







こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
前回の記事で,データサイエンスにはPythonをお勧めしました.
今回の記事から「データサイエンスのためのPython」を連載したいと思います(講座の目次はこちら).
ついに,データサイエンスっぽくなってきて嬉しいです.
なぜ先にDockerやGithubをやったかというと,環境のセットアップにDockerを使ったり,勉強しながらGithubのフローを組み入れて欲しいと思ったからです.そうすることでより実務に近い形で学習できるし,DockerやGithubにも慣れますからね!
それでは解説していきます!
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
(未経験から学べるPython動画講座がでました!詳細はこちら)
目次
前提知識
今回の連載ではDocker超入門の知識を前提としています.できればこれらを読んでから進めて欲しいです.
必要な知識は記事の中でできるだけリンクさせるようにはします.
あと,基本的なPythonのプログラミングの知識もあるといいですが,ない場合も適宜ググりつつ&試していきつつ進めていけるようにはします.
本連載のスコープ
データサイエンスに必要なPythonの使い方を学習できます.内容としては以下のような具合です.
– Jupyter Notebookの使い方
– Numpyの使い方
– Pandasの使い方
– Matplotlibやseabornの使い方
– sklearnの使い方
これらのツールを,統計学・機械学習の説明を交え解説していきます.
今回の連載を終える頃にはPythonを使ってデータを解析するのに必要な知識が付いていると思います.
かなり実践に即した内容で,実際に私もデータサイエンティストとして日常で使っているものです.
この連載を何回か読んでおけば,Pythonスキルはもう初心者ではないし,多くの会社でデータサイエンティストとして働くことができると思います.
Jupyter Labとは?

Jupyter Labというのは,Pythonのエディタのようなものです.前にエディタにはSublimeがおすすめという記事を書きましたが,私は普段Jupyter LabとSublimeの両方を仕事で使っています.
Jupyter Labというのは,Pythonのコードを書いて実行するとすぐその実行結果が表示されます.グラフや表などがとても綺麗に表示されるのでデータ分析必須のツールなんです.
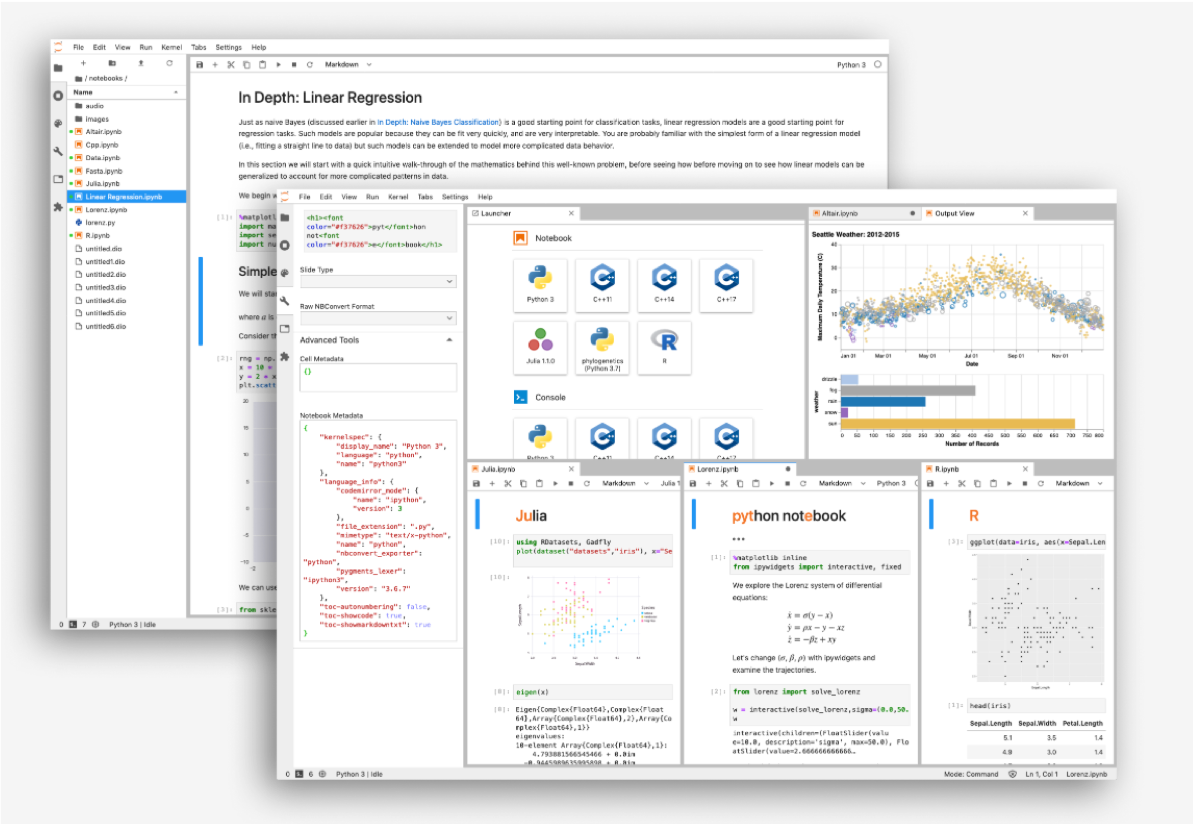
Jupyter LabはJupyter Projectが開発・管理しているオープソースのソフトウェアです.Jupyter Notebookというツールの後継で,Jupyter Notebookを進化させたものと思っていただいてOKです.
上記の画像を見ていただいてわかる通り,Jupyter Labはブラウザ上で起動するものです.ローカルにWebサーバを立てて,そこにブラウザからアクセスします.
なにを言っているかわからないかもしれませんが,全然難しくないので,まずは使ってみましょう.
ちなみに,他にも複数のユーザが使用できるJupyter Hubもあり,Jupyter Hubを使えば複数ユーザでJupyter Labを使うことも可能です.それについてはまた別途記事にします.
なぜDockerを使うのか?
私のブログでは基本開発環境の構築にDockerを使います.
理由は,
- 簡単にできる
- エラーが出る可能性が極めて低い
- 持ち運びができる(例えばPCを換えても簡単に同じ環境をセットアップできます)
- 実務に即している
からです.もしDockerを使ったことがない方は,一度こちらでDockerについて学んでおくことをお勧めします.
(追記:Docker動画講座作りました.14時間にも及ぶ超壮大講座です.また,本記事の環境セットアップについても応用編で超わかりやすく解説しています.
実際の業務でもDockerを使うことになる可能性が高いですし,使うべきです.
データサイエンティストといえど,Dockerの基本の知識はつけておくと今後の学習が楽ですよ〜
(自分が初めてPythonを勉強したとき,環境の構築が本当に大変で苦労しました.Dockerを使えば楽チンですからね)
Dockerfileを作る
Docker Hubのjupyter/レポジトリに,いくつかすでにJupyter Projectが用意したDockerイメージがありますが,今回はそういった既に用意されたDockerイメージを使うのではなくて,ubuntuイメージをもとに自分でDockerfileを作りましょう!
実際の業務では,あらかじめ用意されているDockerイメージをそのまま使えるケースは少なく,自分で必要なバージョンのパッケージをDockerfileに書いてくことになります.Dockerfileを作る練習も兼ねてやってみましょう
それではまず,任意のフォルダにDockerfileという名前のtxtファイルを作成します.
|
1 2 3 |
$ mkdir ~/Desktop/docker_build $ cd Desktop/docker_build/ $ subl Dockerfile |
(本ブログではSublimeをお勧めしています.Sublimeについての記事はこちら.$subl DockerfileでDockerfileというファイルをsublimeで新しく作り,開きます.$sublコマンドが動かない人は正しくPathが通っていないので,こちらの記事のsublime使い方④を参考にしてください.sublimeは必須ではないので,他のエディタでももちろん問題ないです.)
Dockerfileには以下の内容をコピペします.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
FROM ubuntu:latest # update RUN apt-get -y update && apt-get install -y \ sudo \ wget \ vim #install anaconda3 WORKDIR /opt # download anaconda package and install anaconda # archive -> https://repo.continuum.io/archive/ RUN wget https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh && \ sh /opt/Anaconda3-2019.10-Linux-x86_64.sh -b -p /opt/anaconda3 && \ rm -f Anaconda3-2019.10-Linux-x86_64.sh # set path ENV PATH /opt/anaconda3/bin:$PATH # update pip and conda RUN pip install --upgrade pip WORKDIR / RUN mkdir /work # execute jupyterlab as a default command CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"] |
FROM で,ベースとなるOSを選びます.今回はubuntuを選びます.
データ解析をする際にはよく解析用のサーバで作業することが多いです.私も業務ではいつもubuntuの解析サーバを使っています.Dockerでubuntuに慣れておくこともいい練習になると思いますし,今回作ったこのDockerイメージをそのまま解析サーバに持っていくことも可能です.ubuntuはデータ解析との相性もいいので今回はubuntuを選択します.
apt-getというのはubuntuのパッケージ管理です.MacでいうHomebrewのようなものだと思っていただければOKです.今回は練習用なのでapt-getを更新して常にインストール時に最新のパッケージをインストールするようにします.実際の業務ではapt-getを更新してもいいですが,その後にインストールするパッケージのバージョンを固定させたり,本番環境ではapt-getからインストールせず自分達でレジストリを作ってそこからパッケージをインストールさせ,apt-getのコードが変に更新されても影響を受けないように工夫します.
WORKDIR コマンドは,それ以降のコマンドの実行する際のディレクトリを指定します.Dockerの講座第7回でも話しましたが,Dockerfileは基本 / 配下で実行されますが, WORKDIR コマンドにより指定したディレクトリで実行するようにします. /opt 配下にAnacondaというパッケージを入れます.Anacondaというのはデータサイエンスに必要なPythonのモジュールが丸ごと入ったパッケージで,とりあえずAnacondaを入れておけば必要なモジュールが使えます.JupyterもAnacondaに入っているので特にインストールしなくてOKなんです!楽チン!続けて,$jupyter labコマンドのオプションを指定します.
Jupyter Labは内部でWebサーバを構築し,ローカルからWebブラウザを使ってアクセスします.今回はローカルなのでIPに 0.0.0.0 (ローカル)を指定します.
また,Jupyter はrootユーザでの実行は推奨されていません.本来であればコンテナにもホストOS同様ユーザを作成し然るべきアクセス権限を管理すべきですが,今回はめんどいので --allow-root としてrootユーザで実行できるようにします.passwordの設定もめんどいので --LabApp.toke='' でtokenを使わずJupyter Labにログインできるようにします.(余力があれば別途記事にしますね)
Dockerfileをbuild⇨run⇨Jupyter Labにアクセス
さて,長くなりましたが $docker build . でビルドしましょう.
追記)M1マシンをお使いの方は, $docker build --platform linux/amd64 . としてください.
|
1 2 |
$ docker build . Successfully built d723190a8650 |
するとイメージIDが表示されるので,そのイメージを $docker run します.今回はrunするときに3つのオプションを指定します.
一つ目はポートを指定するオプションです,Jupyter Labはデフォルトでポート 8888 を使います.コンテナ内でJupyter Labを使うので,コンテナのポート 8888 がJupyter Labへのアクセス口になります.しかし,通常コンテナ側でポートを開いてもそれはホスト側からアクセスできません.コンテナのポートをホストのポートにマッピングする必要があります.コンテナのポート 8888 をホストのポート 8888 にマッピングしてホスト側からコンテナのポートにアクセスできるようにします.ポートのマウントは -p {host port}:{container port} オプションを使います.
二つ目はファイルシステムのマウントです,Docker入門で話した通り,コンテナ側からはホスト側のファイルシステムにアクセスできません,しかし,コンテナで作業をする際ファイルをコンテナ側に作成するのではなく,ホスト側に作成したいですよね?そこで,ホストとコンテナのファイルシステムのマウントを行います. -v {host volume}:{container volume} でマウントします.今回はホスト側に作業用フォルダ ~/Desktop/ds_path をあらかじめ作成し,Dockerfileで作った /work フォルダをコンテナのマウント先として指定します.ホスト側の作業ディレクトリは,なんでもいいと思います.
三つ目はコンテナ名です.指定しないとDockerはランダムで名前をつけるのですが,今後も同じコンテナを使っていくので名前を指定します.名前は --name {コンテナ名} で指定できます.
今回は -p 8888:8888 -v ~/Desktop/ds_python:/work --name my-lab を指定します.各自Dockefileを作成したpathを指定してください!
|
1 2 3 4 5 6 7 8 9 10 |
$ docker run -p 8888:8888 -v ~/Desktop/ds_python:/work --name my-lab d723190a8650 [I 02:28:31.840 LabApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret [W 02:28:31.983 LabApp] All authentication is disabled. Anyone who can connect to this server will be able to run code. [I 02:28:31.988 LabApp] JupyterLab extension loaded from /opt/anaconda3/lib/python3.7/site-packages/jupyterlab [I 02:28:31.988 LabApp] JupyterLab application directory is /opt/anaconda3/share/jupyter/lab [I 02:28:31.990 LabApp] Serving notebooks from local directory: / [I 02:28:31.990 LabApp] The Jupyter Notebook is running at: [I 02:28:31.990 LabApp] http://ec5e9afb20f6:8888/ [I 02:28:31.990 LabApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [W 02:28:31.993 LabApp] No web browser found: could not locate runnable browser. |
実行できたらブラウザからlocalhost:8888にアクセスしてJupyter Labに入ります.
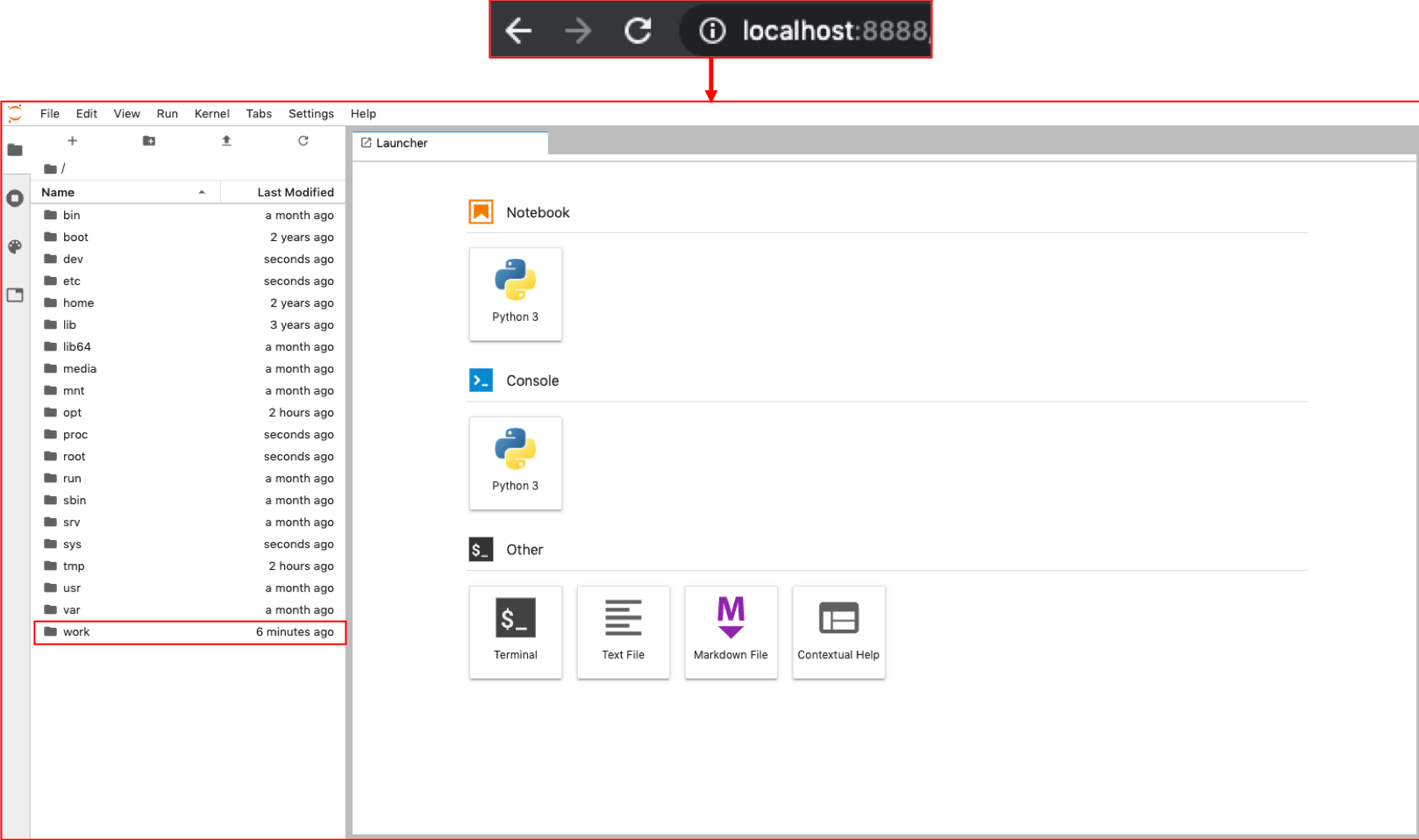
無事,Jupyter Labのホーム画面を開くことができました!ちゃんと work フォルダもありますね
もしlocalhost:8888にアクセスしても,「ページが見つかりません」 となる場合は,コンテナが動いていないか,他のプロセスが8888ポートを使っている可能性があります.
- $docker ps でコンテナが動いていることを確認してください.また,PORTカラムにちゃんとコンテナの8888ポートがホストの8888ポートにマッピングされていることを確認してください.($docker run後,ctrl+Tで新しいTerminalのタブをひらけば,コンテナを止めることなく確認可能です)
- $lsof -i:8888を実行して,他のプロセスが8888ポートを使っていないか確認してください.もし,そのプロセスを止めても問題ないのであれば,$kill -9 <PID>コマンドを実行してプロセスを切り,再度上述の$docker runコマンドを実行してください.<PID>は$lsofコマンドを実行した結果を見ればわかります.
- 他のポート番号を使うのもありです.-p 8889:8888を指定すれば,ポート8888ではなく8889を使います.8888をすでに使っているプロセスを切りたくない場合は,別のポートを使いましょう.
本記事の環境設定について,もっと詳しく勉強したい人はDockerの動画講座で学習してください.本動画講座の応用編にて超詳細に説明しています.
使い方については次回の記事以降書いていきます.
今日はひとまず,お疲れ様でした〜!それでは!
追記)次回は書きました.こちらです↓











[…] 環境構築についても同じブログのデータサイエンスのためのPython入門①〜DockerでJupyter Labを使う〜を参考に構築させて頂きました。 […]
[…] データサイエンスのためのPython入門1~DockerでJupyter Labを使う~ オススメ : ★★★★☆ 難易度 : ★★☆☆☆ ボリューム : […]
[…] ”DSのためのPython入門講座” […]