こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門19回目です(講座の目次はこちら).ついに,,ついに,DataFrame最終回を迎えます(いえーいっ!!)
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
今回はそこまで使用頻度は高くないですが,時々必要になるので覚えておきたい関数二つ
- .pivot_table()
- .xs()
を紹介します.
あまり使わないので忘れがちですが,「存在」を覚えておけば必要なときにググって使えるので知っておきましょう.
目次
.pivot_table()でピボットテーブルを作成
名前の通りなんです.新入社員がExcelで最初にぶち当たる「あの」ピボットテーブルをDataFrameでも作ることができます.
ピボットテーブルってなんだっけ?という人は,普段ピボットテーブル使ってない人だろうから今はこの説明だけ読んでなんとなくわかればいいと思います.正直データサイエンスではあまり使わないと思います.
普段集計処理とかでピボットテーブル使う人は,Pythonでも同じことをやりたくなると思うので自分でも試してください.
以下のサンプルを例にしてみます↓
|
1 2 3 4 5 6 |
data = {'Date':['Jan-1', 'Jan-1', 'Jan-1', 'Jan-2', 'Jan-2', 'Jan-2'], 'User':['Emily', 'John', 'Nick', 'Kevin', 'Emily', 'John'], 'Method':['Card', 'Card', 'Cash', 'Card', 'Cash', 'Cash'], 'Price':[100, 250, 200, 460, 200, 130]} df = pd.DataFrame(data) df |
このような「ユーザの支払いのトランザクション」を記録したデータがあるとします.
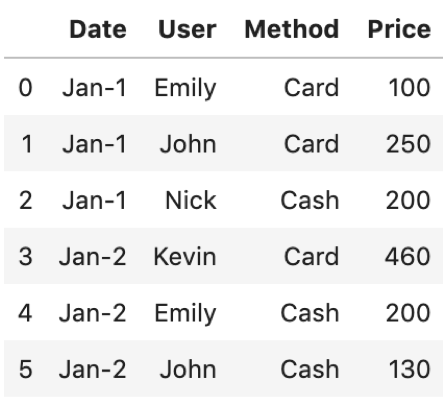
いつ誰がどの方法でいくら払ったかが記されています.よくあるデータだと思います.
pivot_tableを使うと,簡単に集計することができます.主にvalues, index, columnsの三つの引数をいれてピボットテーブルを作ります.
valuesには,集計したいカラムを入れます.今回ではPriceです.
indexとcolumnsはそれぞれ好きなようにカラムをリスト形式で指定します.今回は試しにDateとUserをindexに,Methodをカラムに指定してみます.
|
1 |
df.pivot_table(values='Price', index=['Date', 'User'], columns=['Method']) |
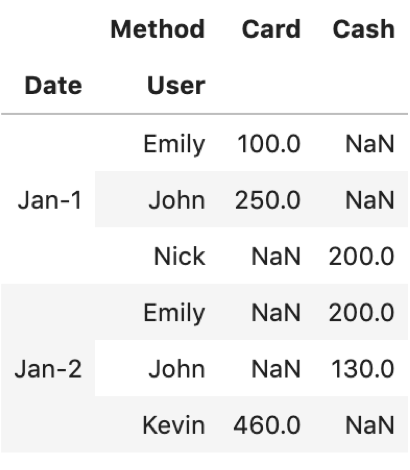
こんな感じになります.もしピボットテーブルに慣れてない人は「??」って感じかもしれませんが,よーく考えるとやっていることは簡単ですよ
まず,それぞれのセルに入るのがvaluesで指定した値(今回ではPrice).集計したいカラムです.
それに対してindexとcolumnsをそれぞれ指定したいカラムをリストで渡すだけ.
試しにUserとMethodを入れ替えてみましょう.
|
1 |
df.pivot_table(values='Price', index=['Date', 'Method'], columns=['User']) |
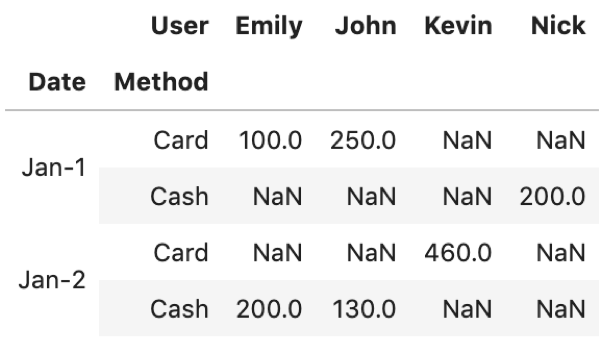
こんな感じです.簡単ですよね?
最初に「どのカラムを集計したいのか」を明確にしてそのカラムをvaluesに入れてしまえばあとは欲しい情報をindexとcolumnsに入れていくだけです.
もし,これでも難しいと感じるようであれば,今はわからなくても構わないと思います.実際のデータで,はこのように綺麗にピボットできるケースは少なく,なにかしら関数を作って.applyや.iterrowsで回すほうが圧倒的に多いです.
.xs()でcross-section操作
.xs() はcross sectionの略です.これもあまり使いませんが,ピボットのような複数のindexをもったDataFrameを操作する際に重宝します.ピボットと合わせて覚えておくといいでしょう.さて,この .xs() は何をするときに必要かというと,先ほどのピボットテーブルで,例えば「Card」の行だけうまく抜き出したいときに使います.(まさにcross-section!)
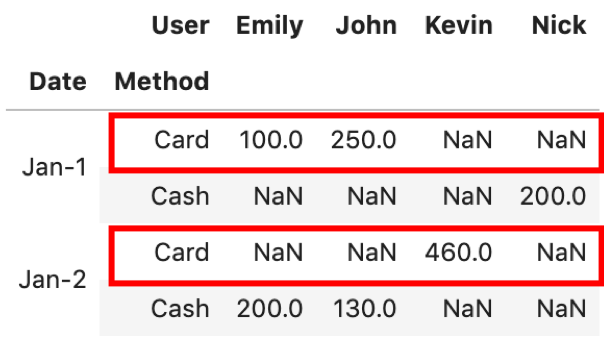
例えば’Jan-1’の行だけ取りたければ第12回で紹介した .loc[] で取れますよね
|
1 2 |
pivot = df.pivot_table(values='Price', index=['Date', 'Method'], columns=['User']) pivot.loc['Jan-1'] |
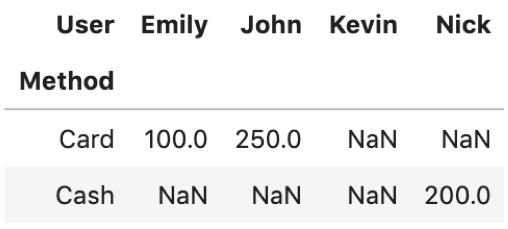
しかし, pivot.loc['Card']はエラーになります.試してみてください.(Dateに’Card’なんてのは無いからです.)
そこで,Cardの行だけDateを横断して取って来たいときに.xs()を使います.取ってくる値と,levelを指定します.
|
1 |
pivot.xs('Card', level='Method') |
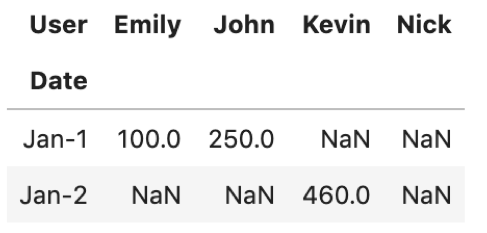
これでCardのレコードをDateを横断して取ってこれました!
簡単ですね〜.levelは一番左(今回ではDate)がデフォルトで指定されます.つまり, .loc[] と同じですね.
まとめ
今回はピボットテーブルとそれを操作するのに使えるcross-section操作について紹介しました.
あまり出番はないかもしれませんが,頭の片隅に記憶しておいてくださいw
たまーーーーーに必要になります.「どうしてもピボットじゃないとできない!」というときも出て来ますので.
その時はぜひこのページに戻って来て,使い方をおさらいしましょう.存在を知っていることが重要ですね.
今回でPandas編は終わりです.PandasはPythonのデータサイエンスの要であり,データ処理をする上で必須ツールです.
本連載で紹介した内容はどれも私が業務で毎日使っているものばかりです.何度もブログを読んで,自分でDataFrameを作って色々な操作をしてみてください.
Get your hands dirty!!
次回からまた新たなライブラリを使います.グラフや画像を描写するのに使うmatplotlibというツールを紹介していきます.
データサイエンティストの腕の見せ所は,いかにデータをわかりやすく可視化できるかです.超重要です.
そのためのツールの基本的な使い方をレクチャーしていくのでお楽しみに!データの可視化はやっててめちゃくちゃ楽しいですよ!
それでは!
追記)次回の記事書きました!データ可視化につかうmatplotlibを紹介します!
データサイエンスのためのPython入門20〜matplotlibを使ってData Visualizationを始めよう〜