こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第16回です.(講座の目次はこちら)
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
今日は,テーブル結合について話をします!複数の表形式のDataFrameを結合させます.こちらもデータサイエンス必須操作になるのでちゃんと理解して覚えたいところです.
目次
表の結合とは?
表の結合とは,大きく二つあります.
- 特定のカラムやindexをKeyにして結合する
- DataFrameを単純に横に(もしくは縦に)結合する(ガッチャンコさせる)
言葉で説明するの難しいですねw 以下の例をみてください.
- 特定のカラムやindexをIDにして結合する
|
1 2 3 4 5 6 7 8 |
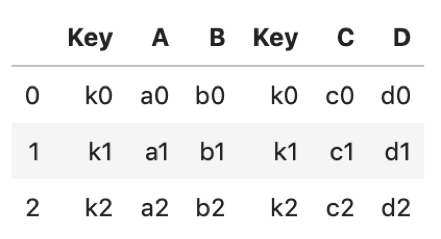
import pandas as pd df1 = pd.DataFrame({ 'Key': ['k0', 'k1', 'k2'], 'A': ['a0', 'a1', 'a2'], 'B': ['b0', 'b1', 'b2']}) df2 = pd.DataFrame({ 'Key': ['k0', 'k1', 'k2'], 'C': ['c0', 'c1', 'c2'], 'D': ['d0', 'd1', 'd2']}) |
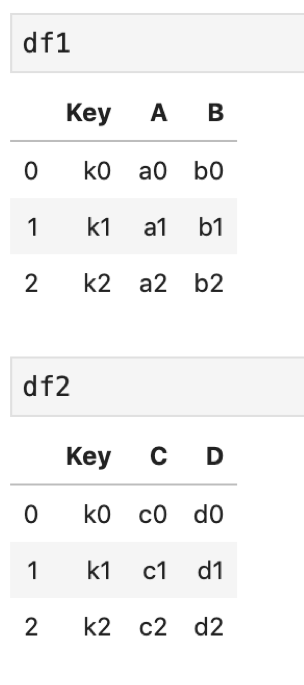
↑こんな二つのDataFrameを使って解説します.どちらも’Key’というカラムを持っていて,その値はどちらも同じです.他のカラムはそれぞれ別の値を持っています.
この’Key’というカラムをKey(キー)にして二つのDataFrameを横に結合します.結合には .merge() を使います.
|
1 |
df1.merge(df2) |

これだけだったら簡単ですよね.しかし,実際に業務でmergeを必要とする場面では様々なケースがあり,結構複雑になります.
本記事では,色々なパターンについて紹介していきます.
- DataFrameを単純に横に(もしくは縦に)結合する(ガッチャンコさせる)
ガッチャンコさせるには .concat() という関数を使います.そうです.前回の記事でやったやつです.concatenateの略です.
|
1 2 |
# 縦 pd.concat([df1, df2], axis=0) |
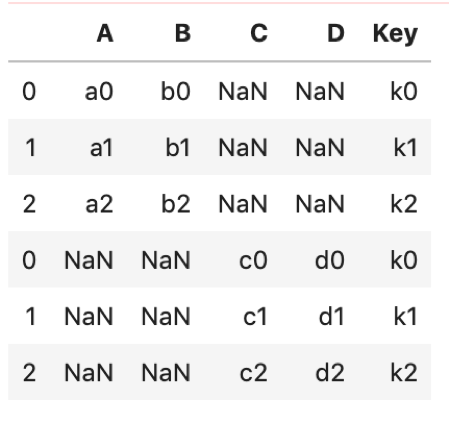
|
1 2 |
# 横 pd.concat([df1, df2], axis=1) |
縦につなげる方が圧倒的に多い気がします.横につなげるケースってあんま出会ったことないですね.あと,デフォルトはaxis=0です.
前回の記事の「(上級者向け)groupbyの結果をfor文でまわす」で使ったように,一つのDataFrameを縦に分割して,それぞれ処理して縦に結合という使い方をよくします.
また,mergeとconcatでは圧倒的にmergeの方が出てきます.
今回の記事ではmergeについて深掘りをしたいと思います.なお,mergeもconcatも元のDataFrameを更新しないので,新たな変数か元の変数に再代入してください.
.merge()の使い方をマスターする
.merge() にはいくつか重要な引数があって,これらを覚えておかないと使えません.重要なのは以下の引数です.(引数の確認はJupyterで,関数のあとにShift+Tabで確認しましょう.詳細は第2回へ)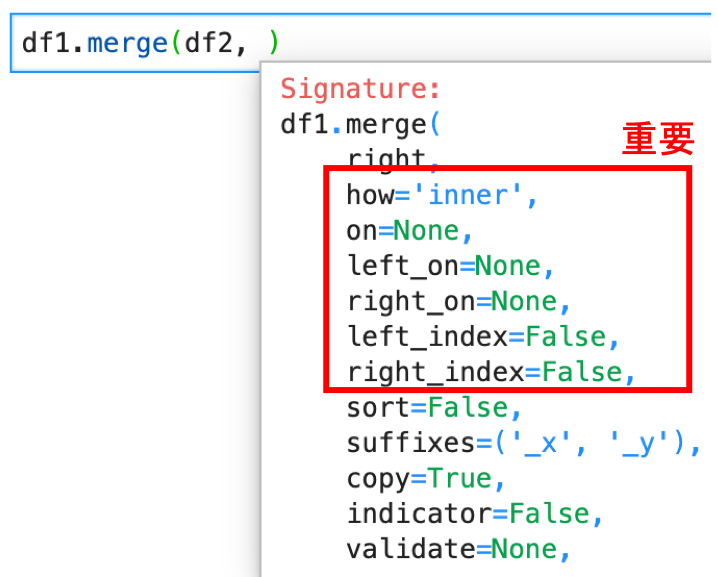
- how : どう結合するか→{‘left’, ‘right’, ‘outer’, ‘inner’}, デフォルトは ‘inner’
- on : keyにするカラムを指定(どちらのDataFrameにも存在するカラム).指定をしないと共通のカラムで結合される
- left_on:leftのDataFrameのkeyにするカラム
- right_on:rightのDataFrameのkeyにするカラム
- left_index:leftのKeyをindexにする場合Trueを指定
- right_index:rightのKeyをindexにする場合Trueを指定
まず,.merge()の基本的な使い方を説明します.基本かつ重要な考え方として,左の表に右の表をくっつけるイメージを持ってください.
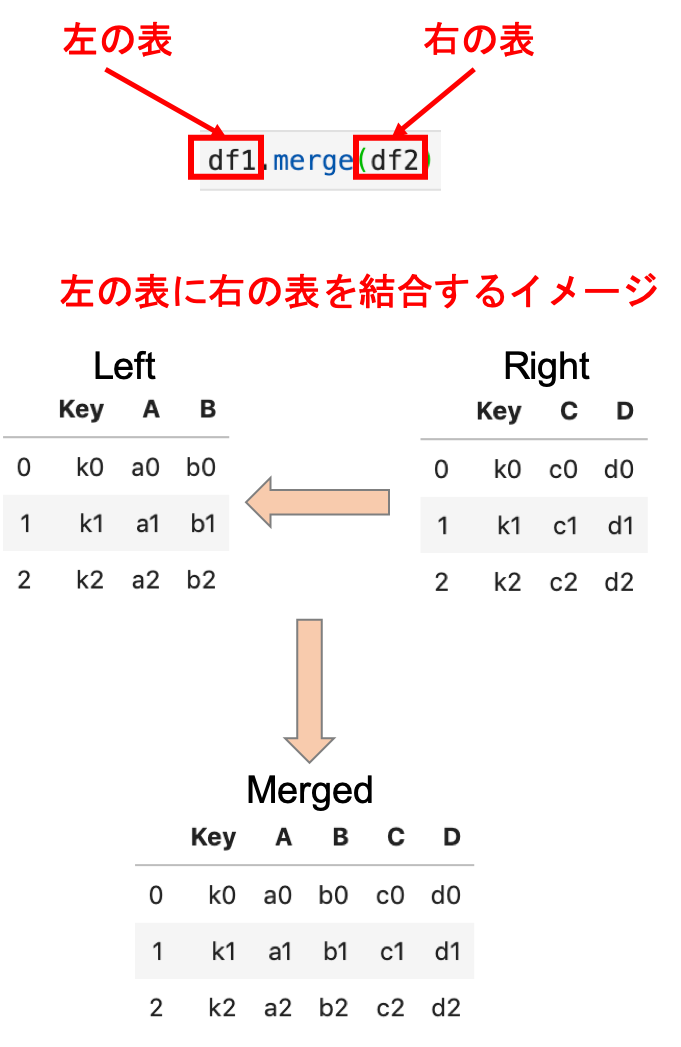
なぜこの考えが重要なのかについては下の説明を読み進めるとわかります.
how
「それをどうやってやるのか」を指定するのがhow引数です.
howには4つあっって, {‘left’, ‘right’, ‘outer’, ‘inner’}の中から選びます.デフォルトだとinnerになります.
SQLの経験がある人には説明は不要だと思いますが,以下それぞれ説明します.
- ‘left’ と ‘right’
‘left’や’right’は,’left’の表(もしくは’right’の表)をベースに,紐づくright(もしくはleft)のレコードだけmergeする,いわゆるSQLでいうleft outer, right outerです.
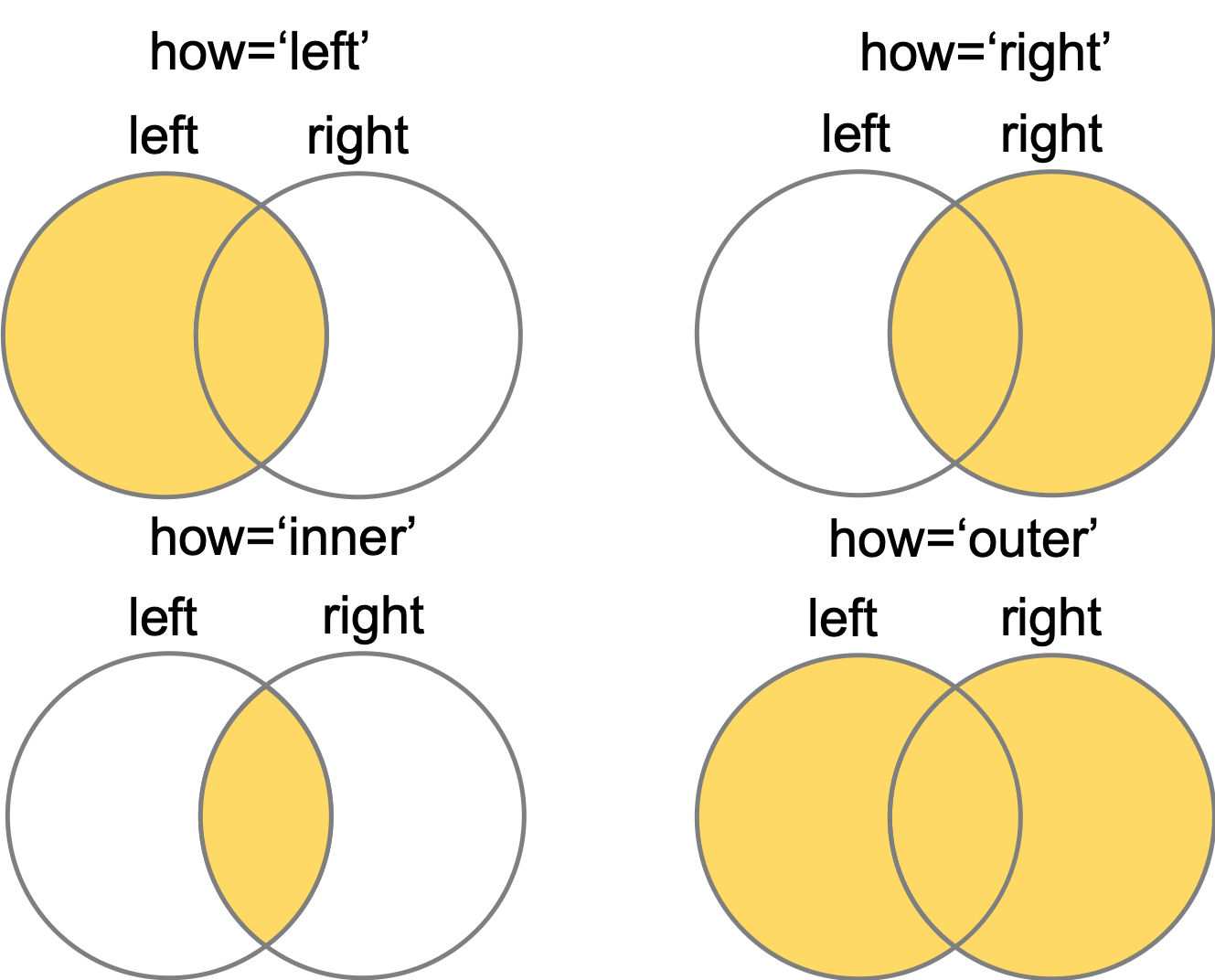
ベン図で説明すると以下感じ
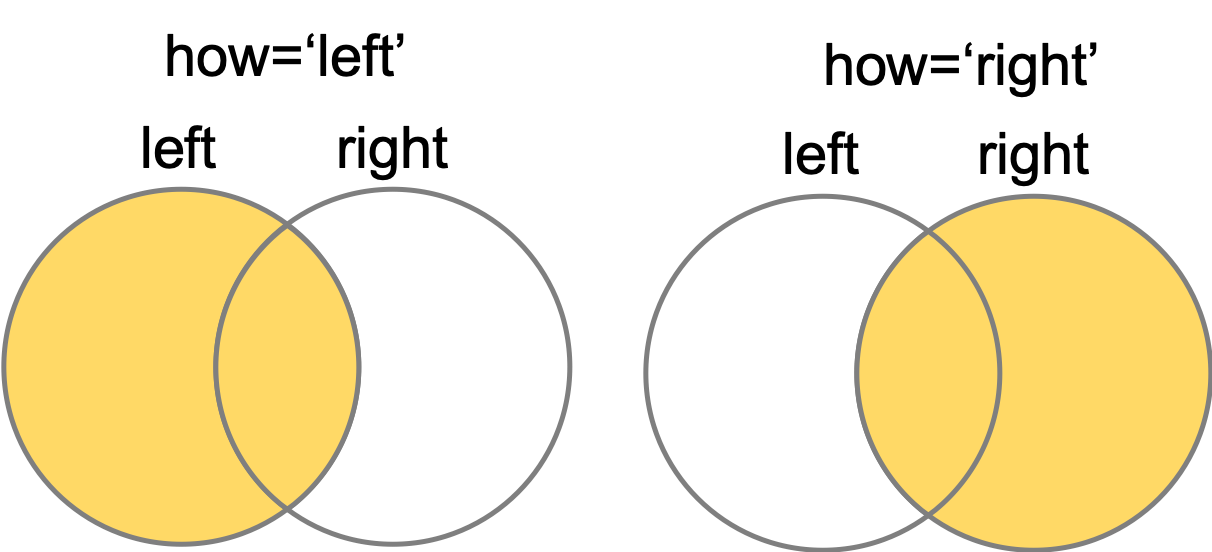
しかし,「左の表に右の表をくっつけるイメージ」を持つので,基本leftのみを使いましょう.rightを使いたいのであればそもそもの左右の表を入れ替えるべきです.「rightは一応用意されているが使わない」と考えるとシンプルに考えることができて覚えやすいと思います.
例えば以下の例をみてみます.
|
1 2 3 4 5 6 7 |
df1 = pd.DataFrame({ 'Key': ['k0', 'k1', 'k2'], 'A': ['a0', 'a1', 'a2'], 'B': ['b0', 'b1', 'b2']}) df2 = pd.DataFrame({ 'Key': ['k0', 'k1', 'k3'], 'C': ['c0', 'c1', 'c3'], 'D': ['d0', 'd1', 'd3']}) |

|
1 |
df1.merge(df2, how='left') |
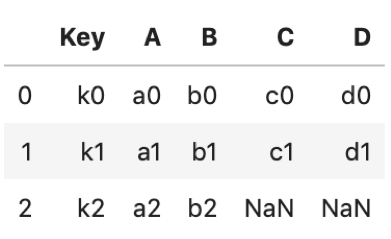
df1をleftに,df2をrightにしました.rightの表には’k2’がありません.なので’k2’のC, DはNaNが入ります.leftの表のレコードは失われないイメージで行いましょう.
- ‘outer’
‘outer’を指定すると,leftもrightもレコードを失わず,対応が見つからない行にはNaNが入ります.
ベン図でいうとこんな感じ↓

さっきの例のDataFrame, df1とdf2をouterで繋いでみましょう.
|
1 |
df1.merge(df2, how='outer') |

left(df1)もright(df2)もどちらもレコードを失うことなく,結合できるレコードは結合し,そうでないところはNaNで埋めているのがわかります.
- ‘inner’
”inner’を指定すると,leftとrightで結合できるレコードのみが残ります.なお,デフォルトはinnerです.
ベン図でいうと↓
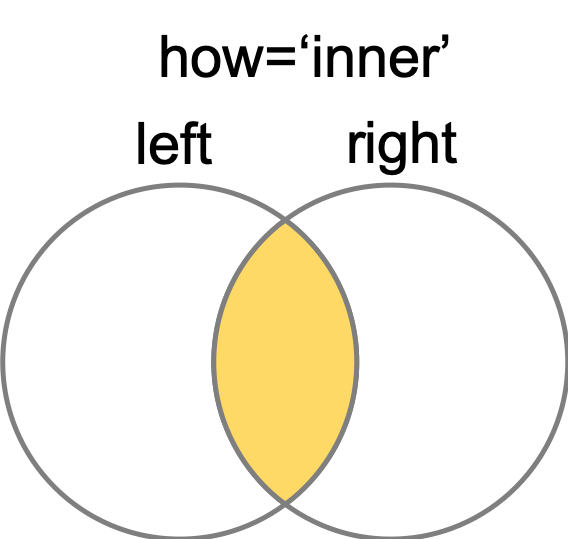
|
1 |
df1.merge(df2, how='inner') |

実際業務で結合する場合の多くが「大きな表に,小さな表を結合する」ケースです.
どういうことかというと,例えば前回まで使っていたタイタニックのデータに対して,追加のデータとしてIDと他の情報(例えば英語を喋るか喋らないかのフラグなど,なんでもいいですが)を付け加えるケースです.
実業務ではほとんどがこのケースです.その追加のデータは,追加のカラム情報かもしれませんし,自分で加工して作ったデータかもしれません.
そのため,基本の考えとして「ベースの表を左において,追加の表を右から左にmergeするイメージ」が重要になってきます.
よく使うのは’left’と’inner’です.ベースの表と追加の表の過不足がないことがわかっていればinnerを使うし,追加の表がベースの表より足りないケースは’left’を使います.
on
引数onは,結合するときにどのカラムをKeyにして結合するかを指定します.leftの表もrightの表もどちらにもあるカラムしか指定できません.
なお,共通のカラムがある場合はなにも指定しなくてもそのカラムがKeyとなり結合されます,が,基本は指定しましょう.わかりやすいし安全です.「予期せぬカラムで結合してた」ということもよくあります.複数の共通カラムがある場合は,どのカラムで結合されるかわからないですし,たとえ一つしか共通カラムがない場合でも指定するのがいいと思います.(今までの例はonの説明前だったので意図的にon引数を指定せずに書いてました.)
indexをKeyにする場合は後述のright_index, left_indexをTrueにします.また,それぞれの表(DataFrame)のカラム名が異なる場合は後述のleft_on, right_onを指定します.
最初は色々あってややこしいと思いますが,すぐ慣れますよ!
では,以下のDataFrameを例にみてましょう
|
1 2 3 4 5 6 7 8 9 |
df1 = pd.DataFrame({ 'Key': ['k0', 'k1', 'k2'], 'ID': ['aa', 'bb', 'cc'], 'A': ['a0', 'a1', 'a2'], 'B': ['b0', 'b1', 'b2']}) df2 = pd.DataFrame({ 'Key': ['k0', 'k1', 'k3'], 'ID': ['aa', 'bb', 'cc'], 'C': ['c0', 'c1', 'c3'], 'D': ['d0', 'd1', 'd3']}) |
それぞれのDataFrameに共通するカラムが二つあります.KeyとIDです.
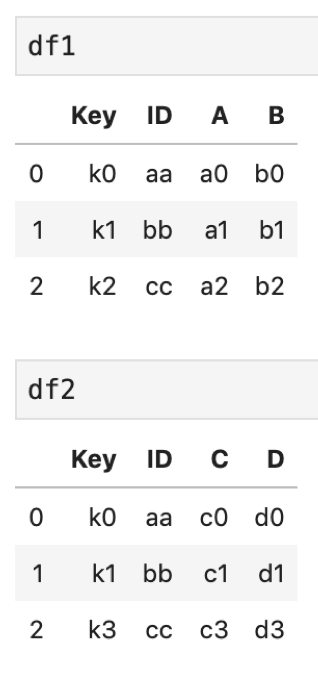
KeyとIDをそれぞれ引数onに指定して結合してみます.
|
1 2 |
# KeyカラムをKeyにして結合 df1.merge(df2, on='Key') |

|
1 2 |
# IDカラムをKeyにして結合 df1.merge(df2, on='ID') |
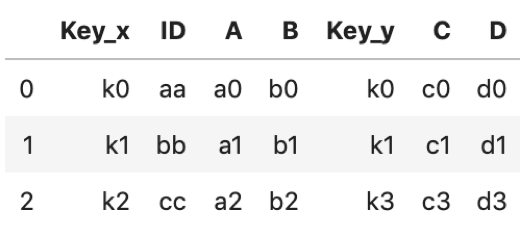
簡単ですね.なお,Key以外の両DataFrameにもあるカラムは_xおよび_yのsuffixがつきます.これを変更したいときは多々ありますが,suffixes引数にタプルでいれてあげればOKです.
|
1 2 |
# suffixesを指定する df1.merge(df2, on='ID', suffixes=('_left', '_right')) |

left_on, right_on
Keyにしたいカラム名がleftとrightで異なるとき,この引数を指定します.簡単ですね.
以下の例をみてみましょう.
|
1 2 3 4 5 6 7 |
df1 = pd.DataFrame({ 'Key1': ['k0', 'k1', 'k2'], 'A': ['a0', 'a1', 'a2'], 'B': ['b0', 'b1', 'b2']}) df2 = pd.DataFrame({ 'Key2': ['k0', 'k1', 'k3'], 'C': ['c0', 'c1', 'c3'], 'D': ['d0', 'd1', 'd3']}) |
Key1とKey2をKeyにしたいのですが,それぞれカラム名が違います.この場合引数onに指定できないのでleft_onおよびright_onを指定します.
|
1 2 |
# suffixesを指定する df1.merge(df2, left_on='Key1', right_on='Key2') |
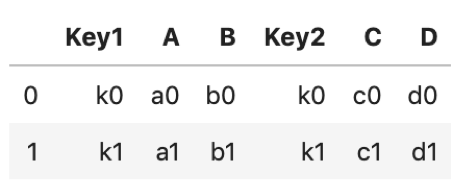
なにも難しいことはないですね.これは結構でてきます,が,カラムが増えると管理できなくなるので,できるだけ同じ名前で管理したほうが無難です.
...とはいったものの,違う意味のカラムでKeyにできるケースもあるとおもうのでその場合は無理にカラム名を変えずにleft_on,right_onを使いましょう.
left_index, right_index
カラムではなくIndexをKeyに指定したい場合,left_index, right_indexにTrueを指定します.個人的にはわかりにくいのであまり好きではないです.Indexって途中で振り直したりもするので必ずしも一意とは限らないんですよね.
とはいったものの,データが小さかったりわざわざKeyカラムを作る必要もない場合には使ったりするので覚えておきましょう.また,indexが数字でなくてIDなどを降っている場合も使います.
先ほどのdf1, df2を例にします.
|
1 |
df1.merge(df2, left_index=True, right_index=True) |
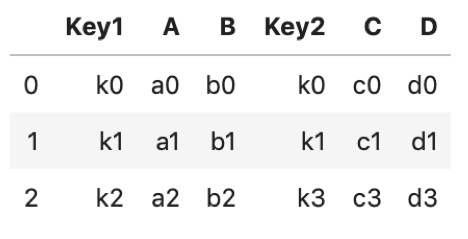
同じindexのレコード同士で結合されているのがわかります.
joinとの違い
実は,DataFrameにはjoin関数というものがあります.join関数を使うとindexで結合してくれますが,mergeでもほぼ同じことができるので覚える必要はないと思います.(私は多分一度も開発で使ったことないですし,使ってる人みたことない・・・)
もし今後,DataFrameの結合の仕方で「join」に出会っても,「joinはmergeと同じだから無視してOK」と覚えてしまっていいと思います.
一応例です.↓
|
1 2 3 4 5 6 7 |
df1 = pd.DataFrame({ 'Key1': ['k0', 'k1', 'k2'], 'A': ['a0', 'a1', 'a2'], 'B': ['b0', 'b1', 'b2']}) df2 = pd.DataFrame({ 'Key2': ['k0', 'k1', 'k3'], 'C': ['c0', 'c1', 'c3'], 'D': ['d0', 'd1', 'd3']}) |
|
1 |
df1.join(df2) |
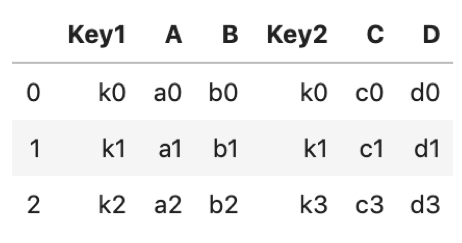
|
1 |
df1.merge(df2, left_index=True, right_index=True) |
- joinを使って複数のDataFrameを結合することが可能
複数のDataFrameを一気に連結できます.が,これはオススメしません.バグのもとになりやすいですし,コードが読みにくくなります.できれば一つ一つ結合することをオススメします.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
df1 = pd.DataFrame({ 'Key1': ['k0', 'k1', 'k2'], 'A': ['a0', 'a1', 'a2'], 'B': ['b0', 'b1', 'b2']}) df2 = pd.DataFrame({ 'Key2': ['k0', 'k1', 'k3'], 'C': ['c0', 'c1', 'c3'], 'D': ['d0', 'd1', 'd3']}) df3 = pd.DataFrame({ 'Key3': ['k0', 'k1', 'k4'], 'E': ['c0', 'c1', 'c3'], 'F': ['d0', 'd1', 'd3']}) df1.join([df2, df3]) |

一応紹介まで.
まとめ
今回はテーブル結合で使う関数,mergeとconcatについて学びました.
- pd.concat([df1, df2] axis=0)で縦につなげる(よく使う)
- pd.concat([df1, df2] axis=1)で横につなげる
- df1.merge(df2)でカラムやindexをキーにして結合する
- 左の表に右の表をくっつけるイメージでやるとわかりやすい
- joinは使わない.mergeだけで同じことができる
テーブル結合は,データ解析で必ずといっていいほど出てくる頻出操作です.特にhowの種類がごっちゃになって混乱するかもしれませんが,基本は「左の表」←「右の表」のイメージを持つとわかりやすいです.大抵’left’か’inner’のどちらかしか使わないと思います.
あと,引数onはなるべく明記してくださいね!他の人がコードを読むときにわかりやすいので!
それでは!
次回記事書きました.↓DataFrameの重要な関数を紹介します.とくにapply関数は超重要です.めちゃくちゃわかりやすく説明するので是非読み進めてください!
データサイエンスのためのPython入門17〜DataFrameの重要関数(apply, unique, value_counts)を超わかりやすく解説〜