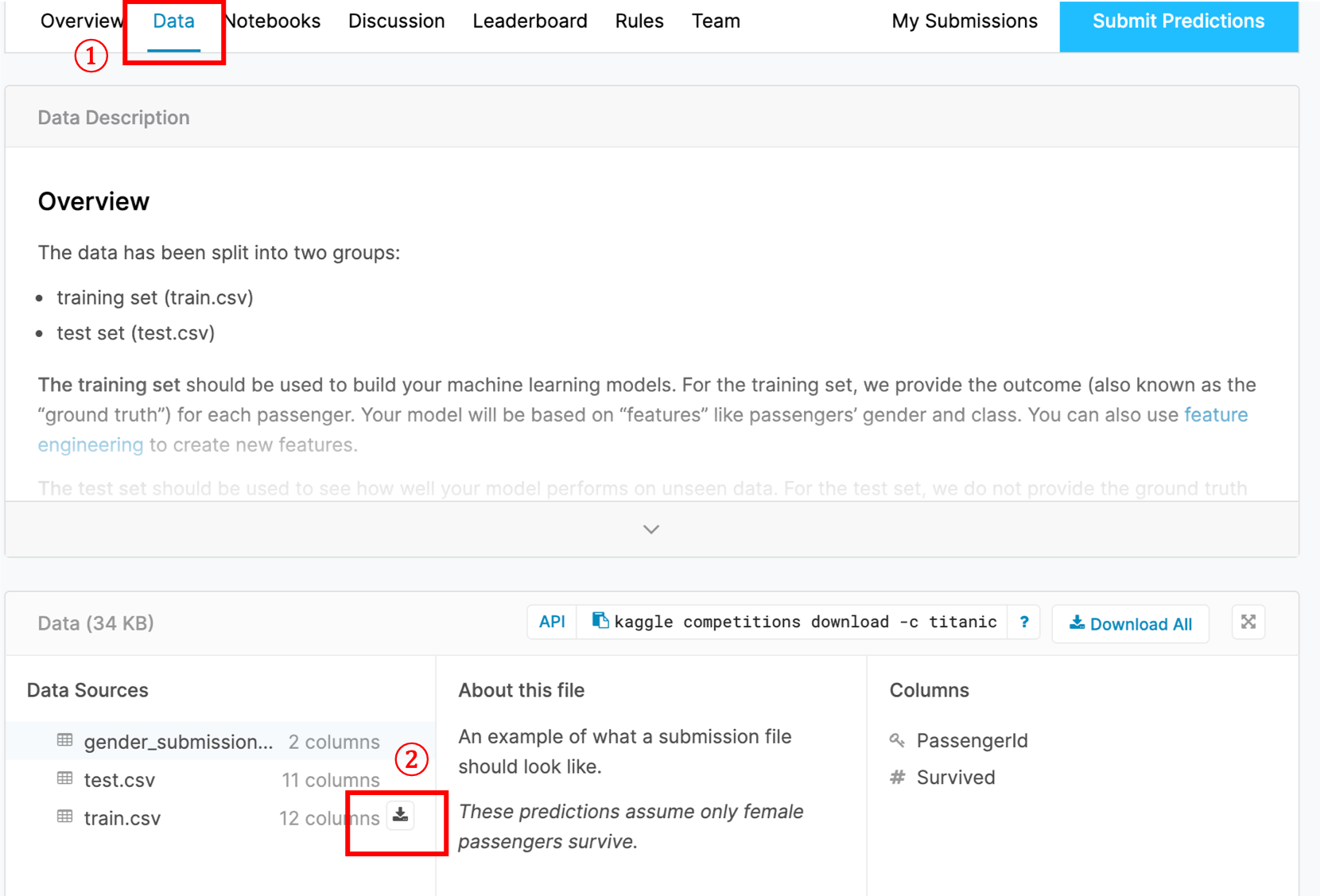
ダウンロードボタンは,マウスをかざすと出てくると思います.ちなみにこちらのリンクから直接DLすることもできます.
本講座の第一回のとおりに環境構築されている方は, Dockerをrunする際に -v ~/Desktop/ds_python:/ のオプションでホストとコンテナのファイルシステムのマウントをしていると思います.私の場合だと ~/Desktop/ds_python がマウントされているので,このフォルダの中であればコンテナからアクセスすることができるようになっています.
train.csv を ~/Desktop/ds_python 配下に配置します.これでcsvファイルからDataFrameを作成する準備が整いました.
それではこのタイタニックデータをPandasを使って読み込みましょう. pd.read_csv() で読み込みます.
|
1 |
pd.read_csv('train.csv') |
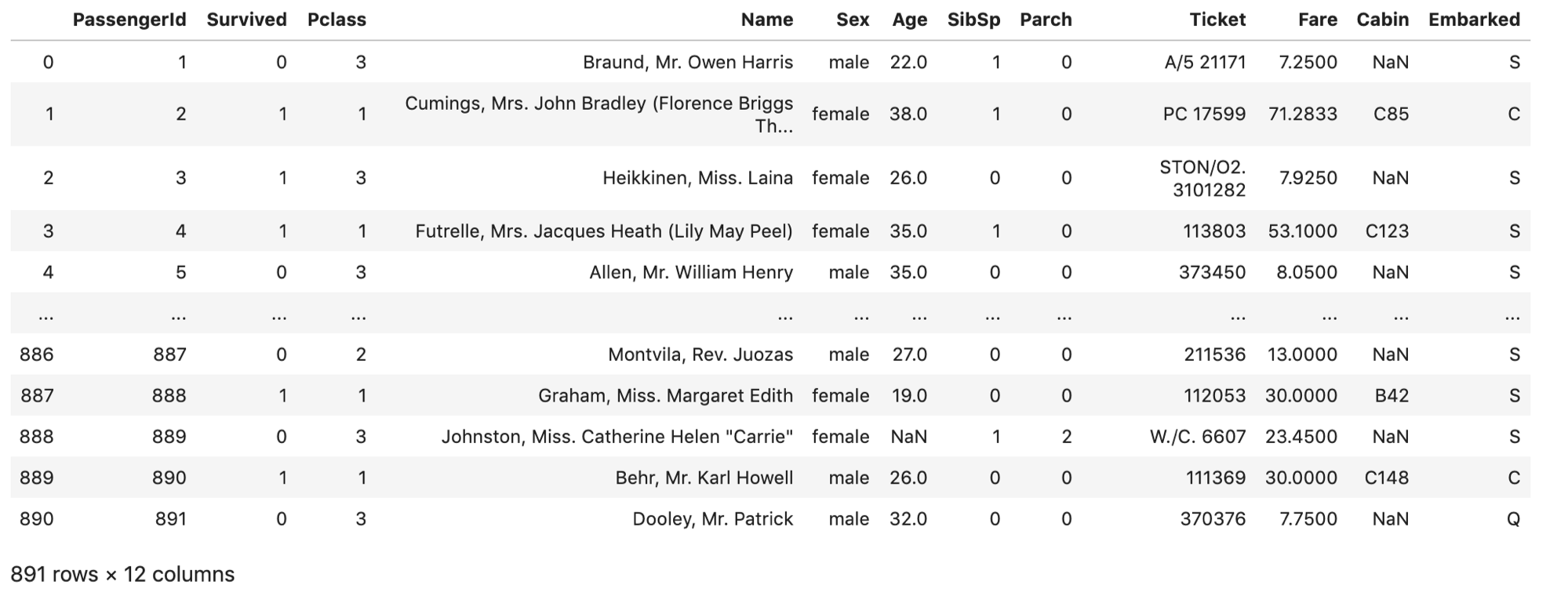
どうやら全部で891レコードの12カラムあるようですね.これで,csvを読み込むことができました!「Suvived」カラムをみるとその人は生き残ったかどうかがわかります・・・
実業務では,このようにcsvファイルを読み込んでpythonで処理することがほとんどになると思いますので覚えておきましょう.また,csv以外にもexcelファイルやjsonなど他のフォーマットのファイルでも大抵読み込めます.
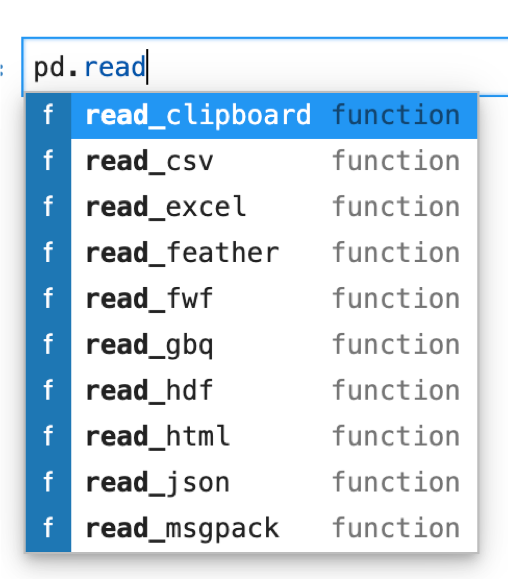 試しに「pd.read」と打ってtabキーを押してみてください.pd.read_シリーズの候補が表示されます.
試しに「pd.read」と打ってtabキーを押してみてください.pd.read_シリーズの候補が表示されます.
試しにエクセルファイルを作ってpd.read_excelで読み込んでみてください.
データサイエンス関連のPythonを学ぶと,このようにExcelをPandasで読み込んでPythonで処理することも可能になります.
私はPythonができるようになってからExcelのマクロや数式などは全く使わなくなりました.
本講座を終わる頃には脱Excelができるようになっているとおもいますのでご期待ください!
まとめ
今回はPandasのDataFrameの作り方を紹介しました.大きく3つのやり方があります.
- ndarrayとcolumnsを指定して作る
- dictionaryのリストを指定して作る
- 既存の表形式のファイル(csv, excelなど)を読み込んで作る
また,Kaggleについても紹介し,実際にタイタニックのデータを使ってDataFrameを作りました.
今後の講座でもちょくちょくこのデータを使っていくのでちゃんとDLしてコンテナからアクセスできるところに置いておいてくださいね!
それでは!!
追記)次回書きました↓ DataFrameの超基本的な使い方を書いてます.どれも超重要です.
データサイエンスのためのPython入門12〜DataFrameの基本的な使い方(head, describe, Seriesの取得など)〜








