







こんにちは,米国データサイエンティストのかめ(@usdatascientist)です
データサイエンティストのためのPython入門第12回です(講座の目次はこちら).今回は前回の記事で作ったタイタニックのDataFrameを色々と操作してみようと思います!ある程度ストーリー立ててやっていくので飽きずに進められると思います.ただの紹介じゃつまらないからね(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
実際にJupyterで自分でコードを書いて実行してください.気になったら色々試してみること.それが上達の第一歩です.
目次
DataFrameの変数には’df’をよく使う
特に理由がなければDataFrameのオブジェクトに df という変数を使って操作することが多いです.なんのDataFrameかを明確にしたい時は, train_df や titanic_df とするとわかりやすいです.今回は df にします.(pdと似ているので注意. 私はよく間違えますw)
|
1 2 |
import pandas as pd df = pd.read_csv('train.csv') |
.head()で最初の5レコードのみ表示する
pd.read_csv() した後は,ちゃんと読み込まれているか必ず見るようにしましょう.普通にJupyterで df を実行すると↓のように途中の行が省略され,最初の5レコードと最後の5レコードが表示されます.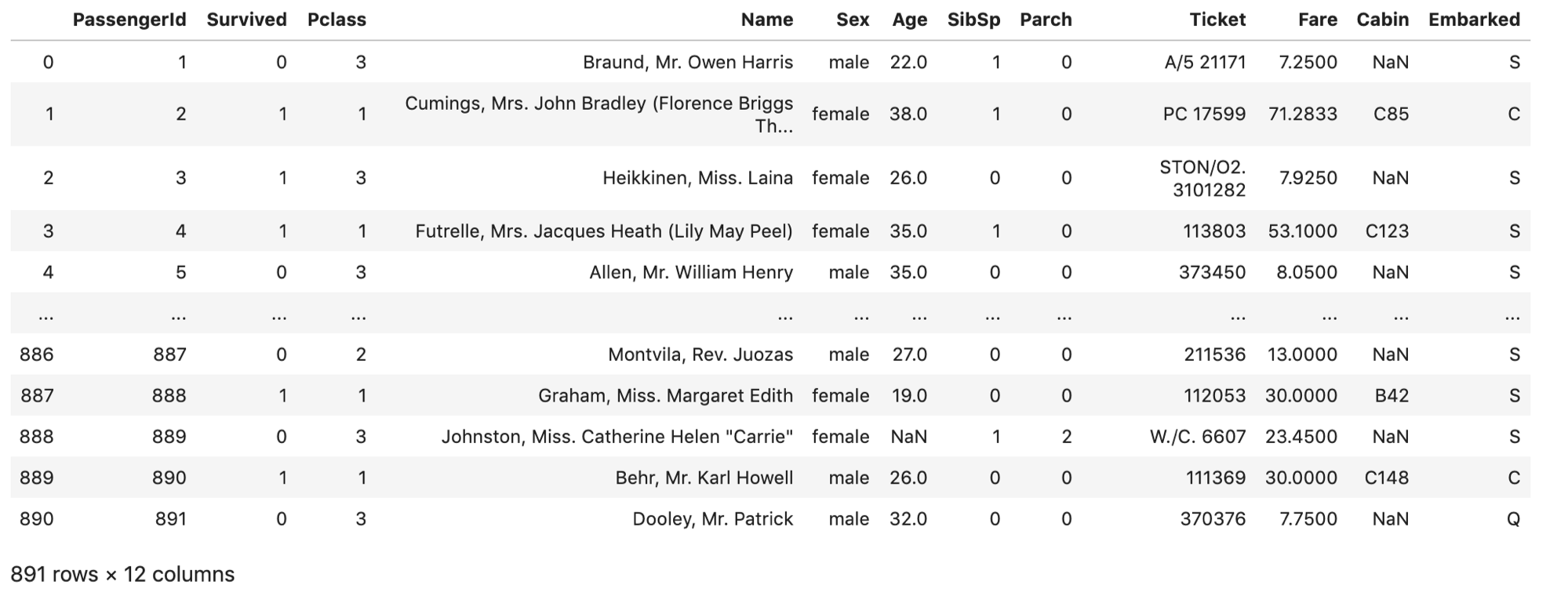
通常,これを全て表示する必要はないです.
私は pd.read_csv() で読み込み後, .head() で最初の5レコードを表示して内容を確認します.
また .head(3) のように数字をいれると,最初の「指定した数の行」のみ表示されて便利です.
|
1 |
df.head() |

.describe()で統計量を確認する
pd.read_csv() で読み込んで, .head() で中身を確認したら, .describe() という関数でデータの統計量をザッとみておきましょう.統計量については第9回で触れているので,アヤシイ人は戻ってみてみてください.|
1 |
df.describe() |
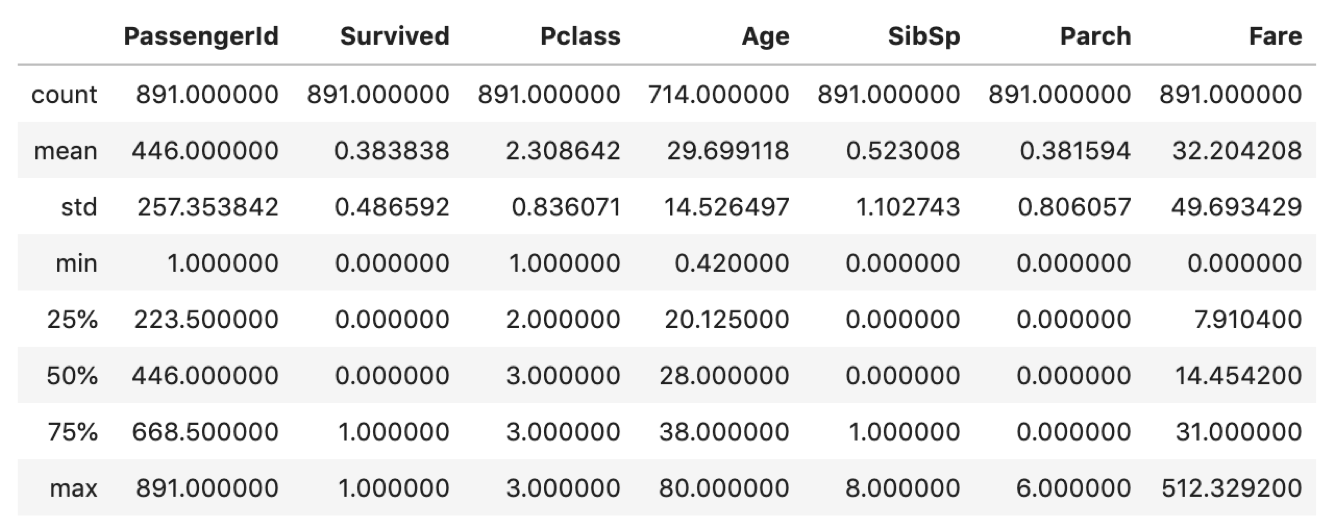 .describe() で統計量を確認できるのは,当然数値の項目のみです.
.describe() で統計量を確認できるのは,当然数値の項目のみです.
ふむふむ,,countはデータの数で,そのあとmean, stdが続きmin~maxの値が並んでいます.
例えばAgeをみると,乗客の平均は30才で,最高年齢が80才であることがわかります.意外に低いですね.家族づれが多いのでしょうか.
Fare(運賃)をみるとminが0になってます.無料で乗船した人がいるのでしょうかw
.describe() 一つでこんなに簡単に各統計量が確認できるんです.Pandasすごいでしょ?また,各カラムの説明についてはKaggleのタイタニックページに載っています.数値だけみていてはダメです.各データがなにを意味しているのか,実際の業務では「どのように取得したものなのか」を知ることも重要です.
また,この .desribe() の戻り値も同様にDataFrameです.なのでこれ自体をDataFrameとして扱うことが可能です.
|
1 |
type(df.describe()) |
|
1 |
pandas.core.frame.DataFrame |
.columnsでカラムのリストを表示する
.columns で,そのDataFrameが持っているカラムのリストを取得することができます.今回のデータは12個しかカラムがないのでJupyterで全てのカラムを表示できますが,実業務だとこれが30を超える場合もあり,全てを表示できません.どんなカラムが持っているのかを確認することは非常に重要です. .columns でカラムのリストを取得できます.
|
1 |
df.columns |
|
1 2 3 |
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object') |
type() で確認すればわかりますが,実際には第3回で紹介したListsとは別のデータタイプです.が,同じように扱えます.
ブラケット[]で特定のカラムだけ抜き出したSeriesを取得する
第10回で説明したとおり,DataFrameの各行や各列はSeriesで構成されています.
まずは列を取り出してみます.ブラケット [] を使い df['カラム名'] で取り出せます.統計量を確認すると,Ageだけカウントが少なく714レコードしかありません.Ageカラムだけ抜き出してみましょう.
|
1 |
df['Age'] |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
0 22.0 1 38.0 2 26.0 3 35.0 4 35.0 ... 886 27.0 887 19.0 888 NaN 889 26.0 890 32.0 Name: Age, Length: 891, dtype: float64 |
これはAgeカラムのSeriesです.試しに type() でデータタイプをみてみます.
|
1 |
type(df['Age']) |
|
1 |
pandas.core.series.Series |
Seriesであることがわかります.
また,Ageの値をみるとNaNがありますね.NaNについては第9回で説明しました.NaNのレコード分,.describe()のcountが少なくなっていました.
それと, df.Age としても同じようにSeriesを取得できますが,これはオススメしません.
理由は,DataFrameオブジェクトには様々な関数や変数が用意されているのでそことコンフリクトする可能性があるのと,普通に間際らしいです.あと,カラム名にスペースがあるとこの方法では取得できません.
毎回ブラケットを使うようにしてください.
ブラケット[]にカラムのリストを入れて複数のカラムをまとめて抽出する
複数のカラムを抽出する場合はカラムのリストをブラケットにいれます.
|
1 |
df[['Age', 'Parch', 'Fare']].head() |
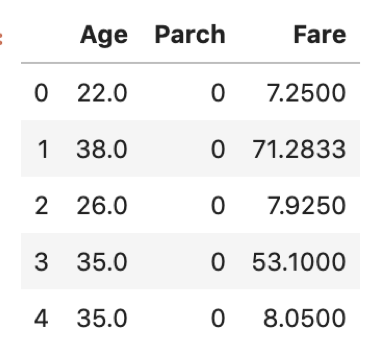
df[‘Age’, ‘Parch’, ‘Fare’]ではないことに注意です.初学者がよくやるエラーだと思います.
複数のカラムを抽出する方が圧倒的に多いので覚えておきましょう.
.iloc[int]で特定の行をSeriesで取得する
カラムの次は行です..iloc[int]で特定の行をSeriesで取得できます.先ほどAgeのSeriesをみると888行目がNaNだったので888行目を取り出してみます.あとilocというのは変な名前ですが,index locationの略です.
|
1 |
df.iloc[888] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PassengerId 889 Survived 0 Pclass 3 Name Johnston, Miss. Catherine Helen "Carrie" Sex female Age NaN SibSp 1 Parch 2 Ticket W./C. 6607 Fare 23.45 Cabin NaN Embarked S Name: 888, dtype: object |
Seriesなので当然,以下のように値を取ることも可能です.
|
1 |
df.iloc[888]['Age'] |
|
1 |
nan |
df.iloc[888] がSeriesでそのindexである ['Age'] にアクセスしています.「?」な人は第10回を復習しましょう.
第9回で紹介したnp.nan()がTrueになることを確認します.
|
1 2 |
import numpy as np np.isnan(df.iloc[888]['Age']) |
このNaNというのはnp.nanでありNoneではないことに注意です.
|
1 |
df.iloc[888]['Age'] is None |
これはすごく重要です.第9回で説明したとおり,NaNとNoneは違います.DataFrameで扱う場合ほとんどがNaNであることに留意しましょう!
また,みんな疑問に思う「なんでilocなの?普通にブラケットじゃだめなの?」について解説します.
理由はブラケットはカラムの取得に使うからです.以下のDataFrameで説明します.
|
1 2 3 4 5 6 |
np.random.seed(1) ndarray = np.random.randint(10, size=(5, 5)) index = ['a', 'b', 'c', 'd', 'e'] columns = [0, 1, 2, 3, 4] df = pd.DataFrame(data=ndarray, index=index, columns=columns) df |

indexが文字列で,columnsが数値であることに注意してください.また,np.random.seed()で乱数のタネを指定しています.1を指定すればみなさんの環境でも同じDataFrameが生成されているはずです.
この場合,columnsが文字列ではなく数値なので,df[‘0’]ではなくてdf[0]でカラムのSeriesを取得します.(なのでindexを指定する時,つまり行を取得するときはilocという関数を使うのです.)
|
1 |
df[0] |
|
1 2 3 4 5 6 |
a 5 b 0 c 2 d 2 e 1 Name: 0, dtype: int64 |
また,indexに文字列が指定されている場合は,iloc[数値]の他にloc[文字列]で特定の行のSeriesを取得できます.
|
1 |
df.loc['c'] |
ただ,基本はカラムは文字列,indexは数値になると思います.たまにindexにID(タイタニックでいうと PassengerId )を指定することもありますが,行の取得にはほとんどの場合 .iloc[] を使います.私は滅多に loc[] は使わないです.
また,カラムはできるだけ意味のある文字列にしてください.意味を持たない数値はややこしいのでやめましょう.
slicingで複数行取得する
第7回で紹介したslicingを .iloc[] で使うことができます.slicingがわからない人は第7回を復習してください
|
1 |
df = pd.read_csv('train.csv') df.iloc[5:10] |

簡単ですね.他にも色々なindexingやslicingを試してみてください!
.drop()で特定の行,列を落とす
カラムを落とすのによく使います.一方,特定の行を落とすということはあまりしません.次回で紹介しますが条件を指定して該当する行を落とすというケースが多いからです.また,axis引数で行か列かを指定します.axis=0なら行を,axis=1ならカラムを.デフォルトはaxis=0です.
|
1 2 |
# 0行目を落とす df.drop(0) |
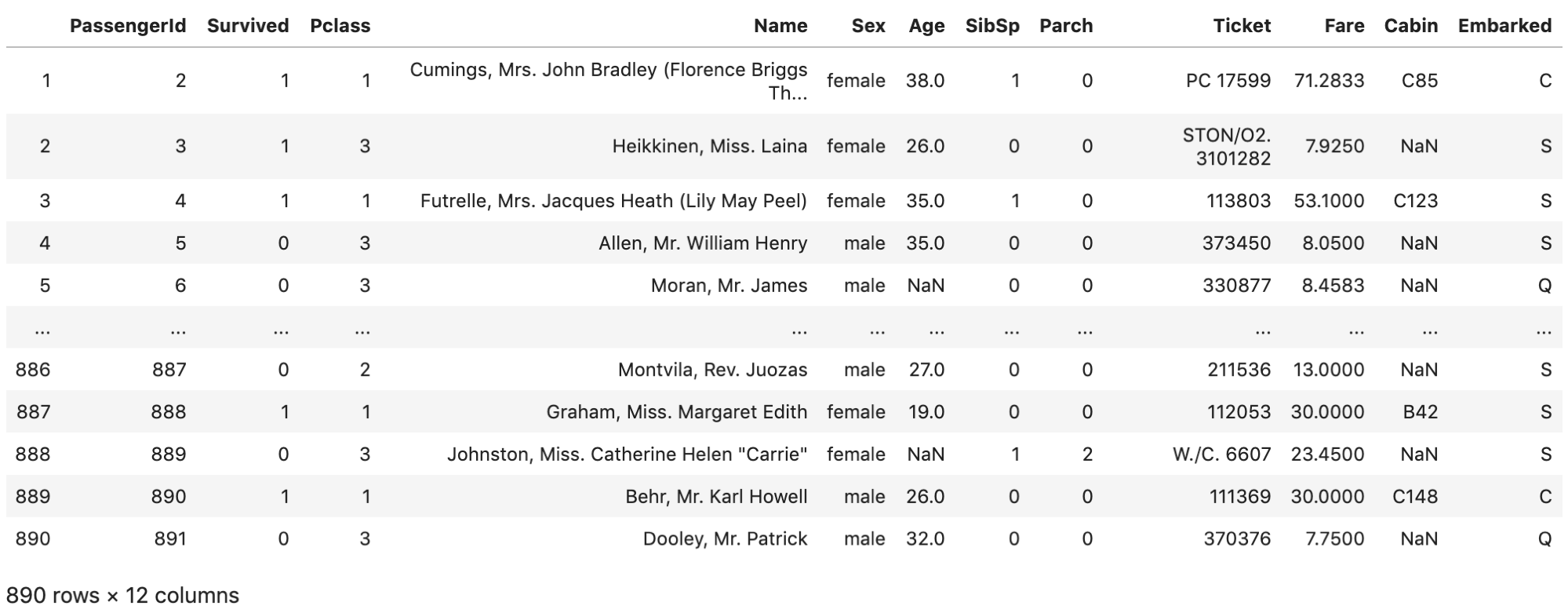
結果を元のdfと見比べてみてください.一行目(index=0)のレコードが落ちてます.
|
1 2 |
# Ageカラムを落とす df.drop('Age', axis=1) |
Ageカラムが落ちてますね.
複数のカラムを落としたい場合はカラムをリストにして渡してください.また,dropしても元のdfは変更されません.元のdfを上書きしたい場合は次の2通りで上書きします.
- inplace引数をTrueにする
|
1 2 |
df = pd.read_csv('train.csv') df.drop(['Age', 'Cabin'], axis=1, inplace=True) |
- 結果を同じdfに代入する
|
1 2 |
df = pd.read_csv('train.csv') df = df.drop(['Age', 'Cabin'], axis=1) |
他のプログラミング言語を勉強した人からすると,後者は違和感のある書き方だと思います.なるべく結果は違う変数にして変数名を変えて意味を持たせることが多いと思います.例えば df_drop という変数名にしたりとか
しかし,データサイエンスでは一つの変数が巨大なメモリを使っているケースが多いです.タイタニックのデータは練習用なので小さいですが,実業務では普通に1万レコードとかになったりします.
大きなデータを複数のメモリでコピーしていくとすぐにメモリリーク(メモリ不足)を起こしてしまうので,同じメモリを使いまわすのが定石です.(ここではdfというオブジェクトを使い回しています.)
この書き方は今後何度も出てきます.大きくなるようなデータ構造(ndarrayやDataFrameなど)の場合は「再度同じオブジェクトに代入」することが多いです.慣れましょう!
まとめ
今日学んだのは以下の通りです.
- DataFrameの変数にはdfをよく使う
- .head()で最初の5レコードのみ表示
- .describe()で統計量を確認
- .columnsでカラムのリストを表示
- ブラケット[]で特定のカラムだけ抜き出したSeriesを取得
- .iloc[int]で特定の行をSeriesで取得
- .drop()で特定の行,列を落とす
- 大きくなるようなデータ構造は再度同じオブジェクトに代入
結構盛りだくさんですが,これらの操作はDataFrameを扱う上で基本中の基本です.
特に最初の.read_csv→.head()→.describe()→.columnsの流れはファイルを読み込むたびにほぼ毎回やります.
今後も何度も使う操作なので覚えておきましょう〜.気になったら自分で色々タイタニックのデータをいじってみるといいと思います!
それでは!
↓次回書きました.データサイエンス最頻出操作の一つであるフィルタ操作について解説します!(超重要)








