こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門14です!もう14まできました(講座の目次はこちら).どこまで続くかわかりませんが,もう少しだと思います(笑
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
さて,今日はDataFrameにNaNがあるときの対応です.「統計学的にどうするか」ではなく「DataFrameの関数を使って何ができるか」にフォーカスしていることにご留意ください.統計学的にはNaN(欠損値:MIssing Value)がある場合,なにかしらの方法で埋めことがあります.平均値を代入したり,値を推計して代入したり.
そういった内容は今後予定している統計学講座にて説明するとして,今回は「DataFrameの関数でNaNをどう操作できるか」についてお話しします.
業務で扱う実データに「NaNがないデータ」なんてまずないでしょう.
必ずNaNはあるし,その都度適切な処理が必要になります.なので今回の操作を知っておくことは重要です.
目次
DataFrameのNaNについて
NaNについては第9回のNumPyの記事で紹介しました.第12回ではタイタニックデータではAgeにNaNがあることを話しました.
復習すると,
- NaNはNot A Numberの略
- np.nanと同じ
- NaN判定には np.isnan() を使う(後述: pd.isna()もあります.)
- Noneとは別物
- DataFrameでは基本NaNが使われる.
です.
ちなみに,csvやエクセルで値が空白だと読み込んだ時にNaNになります.Noneではないことに注意です.
それでは今回もタイタニックデータで遊びましょう!
|
1 2 3 4 |
import numpy as np import pandas as pd df = pd.read_csv('train.csv') df |
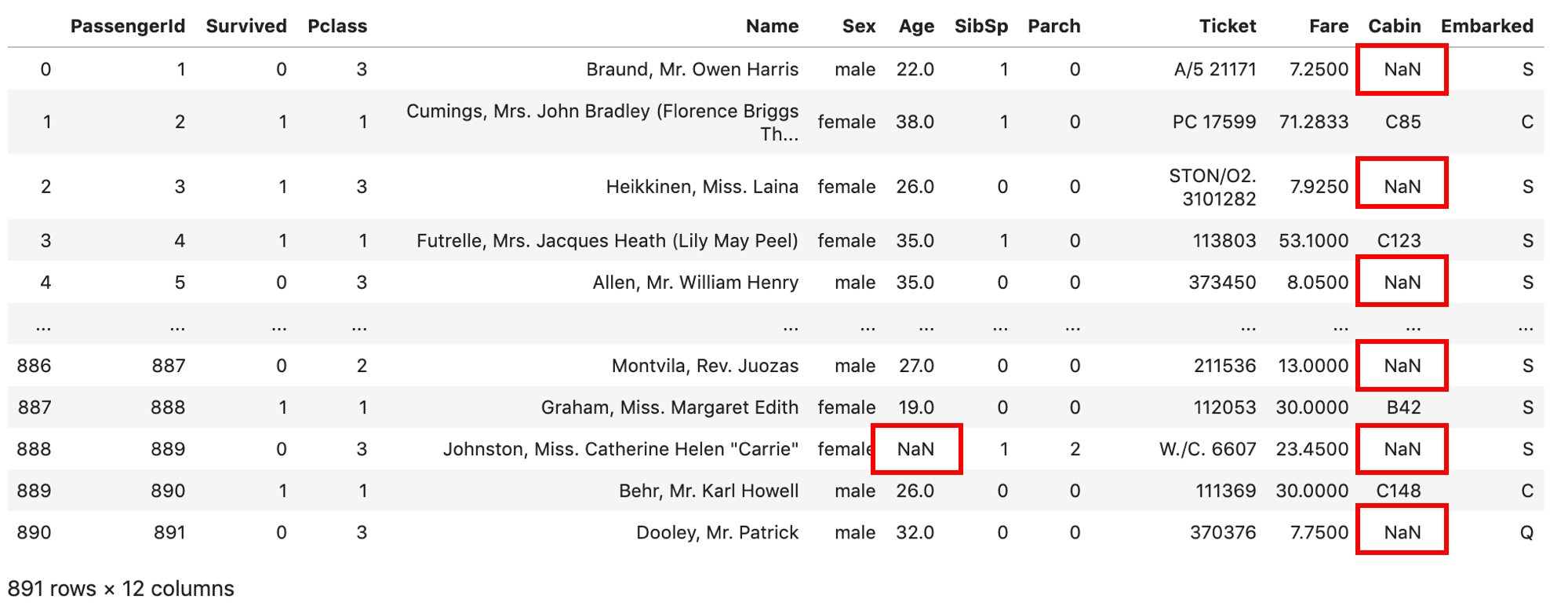
タイタニックデータにも,たくさんNaNがありますね!
DataFrameのNaN用の関数
DataFrameにはNaNに対していくつか関数が用意されていますので紹介していきます.実際にJupyterで書いて,Shift+Tabでリファレンスを確認しながら進めてくださいね!
- .dropna()
NaNがある行をdropします.これ,かなり使う関数なんですが,使い方が色々あってややこしいです.一つ一つ説明していきます.
まずはそのまま使ってみる
|
1 |
df.dropna() |
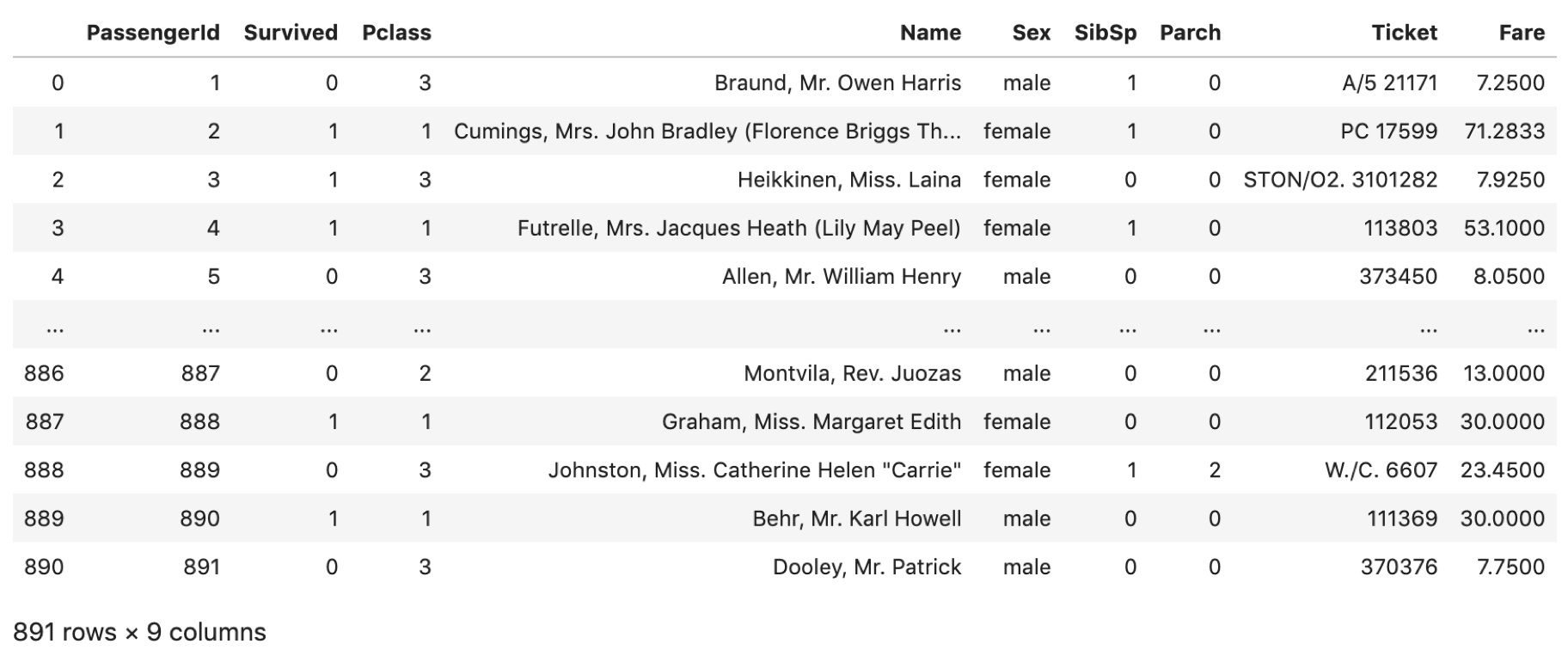
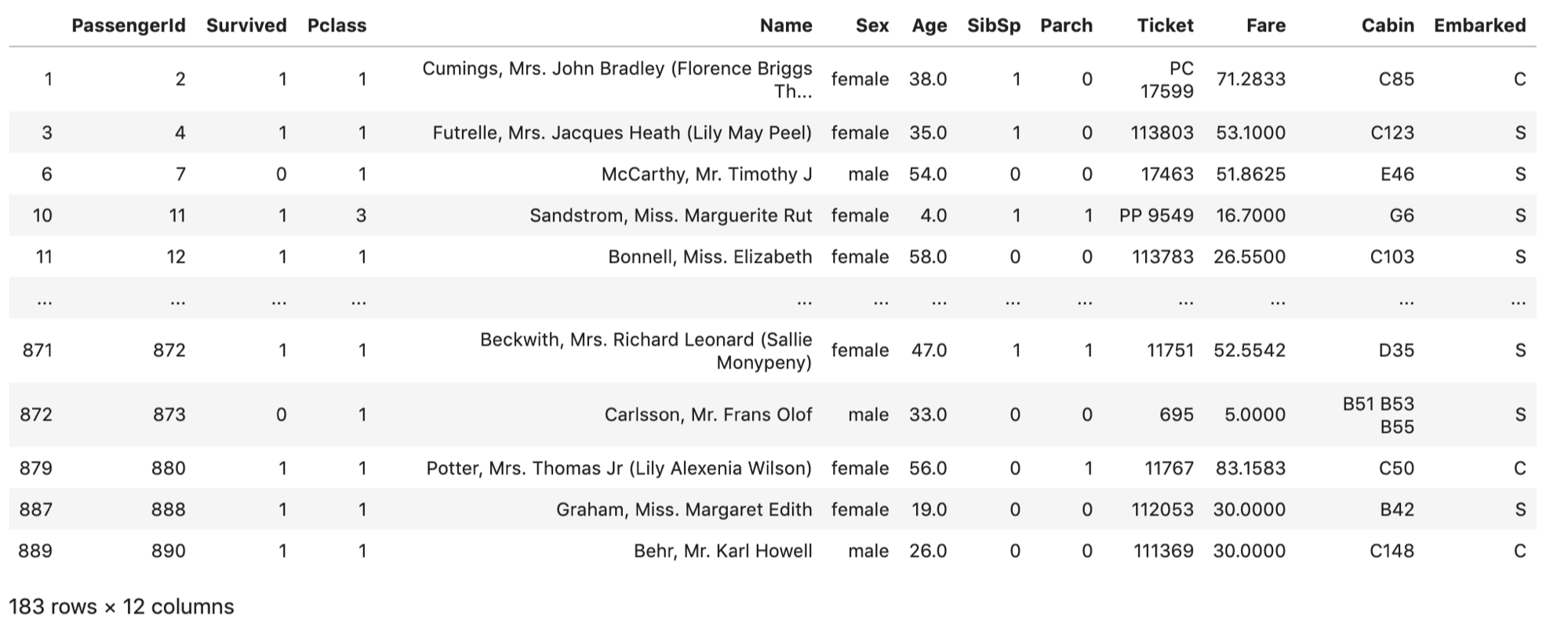 もとのdfと見比べてみてください.NaNを含んでいたレコードが全てdropされています.(indexはそのままになってます.基本,.reset_index()しない限りindexは再振りされません) レコード数もだいぶ減りましたね.
もとのdfと見比べてみてください.NaNを含んでいたレコードが全てdropされています.(indexはそのままになってます.基本,.reset_index()しない限りindexは再振りされません) レコード数もだいぶ減りましたね.
例えば予測モデルを作る場合,NaNがあったら数式に当てはめられないので,NaNを含むレコードを全て排除するという選択をすることがあります.その場合データが減ってしまいますが,人工的なデータ(例えば平均値で埋めるとか.)を含まないので,より信頼性の高いデータのみでモデルを構築することができます.データがふんだんにあるときは.dropna()で全てdropするのも手ですね.
axis=1を引数にいれるとNaNを含むカラムをdropできます(デフォルトはaxis=0で行).あまり使わないと思います.モデルを組む際に,データ数を減らさずにデータを説明する変数(説明変数)を減らす作戦のときに使いますが,「NaNが一つでもあるのでその説明変数を減らす」ということはまずありません.どの説明変数がモデル構築に重要なのかというのは非常に重要かつ慎重に考えるべき問題です.詳しくは今後の機械学習講座で取り上げていこうと思います!
|
1 |
df.dropna(axis=1) |
カラム名のリストをsubset引数に渡すことで,そのカラムにおいてNaNを含む行のみをdropしてくれます.これはよく使います.
実業務でデータ処理をしてると,当たり前のようにNaNばかりになったりします.もしcsvやエクセルでデータ作ったら,空欄は全部NaNですからね?そうなると特定のカラムにおけるNaNの行だけを落とす必要がでてきます.とても便利なので覚えておきましょう.あと,リスト形式で渡すので注意.たとえ一つのカラムでも,リストで渡します.
|
1 |
df.dropna(subset=['Age']) |
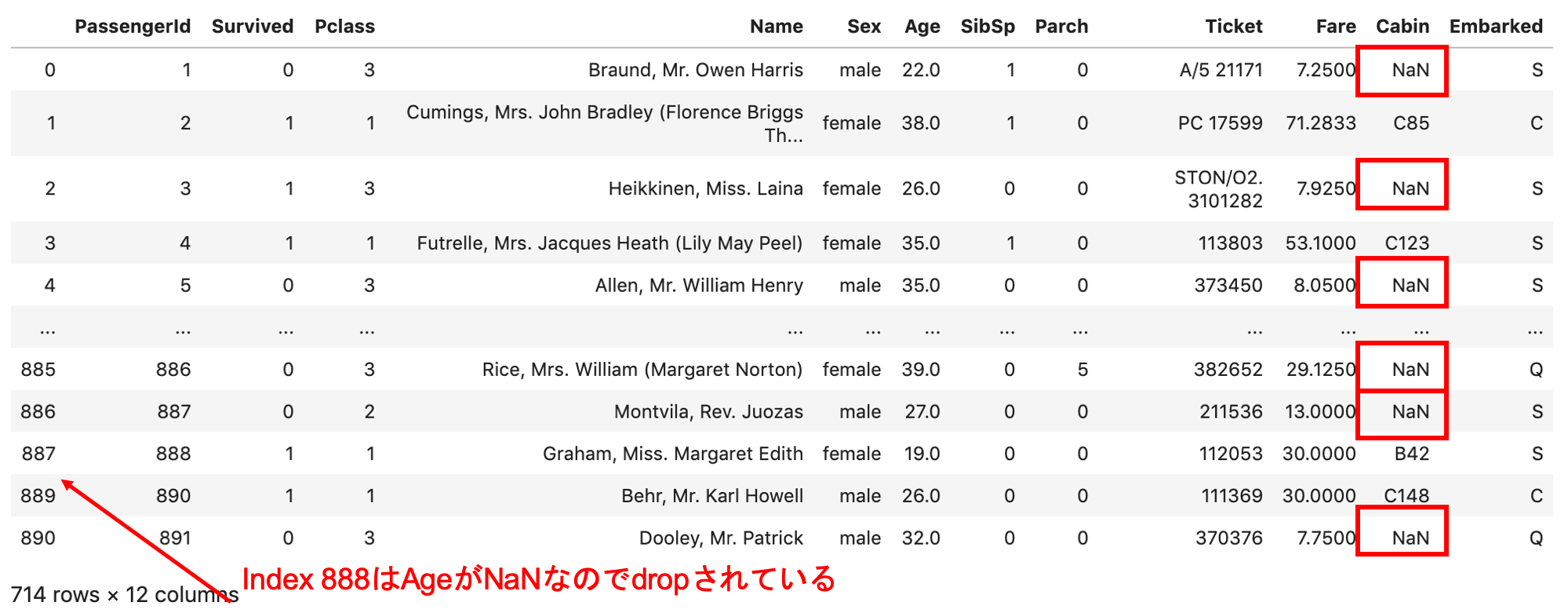
当然, .dropna() しても,元の df は上書きされません.元の df を更新したい場合はおなじみの inplace=True か df = df.dropna() で再代入します.
- .fillna(value)
NaNに特定のvalueを代入します.こんな感じです↓
|
1 |
df.fillna('THIS IS IT!!!') |
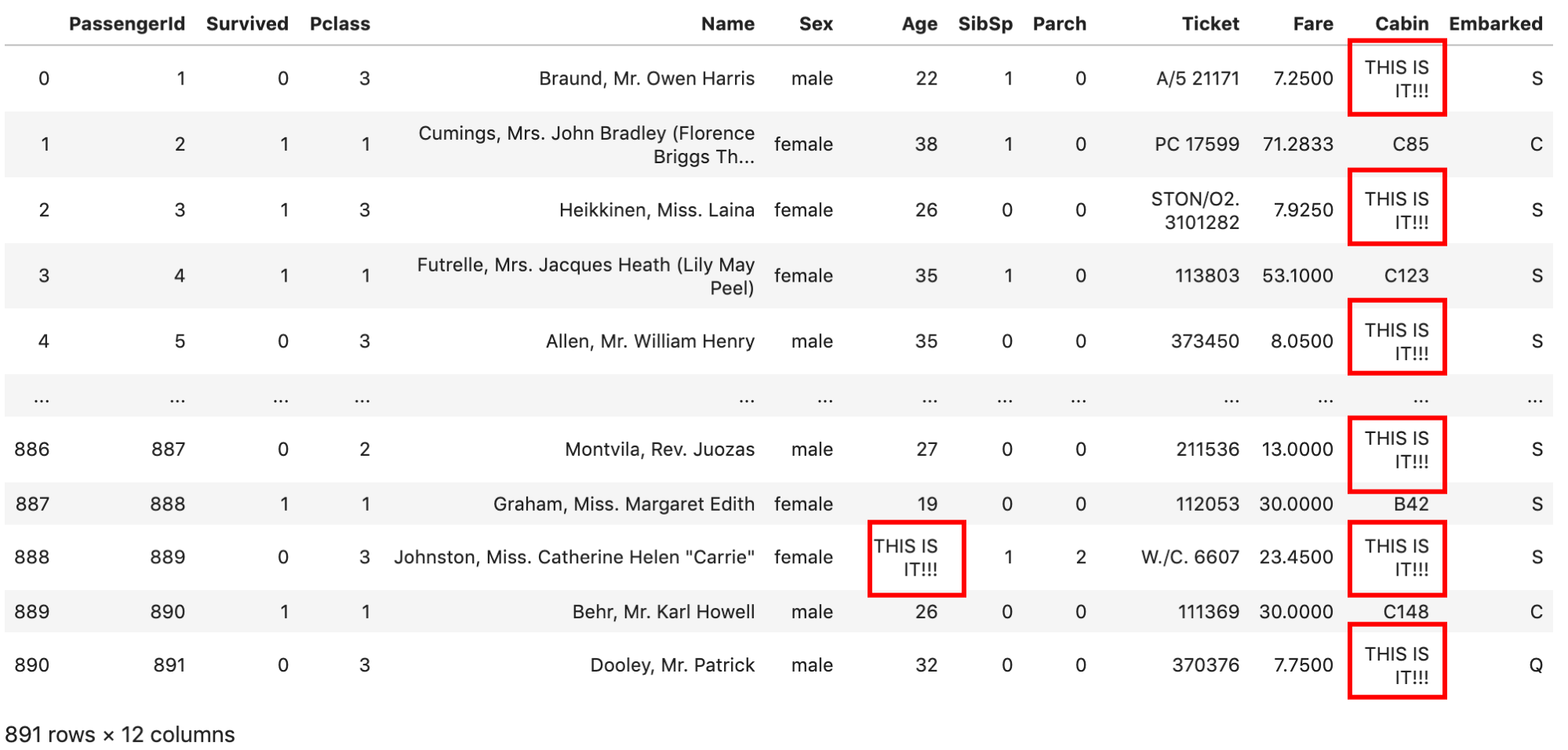
でも,実際の業務ではNaNに一律の値を入れるということはしません.なにか代表値を入れることが多いです.例えばAgeのNaNにはAgeの平均値を入れるとか.
それでは,AgeのNaNに,.fillna()を使ってAgeの平均値を代入してみましょう.少しややこしいですが,Step By Stepで説明していきます.
まず,Ageの平均値はカラム指定して.mean()でとれます.AgeのSeriesを取ってきて,Seriesのmean()関数を実行しています.NumPy同様,Seriesも統計量を取る関数が用意されています.(NumPyの関数は第9回を参照)
|
1 |
df['Age'].mean() |
|
1 |
29.69911764705882 |
これを.fillna(value)に入れれば良さそうですが,AgeカラムのNaNにだけ代入したいですよね.実は,Seriesにも同じ関数があるのでdf[‘Age’]でAgeのみのSeriesにしてからfillna(value)をすることで,AgeのNaNのみに代入できます.
|
1 |
df['Age'].fillna(df['Age'].mean()) |
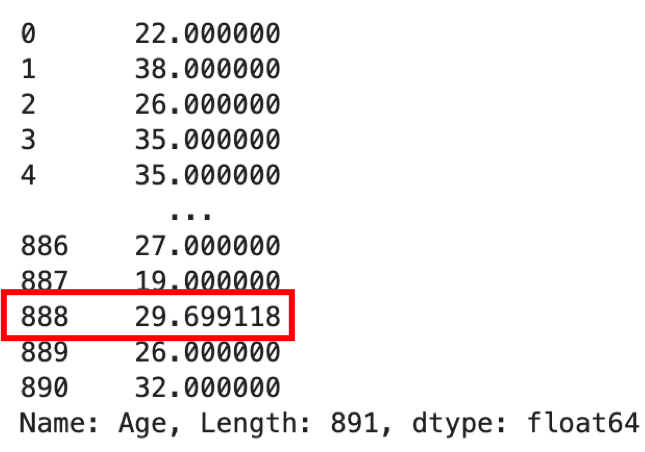
index=888のデータはAgeがNaNでしたが,平均値が代入されています.
そして,このSeriesをdf[‘Age’]に代入すればOKです.もとのdfのAgeカラムの値は全て上書きされることに注意してください.
|
1 2 |
df['Age'] = df['Age'].fillna(df['Age'].mean()) df |
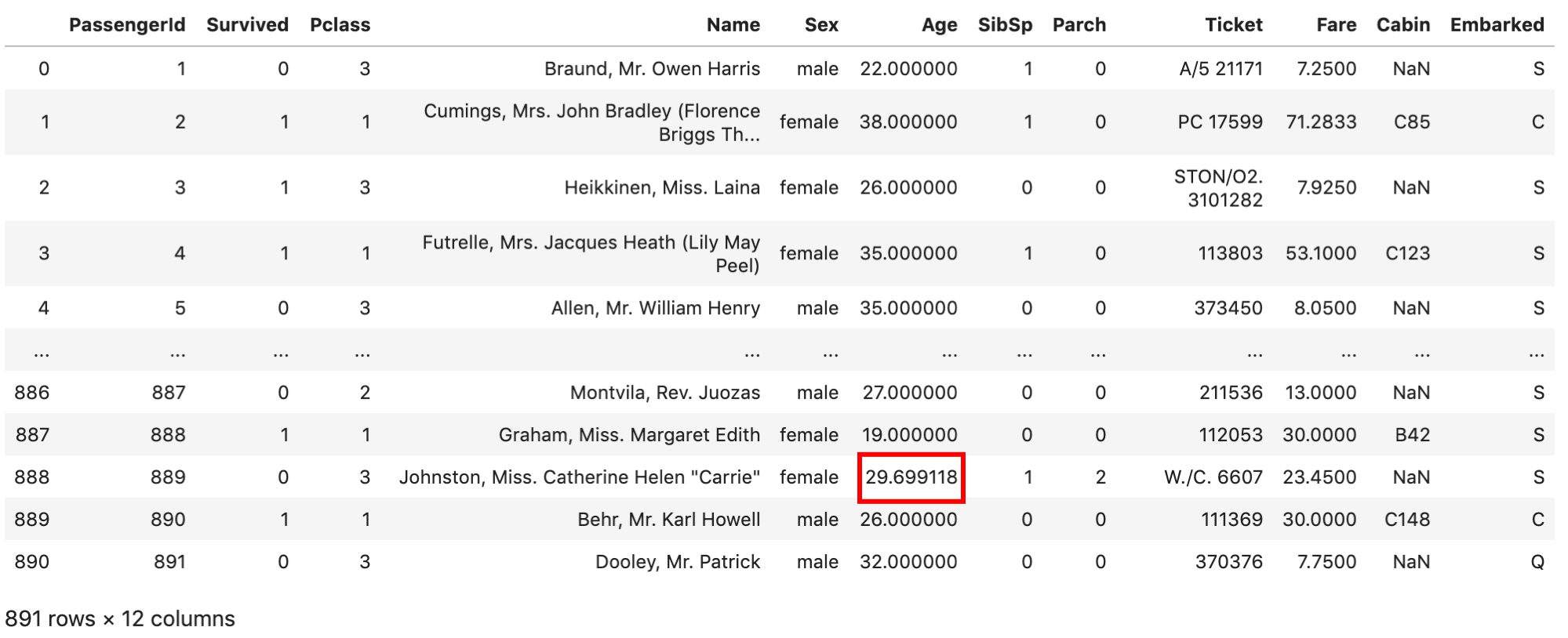
ちゃんと平均値が代入されていますね. .fillna() はだいたいこの使い方で出てきます.
pd.isna()
np.isnan() で,DataFrameの全ての値のNaNの判定が可能です. np.isnan() だといちいちループで回さないといけないですし,stringsを入れるとエラーになったり,使い勝手が悪いです.DataFrameの中の値のNaN判定には pd.isna() を使うといいです.( pd.isnull() も同じです.最近名前が変わって pd.isna() が実装されました.特に理由がなければ pd.isna() を使いましょう.np.isnanと違って最後のnがないので注意です.)
|
1 2 |
df = pd.read_csv('train.csv') pd.isna(df) |
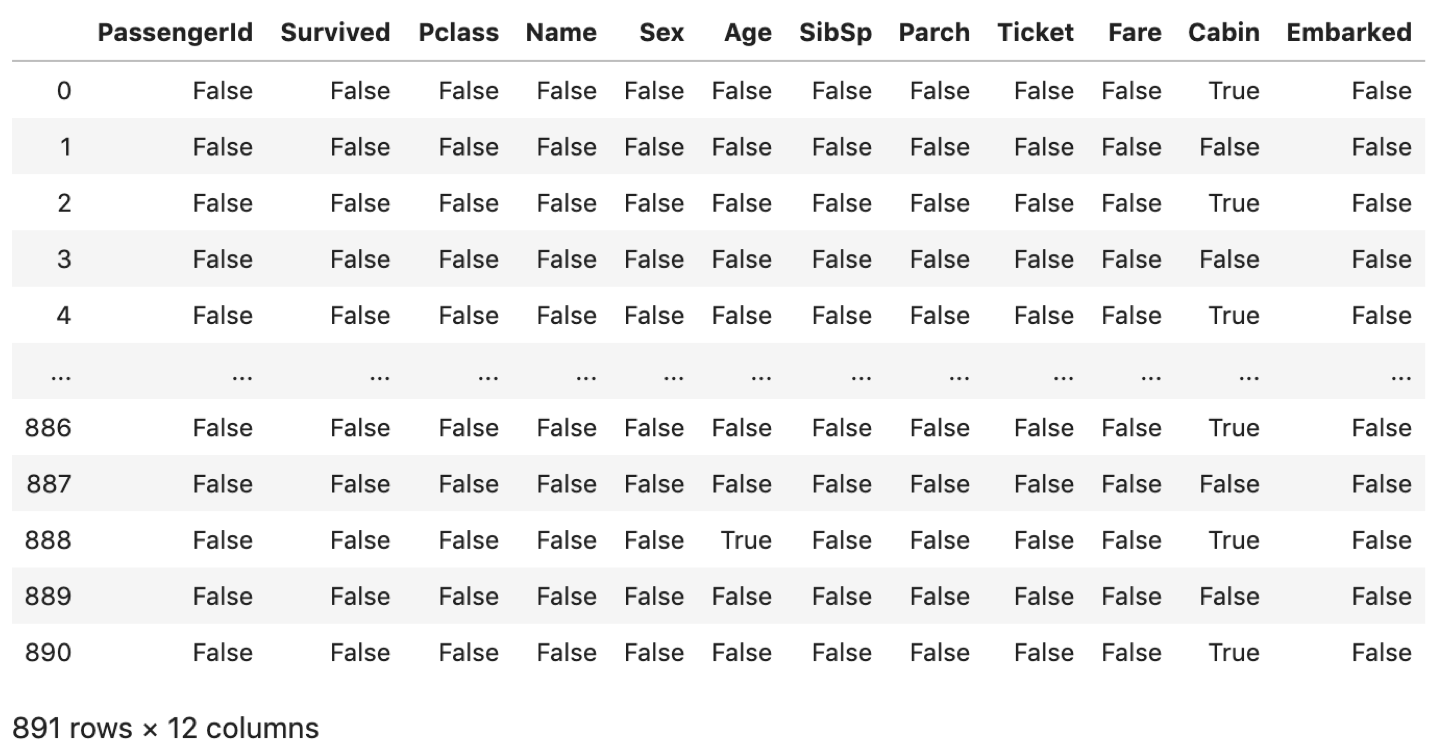
個人的にはよくSeriesに対してよく使いますね.NaN判定の結果を別カラムで持ちたい時とか↓
|
1 2 3 |
# Cabin_nanカラムを使いして,CabinのNaN判定結果を代入する df['Cabin_nan'] = pd.isna(df['Cabin']) df |

このように,df[‘カラム名’] = Seriesで,そのカラムにSeriesを代入できます.もしdfにそのカラムがなかった場合は新たに追加します.
基本的にこのようにしてどんどん新しいカラムを追加したり更新したりします.超頻出です.
まとめ
今回,DataFrameのNaNの扱い方について取り上げました.
統計学や機械学習では一般的に「欠損値」といいますが,この欠損値をどう扱うかというのはデータサイエンスでは非常に重要なポイントとなります.タイタニックでも所々にNaNが散りばめれていますが,「この欠損値をどうするか」で予測モデルの精度が変わるため,運営側もわざと散りばめたんだと思いますw
Kaggleでは,このtrain.csvデータを使ってある乗客情報を与えられた時にその乗客が生存するかどうかを予測するモデルを構築し,その精度を競います.
先ほど.dropna()したらレコード数が891⇨183レコードに減ってしまいましたが,183レコードでは精度の高い予測モデルを学習させることは難しいでしょう.そのため,なにかしらの手段で欠損値を代入する必要があります.
色々手法はありますが,そのあたりは今後の統計学講座で扱っていきたいと思っております.今はとりあえず「欠損値があるとそのままでは使えない」「何かしらの処置が必要」と覚えておきましょう!
それでは!
次回書きました↓頻出操作のgroupbyをマスターします!