こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門も17回まできました(講座の目次はこちら)!今回はDataFrame(およびSeries)の重要な関数である以下の関数たちを紹介したいと思います.
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
- .unique()
- .nunique()
- .value_counts()
- ,apply()
ここまでくると関数の引き出しが増えてきて混乱してくると思いますが,全てを暗記する必要はありません.
必要なときに毎回ググって出会えばいいのです.「そういえばこういうことができる関数があったな」くらいに頭の片隅に入れておけばOKです.私も最初はそうでした.
それでは,それぞれ説明していきます!
目次
.unique()と.nunique()
Seriesの関数です.よく使います.
これは名前のとおり, .unique() はそのSeriesでユニークな値のリストを返します. .nunique() はユニークな値の数です.
今回もタイタニックデータを使ってみましょう.(タイタニックデータについては第11回をご参照ください.)
|
1 2 3 |
import pandas as pd df = pd.read_csv('train.csv') df.head() |

|
1 |
df['Pclass'].unique() |
|
1 |
array([3, 1, 2]) |
|
1 |
df['Pclass'].nunique() |
|
1 |
3 |
こんな感じです.
あるデータをDataFrameとして読み込んだ際に,「このカラムはどんな値を保持するんだろう?」と思いますよね?例えば「本当にPclassは1, 2, 3しか値がないのだろうか?」と思うことがあると思います.そういうときにこれらの関数を使います.
.value_counts()
Seriesの関数です.それぞれの値に対していくつのレコードがあるのかをSeries形式で返してくれます.
|
1 |
df['Pclass'].value_counts() |
|
1 2 3 4 |
3 491 1 216 2 184 Name: Pclass, dtype: int64 |
.unique() よりもこちらの方が使うかな?自分はよくvalue_counts()だったかcount_values()だったかごっちゃになります.これは覚えるしかない気がします.
(超重要).apply()
超重要かつ頻出です.基本的にDataFrameの操作はapply関数で処理していくと言っていいと思います.
apply()関数を使って,DataFrameの全てのレコードに処理をして,その結果を別のカラムに格納することができます.
図で見た方がわかりやすいです.↓
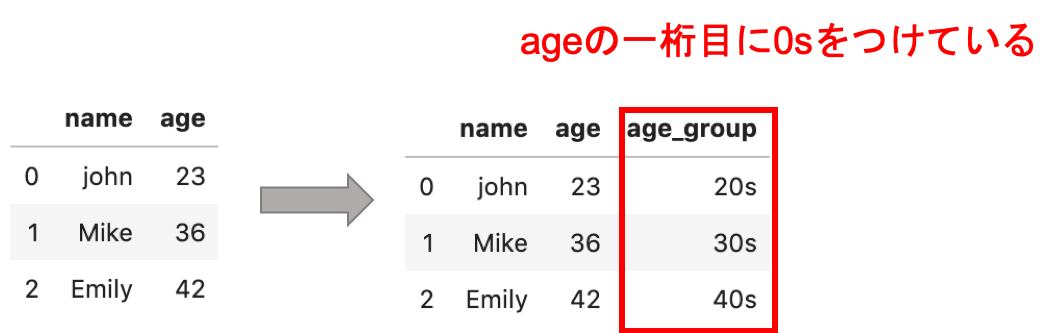
ageの一桁目に,「0s」をつけて「20s, 30, ,,」と,いう値を「age_group」という新しいカラムで持っています.
Excelでいうと,「数式」で同じことができると思います.Excelで頻繁で使う機能なので,当然Pythonでデータ処理する際も頻繁に使います.
これには .apply() という関数を使います.各行に処理をapplyするイメージですね.
それではまず,ageの値からage_groupの値を返す関数を作ります.
|
1 2 3 4 |
def get_age_group(age): return str(age)[0] + '0s' get_age_group(45) |
|
1 |
'40s' |
ageは数値なので str() でcastし,一桁目を取ってきます.(castやindexについては第3回参照)
その後 ‘0s’を + で繋いであげれば完成です.関数については第5回を参照ください.
この関数を .apply() に渡します. .apply() の使い方は,df[‘カラム名’].apply(function)です.そうすると,それぞれの行のカラムの値がfunctionの引数に入ります.
多分実際に実行して結果を見た方が早いです.以下のDataFrameを例に見てみます.↓
|
1 2 3 |
df = pd.DataFrame({ 'name': ['john', 'Mike', 'Emily'], 'age': ['23', '36', '42']}) df |

df[‘age’]にapply()を使ってみます.引数には先ほど作った get_age_group() を指定します.
|
1 |
df['age'].apply(get_age_group) |
|
1 2 3 4 |
0 20s 1 30s 2 40s Name: age, dtype: object |
するとSeriesが返ってきますね.index=0については’john’のageの「23」がget_age_group()の引数になり,「20s」の結果が入っています.同じくindex=1は’Mike’のageの36が引数になり,結果「30s」が入っています.
見慣れない使い方ですが,applyは本当によく使うので慣れる必要があります.
さて,apply()の返り値はSeriesなので,このSeriesを元のDataFrameに他のカラムで保存しましょう.
|
1 2 3 |
# 'age_group'カラムを新たに作り,結果を代入 df['age_group'] = df['age'].apply(get_age_group) df |

以上が .apply() の基本の使い方です.
しかし,これを応用した以下の二つの使い方も知っておく必要があります.
- lambda関数を使った.apply()の使い方
- 特定のカラムではなくレコード全体に対して使う.apply()の使い方
これだけだとなんのことかサッパリだと思います.それぞれ超わかりやすく解説します.
lambda関数を使った.apply()の使い方
先ほどの例のような「中身が一行で済む関数」を .apply() する場合,いちいち関数を作らずにlambda関数を使うことがあります.
...lambda関数ですよ!
覚えてますかね.第5回で紹介しました.忘れている人は戻って記事を読んでくださいw
それでは早速,先ほどのget_age_group()関数をlambda関数で表記してみます.lambdaではよく’x’をパラメータに使います.
|
1 2 3 4 |
# lambda関数を変数fに代入して f = lambda x: str(x)[0] + '0s' # 試しに43を入れてみる f(43) |
|
1 |
'40s' |
これを .apply() に入れます.変数なんぞは使わずに直接 .apply() にいれてしまうのが一般的です.
|
1 |
df['age_group'] = df['age'].apply(lambda x: str(x)[0] + '0s') |
慣れてくると,一発でこの一行を書けるようになります.Step By Stepに説明したかったので回りくどくなってしまいましたが, df['age_group'] = df['age'].apply(lambda x: str(x)[0] + '0s') が今回やりたかったことの正解のコードでありベストプラクティスといえます.
そして,apply()を使う多くのケースがlambda関数で済ませれることが多いです.例えばageの二倍を他のカラムにするとか,nameのイニシャルをとるとか.Excelでもそうですよね?一行の数式で書けるものばかりです.
さらにいうとlambda関数はほとんどこの.apply()でしか使いません(私だけ?).なのでこのdf[‘カラム名’].apply(lambda x: )の形で覚えるといいと思います.
レコード全体に対して使う.apply()の使い方
上の例は,各レコードの’age’カラムの値に対して処理をした結果を返していました.
しかし,レコード全体で処理をしたいケースというのが多々あります.例えば,以下のようなデータを作りたいとき↓
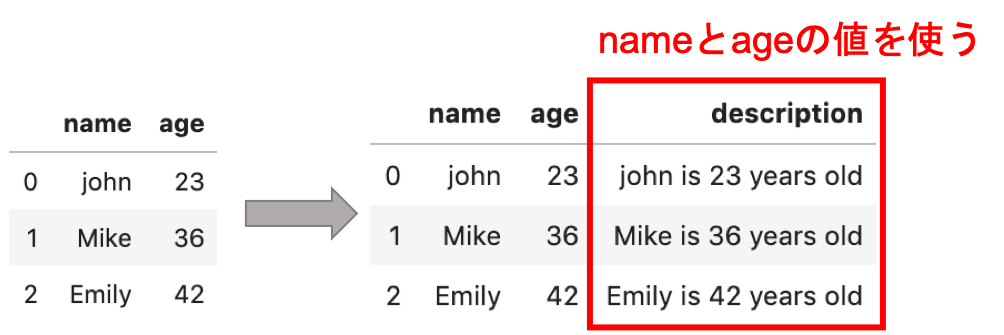
ここではレコードのnameとageの値を使って’description’というカラムに新たな値を入れています.
これはSeriesではなく,DataFrameの.apply(axis=1)を使うことで実現可能です.
先ほどのdf[‘カラム名’].apply()では,df[‘カラム’]はSeriesなのでSeriesの.apply()を使っていることになります.
そうではなくて,DataFrameの.apply()関数,つまりdf.apply()とすることでレコード全体を引数にとることができます.
また,行に対してapplyする場合,axis=1を指定する必要があります.これ,忘れがちなので覚えておきましょう!デフォルトはaxis=0で,axis=0はカラムに対してapply(つまり上述した例)します.
実際に見た方が早いです.上の図の例は以下のように書けます.
|
1 2 3 4 |
df = pd.DataFrame({ 'name': ['john', 'Mike', 'Emily'], 'age': ['23', '36', '42']}) df['description'] = df.apply(lambda row: '{} is {} years old'.format(row['name'], row['age']), axis=1) df |
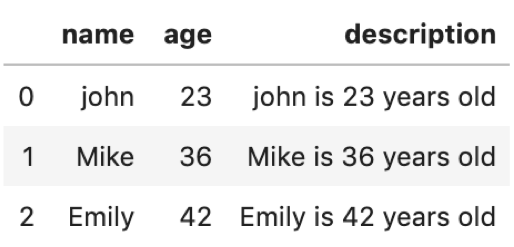
今回も一行で書けちゃうので早速lambda関数を使ってます.lambda関数のパラメータをxではなくrowとすると,読みやすい気がします.パラメータrowには各レコードのSeriesが格納されます.
こちらもかなり使う書き方なのでぜひ使えるようにしましょう!
まとめ
- pd[‘カラム名’].unique()でユニークな値をNumPy Arrayで返す
- pd[‘カラム名’].nunique()でユニークな値の数を返す
- pd[‘カラム名’].value_counts()でそれぞれの値に対しいくつのレコードがあるかをSeriesで返す
- pd[‘カラム名’].apply(func)で各レコードの指定したカラムの値に対して処理を行う
- pd.apply(func, axis=1)で各レコードに対して処理を行う
- .apply()に指定する関数が一行で書けるときlambda関数で済ます
結構盛りだくさんでしたね...
今は覚えることが多すぎてToo Muchな感じかもしれませんが,今日紹介した関数はデータを解析する上で必ず使う関数です.
何度も本ブログを読んで反復練習することをお勧めします.
それでは!
追記)次回の記事書きました!
データサイエンスのためのPython入門18〜DataFrameのその他頻出関数(to_csv, iterrows, sort_values)を解説〜