こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第26回です(講座の目次はこちら).今回はSeabornを使ってHeatmapを描画していきます.
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
・・・Heatmap??
実はこれ,統計学・機械学習でめちゃくちゃ使うplotです.というか,統計学・機械学習のために作られた図と言っても過言では無いです.(いやそんなことはないと思うけど)
どんなグラフかというと,表データの値をそのまま色づけした図です.
わかりますか?図の右側にあるゲージの通り,-1~1の数値に対して青⇄赤のグラデーションで表示しています.このような図を一般的にHeatmapと呼びます.
この図,データサイエンスではよく使う図なんです.
特に各カラム間の相関を示す相関表(Correlation Matrix)や,混同行列(Confusion Matrix)でよく使います.Correlation MatrixやConfusion Matrixは,データサイエンスで頻出の表なのでこのHeatmapもよく使います.
今回は,カラム間の相関を表す相関表(Correlation Matrix やCorrelation Tableと言います)を例に解説していこうと思います.
混同行列(Confusion Matrix)については今後の機械学習講座にて触れていこうと思います.今はなにかわからなくてOKです.
とにかく,データサイエンスではこのような「各カラム間で持つ値を表にする」ことが多く,SeabornのHeatmapで可視化すると一目でどのカラム間の値が低いか・高いかがわかるので便利なんです.
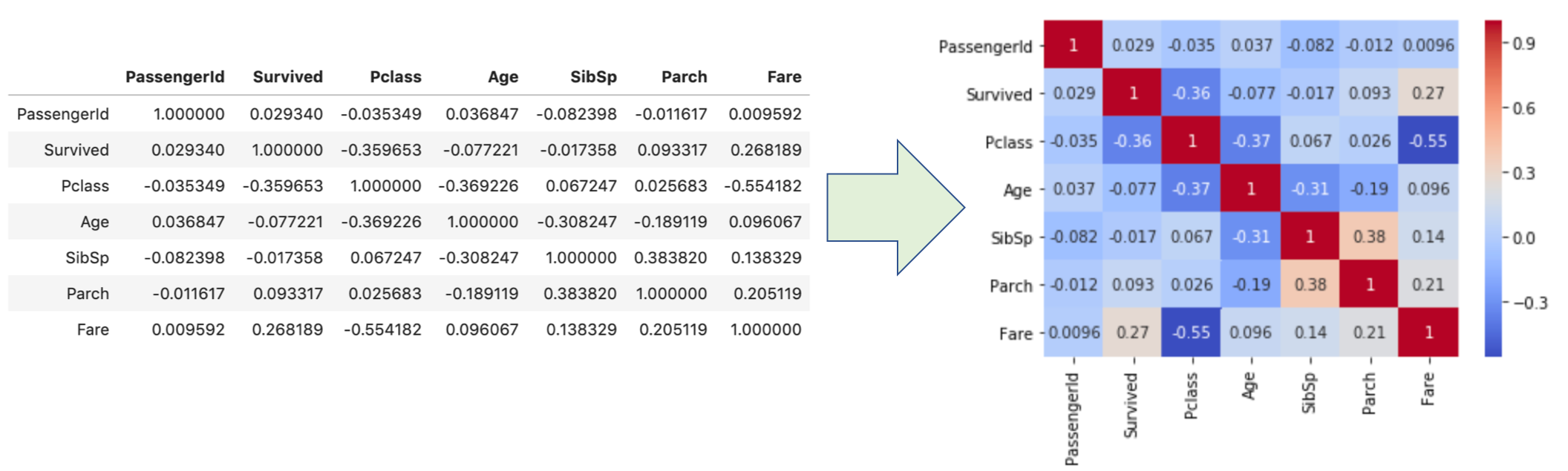
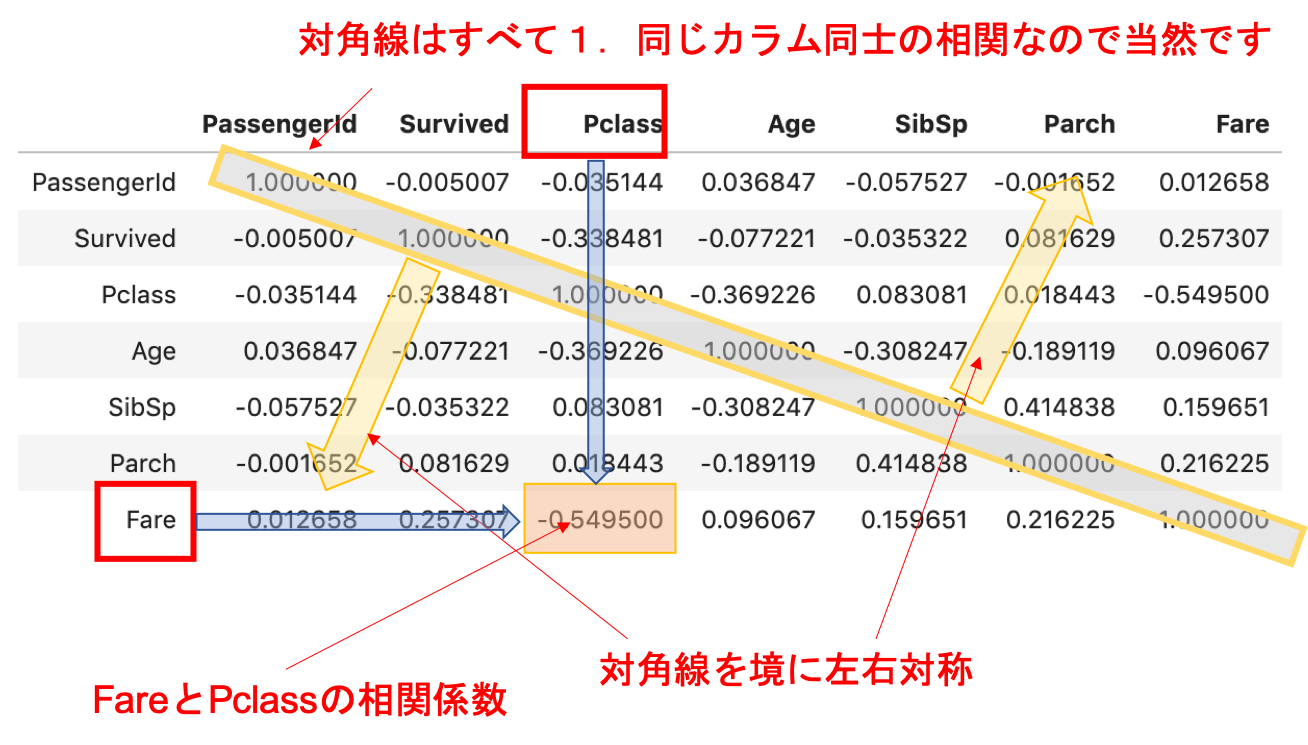
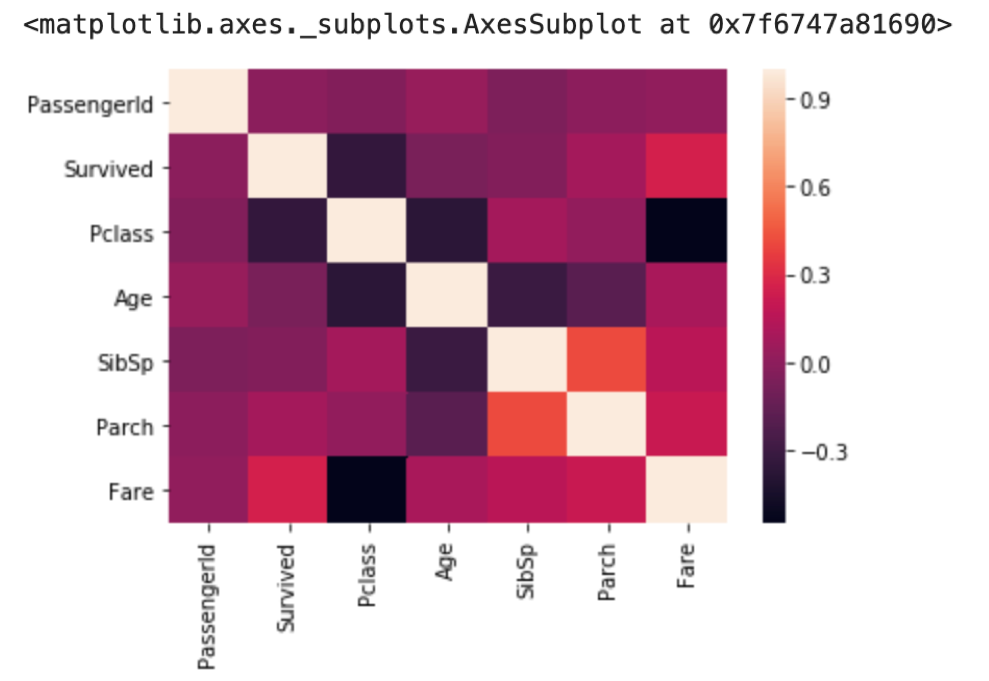
たとえば,上の例はタイタニックデータの相関表(相関表については後述します.)ですが,当然同じカラム同士の相関は1なので対角成分は全て1でそれを境に対照的な値を取っています.
相関というのは,カラム間の関係の強さを表します.上の表にある-1から1の数字は相関係数と呼ばれるもので,相関の強さを表す係数です.例えば「’年齢’があがるにつれ’身長’が高くなる」データがあったとしたら,「’年齢’と’身長’には正の相関関係がある」と言え,正の相関係数になりす.その強さを相関係数で数学的に示すことができます.逆に「’年齢’があがるにつれ’髪の毛の量’が減る」のであれば「’年齢’と’髪の毛の量’には負の相関関係がある」と言え,相関係数は負の値になります.うー怖い.
このHeatmapを見れば,FareとPclassの間に比較的高い負の相関が,SibSpとParchの間に比較的高い相関があるのがわかります.
また,タイタニックデータで気になるのはSurvivedとの相関関係ですよね?SurvivedとFare,SurvivedとPclassでそれぞれ比較的高い相関があると言えそうです.
この0.2とか0.3の相関係数が,相関が「強い」のかどうかは実際のところこれだけだとわかりません .これを確認するには実際に散布図を見るのが一番ですが,個人的には相関係数が0.2~0.4程度だと,強いとは言えず,「弱いけど相関がある」程度です.なので,「比較的」という言い方をしてました.また,相関係数だけをみるとミスリーディングになるので注意です.正の相関と負の相関が相殺して相関係数が0になるケースもあります.「相関係数が0だから相関がない」ということにはなりません.
・・・説明長っ
やはり統計の話をすると説明が長くなってしまいますね...(んー今後どうするか考えないと
相関に関しては本当に世の中誤解してる人が多いので説明が増えてしまいます.例えば相関を因果関係と勘違いする人とか
「テレビゲームのプレイ時間」と「犯罪率」とかね.これの相関が高いからって「テレビゲームが原因で犯罪率があがる」わけではないので「犯罪率を下げるためにテレビゲームの時間を少なくする!」というのはロジックが飛んでいるわけです.どこぞやの大統領とかw
それでは,実際にSeabornを使って,Heatmapを描画してみましょう! (もちろん,めちゃくちゃ簡単にできます)
目次
df.corr()で相関表を作る
DataFrameで相関表を作るには, .corr() 関数をコールするだけです.
めっちゃ簡単でしょ?
今回もタイタニックデータを使って相関表を作ってみましょう!タイタニックデータについては第11回を参照ください.
|
1 2 3 4 |
import pandas as pd df = pd.read_csv('train.csv') corr = df.corr() corr |
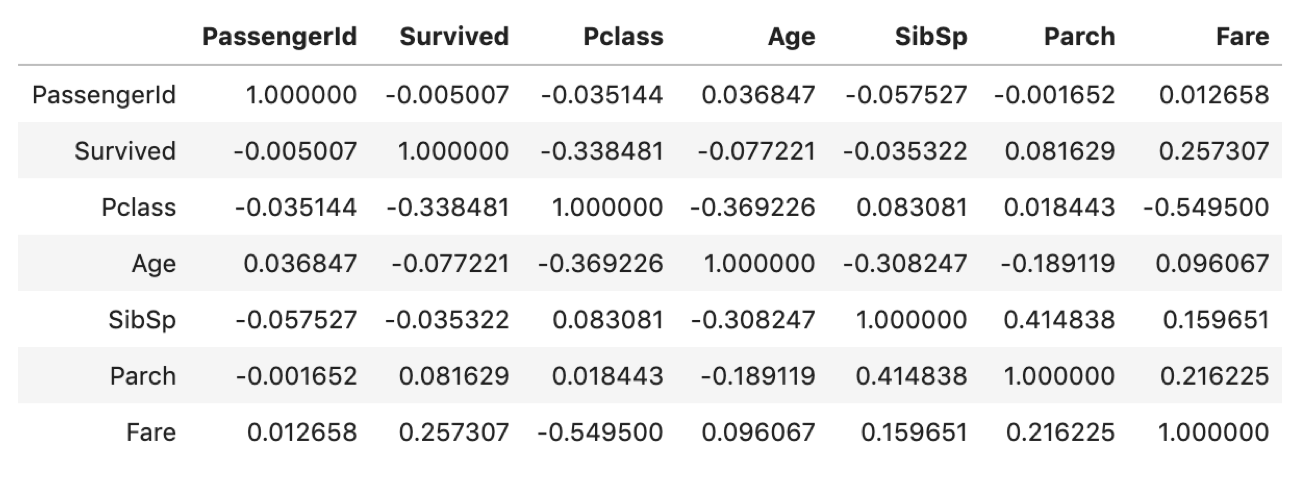
めちゃくちゃ簡単ですよね,こんなに簡単に相関表を作れちゃいます.(タイタニックデータではPassengerIdが数値で保存されているので相関表に出ていますが,それについては後述)
見方は先ほど説明した通りですが,各カラム間の相関を-1~1の相関係数で表しています.相関係数の数学的定義は今回は割愛します.今後の統計講座で扱っていきます.(追記)統計講座第11回から相関係数についてわかりやすく説明しています.是非チェックしてください!
sns.heatmap()でHeatmapをplot
では,実際に先ほどの相関表の corr のHeatmapをplotしてみようと思います.
と言ってもさすがSeaborn,たった一行でできちゃいます.sns.heatmap()にDataFrameを入れるだけです.
|
1 |
sns.heatmap(corr) |
第一回の通りに環境構築していると もしかするとHeatmapが正しく表示されないかもしれません.現時点での最新版のmatplotlib(vestion 3.1.1)ではHeatmapはうまく動かないそうです.その場合,Dockerのコンテナに入り$pip install matplotlib==3.1.0を実行し,matplotlibをダウングレードしてください.
コンテナへはDocker超入門第3回にて説明した通り,$docker exec -it {コンテナ名} bashで入れます.
ダウングレード後にJupyterのkernelをrestartしてください.
matplotlibのversionはimport matplotlib したのち,matplotlib.__version__で確認できます.
よく使う引数はcmap(color map)とannot(annotation)です.
cmapには色のグラデーションを指定します.すでに用意されたものがあるのでそれを指定します.これはHeatmapに限らず使えるのでいくつかお気に入りを覚えておくといいです.coolwarmやhot, plasmaあたりが有名です.
annot引数をTrueに指定すると,各セルに数値を表示してくれます.そこまで大きくない表であればつけましょう.わかりやすいです.
|
1 |
sns.heatmap(corr, cmap='coolwarm', annot=True) |
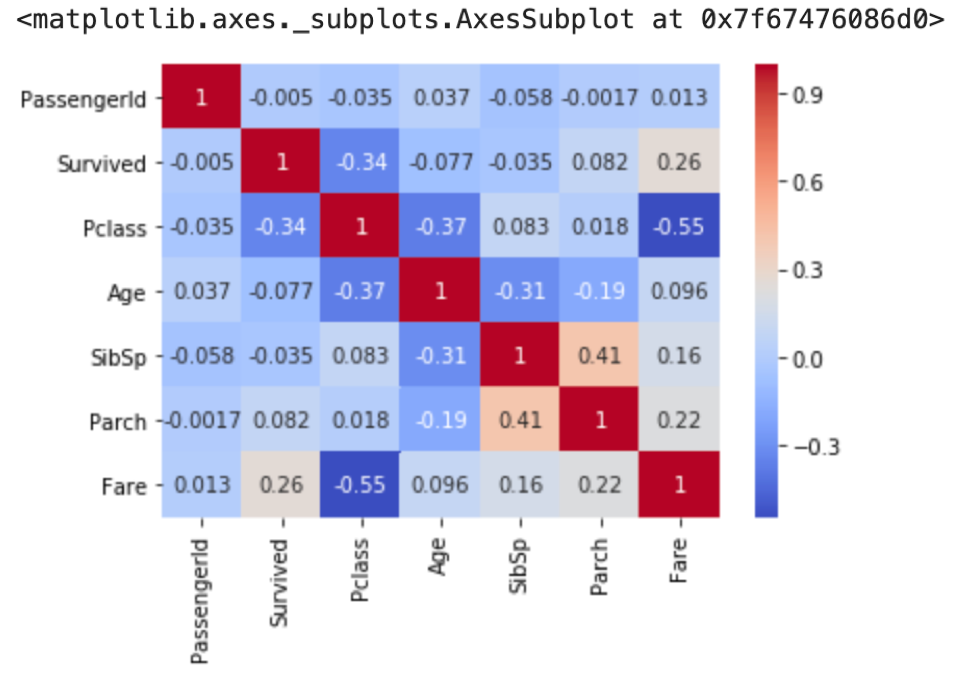
冒頭に出した図がこれです.やはりannot=Trueにすると値が表示されて便利です.
また,PassengerIdはどのカラムとも相関がなく,確かにランダムに付与されていることが確認できます.
データによっては,実はIDに規則性があったりする可能性もあるので注意です.もしそういうデータに出会ったら,どのようにIDを付与したのか確認しましょう.もしかすると他にデータに予想外の影響(恣意的な操作)がかかっているかもしれません.例えばこれがきっかけに,ランダムに抽出したつもりが実はランダムじゃなかったということが判明することもありえます.
このHeatmapはまた今後の機械学習講座でも取り上げていく予定です.特に多クラスのConfusion Matrixを表示するのに重宝します.
データを俯瞰する際に役立つsns.heatmap()
Heatmapは,データの分布を俯瞰するのにも役立ちます.(上の例でもデータを俯瞰するという意味ももちろんありますが,今回の例はより多くのデータで,傾向を俯瞰するイメージです.)
いい例が思いつかなかったので公式ページ’の例をパクります.
Seabornにはいくつかデータセットが用意されているので今回は’flights’のデータセットを使います.
Seabornのデータセットは sns.load_dataset() でDataFrame形式でロードできます.
|
1 2 3 |
flights = sns.load_dataset('flights') print(len(flights)) flights.head() |
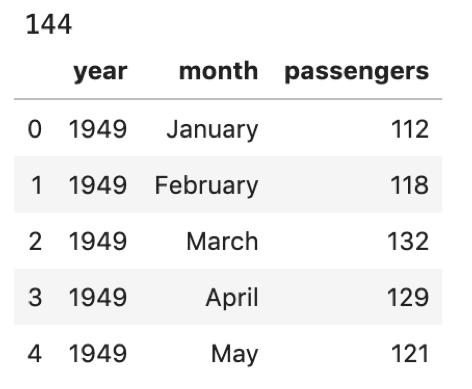
144件のレコードとyear, month, passengersのカラムがあります.「何年何月に何人の乗客が乗ったか」でしょうか?(だいぶ乗客少ないですが,昔だからでしょうか?)
これを,monthをindex, yearをカラムにして値をpassengersに指定してピボットテーブルを作ります.(pivot_table()の使い方については第19回を参照ください!)
|
1 2 |
flights_pivot = flights.pivot_table(index='month', columns='year', values='passengers') flights_pivot |
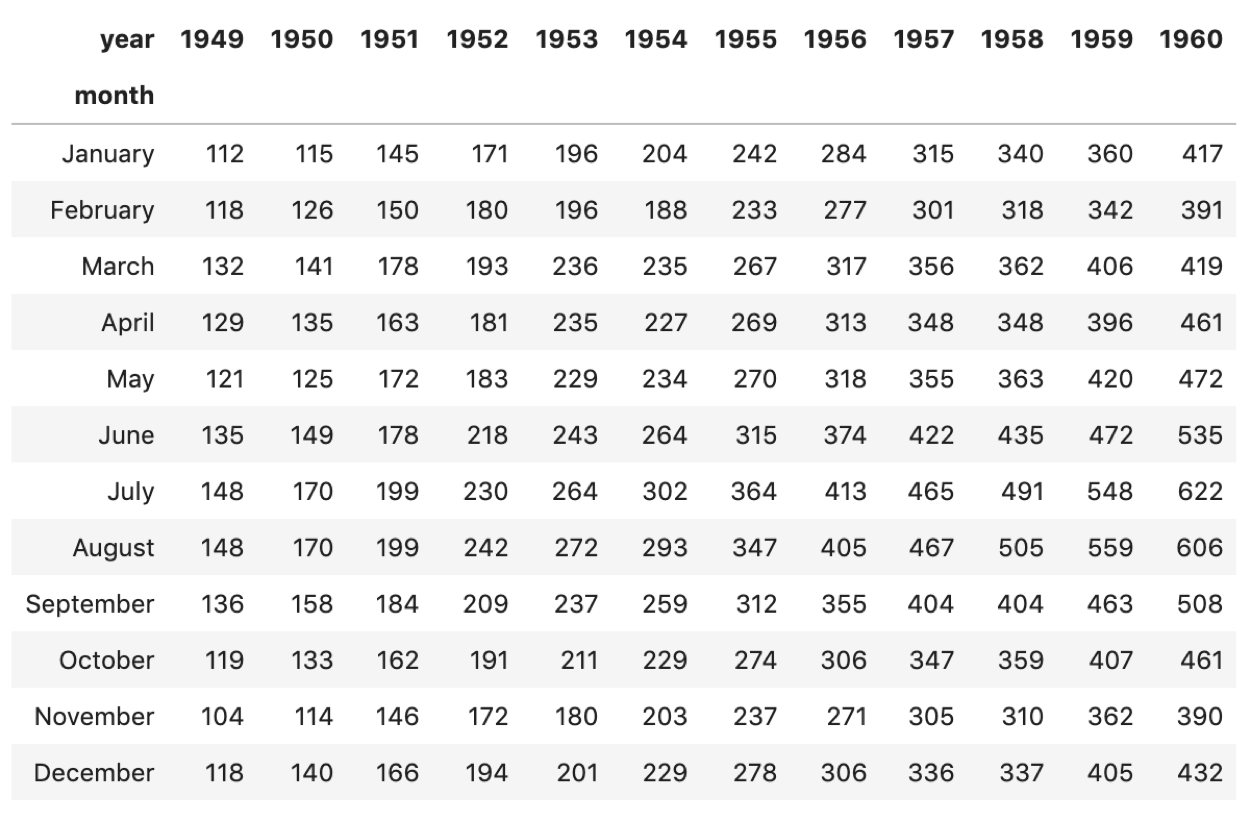
すると,先ほどの相関表のようにyearとmonthの交差するセルにpassengersの値が入っているのがわかります.
これをheatmapで表すと
|
1 |
sns.heatmap(flights_pivot) |
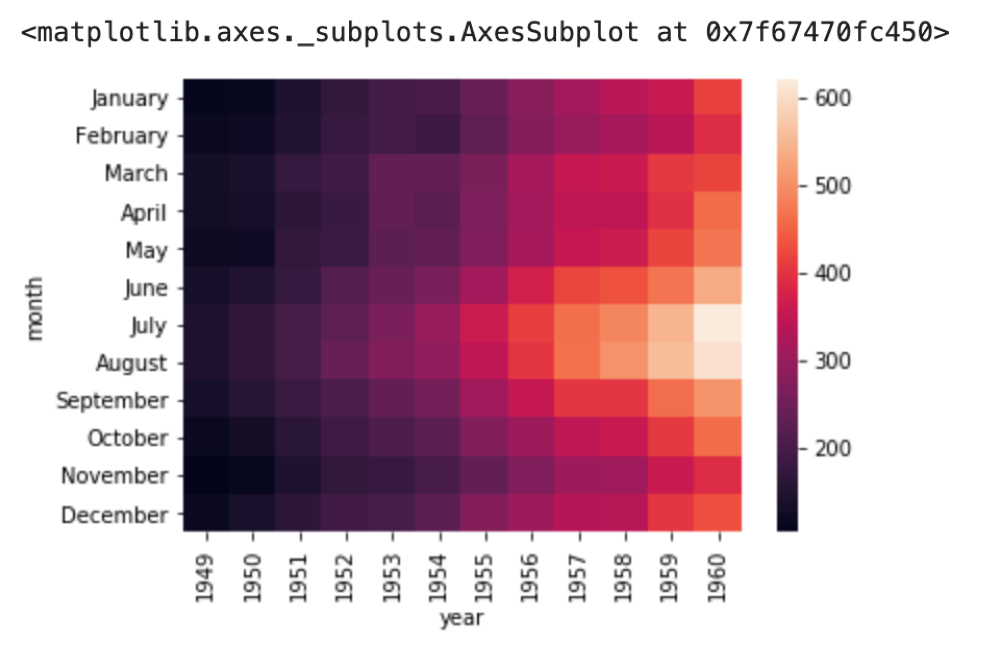
おおーまさしく”ヒートマップ”って感じですね
このように,時系列のように連続した値をindexやcolumnsに指定してHeatmapを使うと,値の変化が一目でわかります.
毎年夏に乗客が多く,年々乗客の数は増えているというのがわかると思います.
これがもっと多くの行数,列数になっても,Heatmapで表示することで値が高い場所,低い場所が一目でわかり,便利です.
今回は,すでに用意されたflightsデータセットを使ったので簡単にpivotするだけでしたが,実業務ではflightsデータセットのようなものを自分で0から作ることになると思います.
で,最終的にこのHeatmapを表示する感じですね!
まとめ
今回はHeatmapの描画について紹介しました.重要なポイントは以下です.
- df.corr()で相関表のDataFrameを作成
- sns.heatmap()でHeatmapを描画
- cmap引数で色のグラデーション変更
- annot引数で各セルの数値を表示
とにかくこのHeatmapは統計・機械学習と相性がいいです.
ただ,画像処理などで使うheatmapは基本numpy arrayを使って画像として描画します.その方法はまた別途紹介します.
今回の記事でSeabornのplotの紹介は終わりです.次回装飾の仕方を少し紹介してSeaborn編終了となります.
まだまだSeabornには使えるplotがあります.heatmapと似たclustermapや,線形回帰を書いてくれるlmplotはひとまずデータを分析したい時には便利です.が,これらは機械学習の知識を使うので,今回は省きました.(今後機械学習講座でやっていく予定なのと,これらはあくまでも「とりあえず分析」的に使うだけなので,一般的に使うものでは無いという判断です)
ここまでくるともう過去の内容をかなり忘れていると思うので,何度も何度も復習して自分でコードを書いて,気になったら自分で色々調べて試してみましょう!
最近書き忘れてましたが,Twitter(@usdatascientist)フォローお願いします.あと,誤字脱字等見つけたらこっそり教えてください!
それでは!
追記)次回の記事書きました.Seabornのsns.set()をつかって色々装飾をいじります.