こんにちは,米国データサイエンティストのかめ(@usdatascientist)です
データサイエンスのためのPython入門第10回目です(講座の目次はこちら).この講座ももう二桁に突入しましたが,まだまだ終わる気配がないですw 20回までには終わらせたいとは思っていますが・・・(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
前回まではNumPyというライブラリを扱ってきました.今回からPandasというあらたなライブラリを扱っていきます.
多分多くのデータサイエンティストが一番よく使うライブラリで,超重要 というかPandasなくしてPythonのデータサイエンスは語れないと言えるくらい必須事項です.今まで以上にデータサイエンスっぽくなってくるのでお楽しみに!!
目次
Pandasとは?.
日本語では,パンダス,英語ではパンダズと呼びます.どっちで呼んでもいいと思います.パンダの複数形でしょうか,名前の由来は知りません
Pandasはデータ操作や解析を目的として作られたPythonライブラリで,NumPyをなかで使ってます.
とりわけ表形式のデータ処理が得意で,エクセルで処理するようなことをPythonでできると思っていただければOKです.
データサイエンスの分野では,大抵データは表形式で扱います.普通,データってそうですよね?カラムがあってそれぞれの行(レコード)があって・・・まさにExcelでやるようなことです.
Pandasでデータ処理をするようになってから,Excelでマクロ書いたり数式書いたりすることが一切なくなりました.今は全てPandasを使ってPythonで書いてます.
この講座で一通りPandasを学べば,普段のExcel業務をPandasに置き換えることもできるかもしれません.
Excelでマクロや数式を書くより圧倒的にPandasでデータ処理を書いた方が早いです.作業の効率化がはかれます.
説明を聞くより実際に触って動かした方が理解できると思いますので早速使ってみましょう.
Pandasをimport
PandasはNumPy同様Anacondaディストリビューションに入っています.そのため特にInstallは不要です.
(環境のセットアップは第一回の記事を参考にしてください.ちなみにインストールするにはpipをつかって $pip install pandas でインストール可能です.)
Pandasも,NumPy同様importが必要です.(第6回参照) 以下のようにしてimportします.(Jupyter Labで実行してください.)
|
1 |
import pandas as pd |
NumPyではnpとしてimportしていたのと同様に,pandasではpdとしてimportするのが慣習です.
ここからはpd.関数名で色々なPandasの関数やクラスを使っていきたいと思います.
まずはSeriesを使う
PandasにあるSeriesというクラスを使ってみましょう.このSeriesというのは,表形式のデータの各行やカラムを切り取ったデータを表すデータ形式です.
ここで,少し用語を整理します.以下の表形式のデータがあったとします.
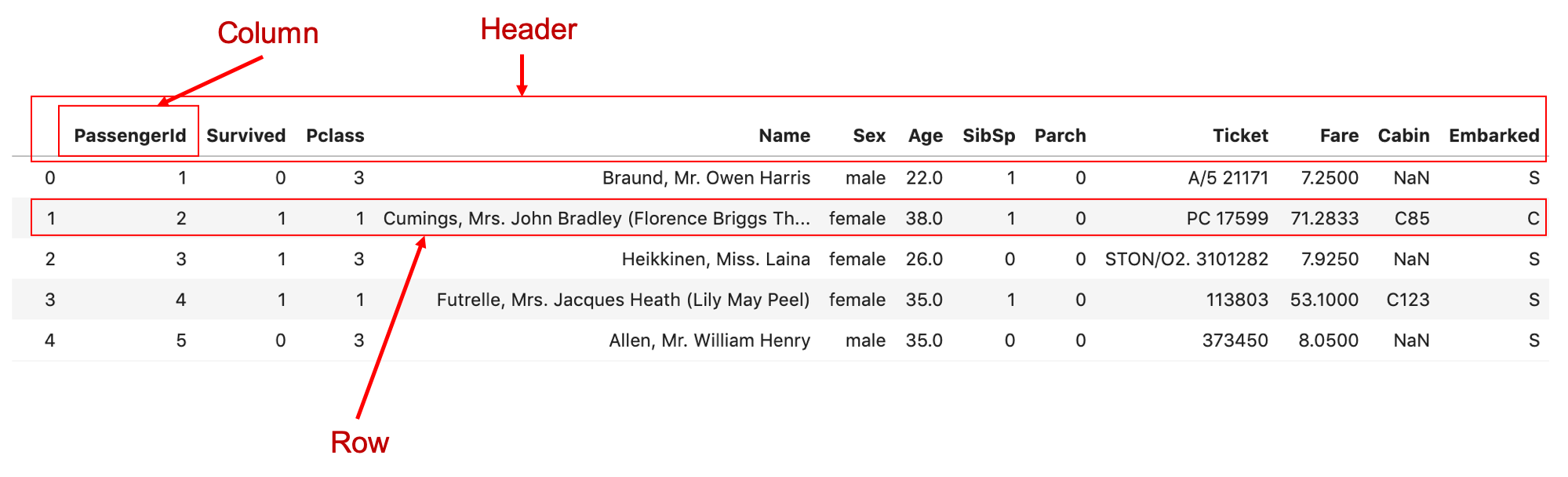
表形式のデータをテーブル(Table)と呼んだりもしますが,この表の一番うえに並んでいるのをヘッダー(header)と呼び,ヘッダーを構成する一つ一つをカラム(column)と呼びます.また,表には色々なデータがずらっとヘッダーのカラム順に合わせて並んでいますが,その一行一行を行(row)と呼びます.行のことをレコードと言ったりする人もいます.
Pandasでは,この表をDataFrameというデータ構造で扱います.そして,各行をSeriesというデータ構造を使って扱います.つまり,Seriesというデータ構造が集まってDataFrameというデータ構造になるイメージです.また,縦に切り取ってもSeriesになるので覚えておきましょう.

何言ってるかわからないかもしれませんが,これからの講座でどちらもたくさん扱っていくので徐々にわかっていけばOK!
それではSeriesのオブジェクトを作ってみましょう.
作り方は簡単で,dictionaryを作ってそれをpd.Series()に入れるだけ
|
1 2 3 4 5 6 7 |
data = { 'name':'John', 'sex':'male', 'age':22 } john_s = pd.Series(data) print(john_s) |
|
1 2 3 4 |
name John sex male age 22 dtype: object |
左に見える’name’, ‘sex’, ‘age’は,Seriesではindexと呼びます.このindexに’name’, ‘sex’, ‘age’とラベルをつけました.
NumPy Arraysを使って作ることも可能です.
|
1 2 |
array = np.array([100, 200, 300]) pd.Series(array) |
|
1 2 3 |
0 100 1 200 2 300 |
indexが0, 1, 2となっています.ラベルも一緒にパラメータに入れることでindexにラベルをつけることができます.
|
1 2 3 |
array = np.array([100, 200, 300]) labels = ['a', 'b', 'c'] pd.Series(array, labels) |
|
1 2 3 4 |
a 100 b 200 c 300 dtype: int64 |
SeriesのindexはDataFrameでいうカラムにあたることもあればindexのまま使われることもあります.(DataFrame縦に切った場合はindexになるし,横に切ればカラムになる)よく使うのはdictionaryからの作成です.arrayとlabelのリストでは長くなるとどの値がどのラベルに対応するのかがわかりにくくなるので注意です.
当然,以下のように特定のindexを指定して値を出すことが可能です.
|
1 2 3 4 5 6 7 |
data = { 'name':'John', 'sex':'male', 'age':22 } john_s = pd.Series(data) print(john_s['age']) |
|
1 |
22 |
まとめ
今回はPandasについてと,SereisとDataFrameについて触れ,実際にSeriesを作ってみました.
次回はDataFrameを使います.データサイエンスのほとんどの仕事はこのDataFrameを使って作業するといっても過言ではありません.
かなり重要な内容になりますので,今回の内容をしっかり意識しつつ進みましょう.
それでは!
追記)次回書きました.↓実際にDataFrameを作ってみます.Kaggleのタイタニックの乗客生存データセットを使います.面白いですよ!