こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第13回です(講座の目次はこちら).今回も前回に引き続き,DataFrameのフィルタ操作(filter)とindex操作を紹介していこうと思います!
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
フィルタ操作というのは,ある条件に合致するレコードだけ抽出する操作です.エクセルの「フィルタ」機能でできるやつですね.
フィルタ操作はDataFrameの操作で最も頻出かつ重要な操作の一つです.できるだけわかりやすく説明するので付いてきてください!
目次
(超重要)DataFrameを特定の条件でフィルタ(filter)する
前回同様,タイタニックのデータを使います.
|
1 2 3 |
import pandas as pd df = pd.read_csv('train.csv') df |
この891レコードのうち,例えば生存者のレコードだけに絞りたい時にフィルタ操作をします.
わかりやすく,Step By Stepに説明しますね.
まず,前回の記事で説明したように df['Survived'] でSeriesを取得します.Kaggleの説明ページをみるところ,0=死亡 1=生存 のようです.取り出したSeriesを==で条件を作ってみましょう!
|
1 |
df['Survived'] == 1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
0 False 1 True 2 True 3 True 4 False ... 886 False 887 True 888 False 889 True 890 False Name: Survived, Length: 891, dtype: bool |
すると,FalseとTrue(boolean)のSeriesが返ってきました.
このSeriesをfilterという変数に入れて,df[]に渡すと・・・
|
1 2 |
filter = df['Survived'] == 1 df[filter] |
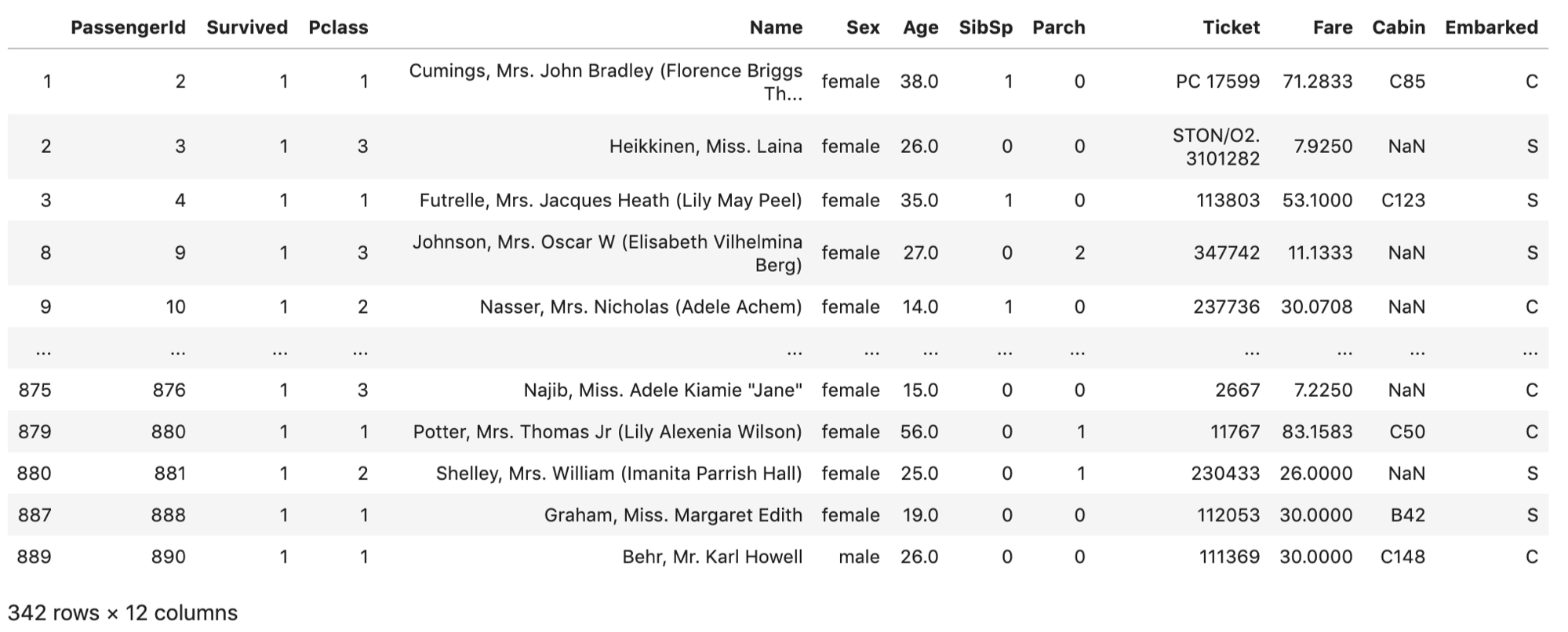
Survived==1のレコードのみに絞られています.
df[filterの条件]で,ある条件に該当したレコードだけが返ってきます.SQLでいうwhere句のようなものです.
以下のようなイメージです.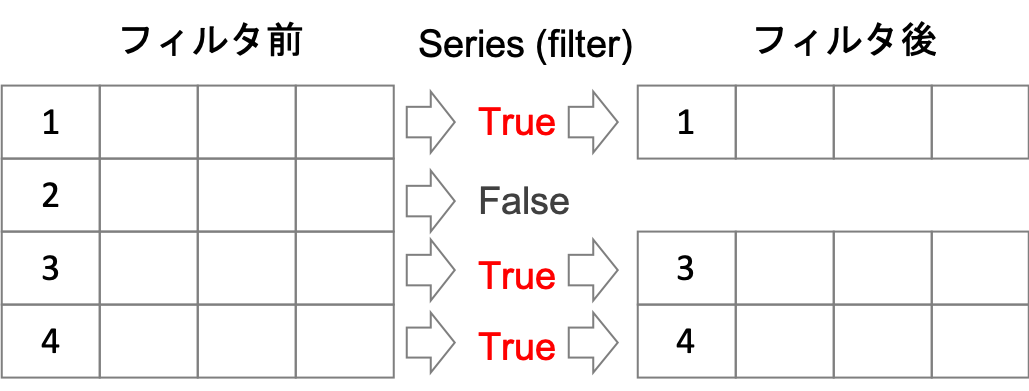
Trueのところだけフィルタが通ります.レコードのindexは保たれることに注意してください.また,元のDataFrameは上書きされません.
普通はいちいち変数にはいれず,
|
1 |
df[df['Survived']==1] |
とすることの方が多いです.
生存者にはどういう特徴があるのか確認したいですよね? 生存者と全体の統計量を比べてみましょう.
統計量の確認には前回紹介した.describe()を使います.
|
1 |
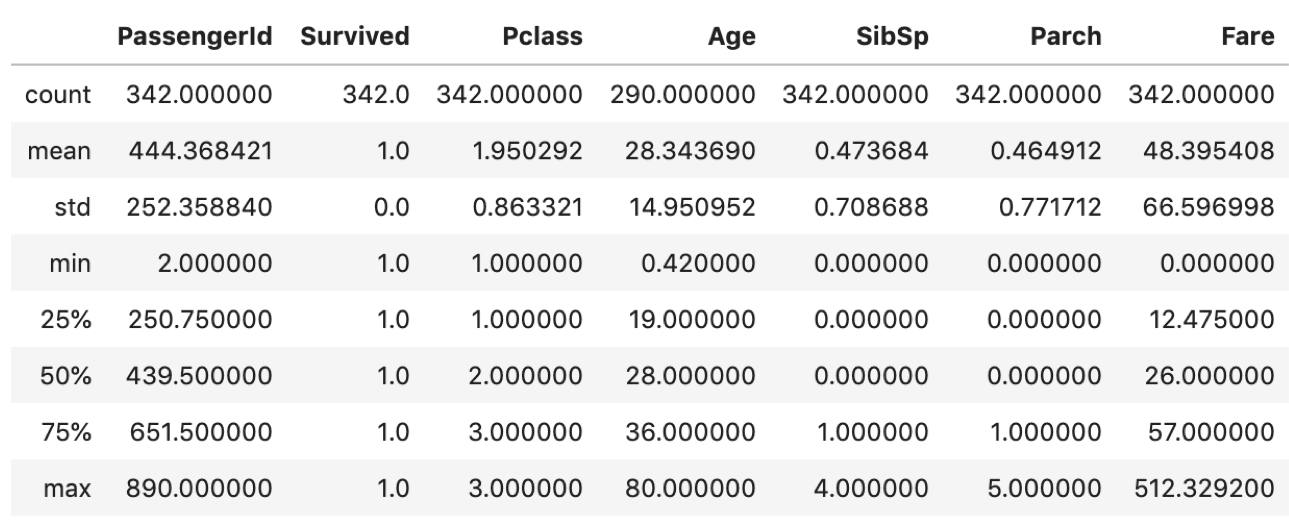
df[df['Survived']==1].describe() |
|
1 |
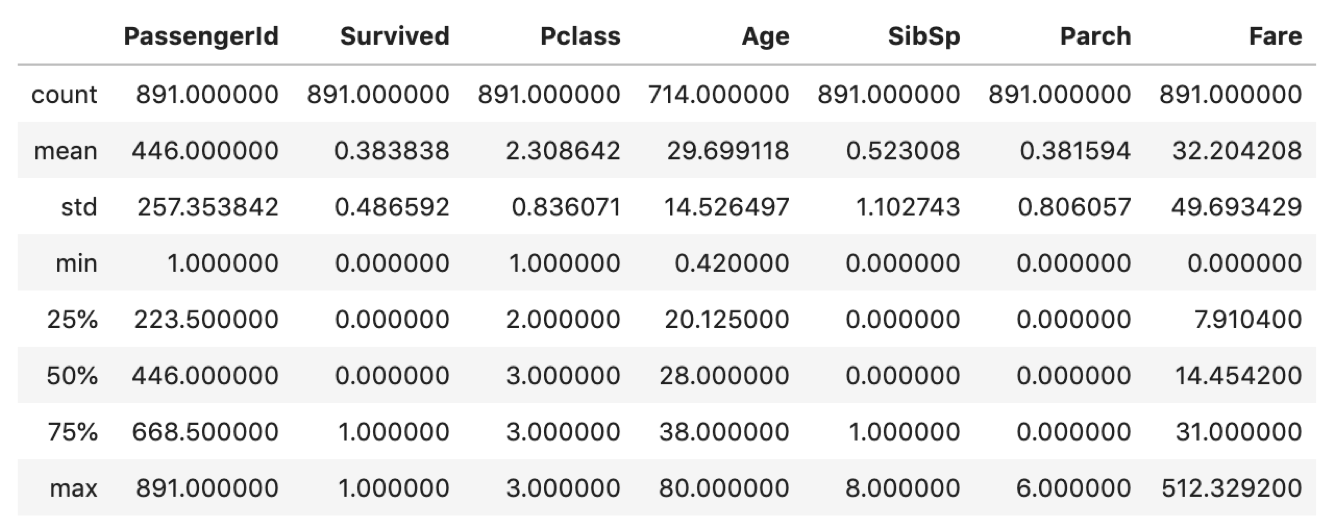
df.describe() |
本当はグラフで比較すべきですが,この辺りのグラフの描画については第25回あたりの記事が参考になると思います.
Ageのmeanをみると,生存者の方が若干若いですね.あと,Fareのmeanをみると,高い運賃を払っている人の方が生存していると言えそうです.理屈で考えると,子供やクラスが高い人から優先的に救命ボートに乗れたのだろうと仮説が立てられます.
ただ,これが両者を比較して,「本当にそう言えるのか」,「Ageの1.3年の差はたまたまじゃないのか?」という疑問はありますよね?(「統計的有意性」(statistical significance)と呼びます.)
これに対して答えを出せるのが統計学です.今後本ブログで統計学入門講座を書いていく予定なので楽しみにしていてください!!
他にも試しに色々なフィルタをしてみてみましょう.
- 60才以上のレコードに絞る
- 1stクラスのレコードに絞る
- 女性のレコードに絞る
答えはこちら↓
|
1 2 3 4 5 6 |
# 60才以上 df[df['Age']>=60] # 1stクラス df[df['Pclass']==1] # 女性 df[df['Sex']=='female'] |
同じように,.describe()でそれぞれの条件で絞ったときのSurvivedの統計量をみると面白いですよ.女性の生存率は高く,60才以上の生存率は低いです.
- ()&() や ()|() を複数条件でフィルタ可能
例えば60才以上(Age>=60)の女性(Sex==’female’)や1stクラス(Pclass==1)もしくは10才未満(Age<10)のレコード などは以下のように各条件を括弧 () で囲んで & (アンパサンド)や | (パイプ)で繋ぎます.
Pythonだとandやorを使って条件を作りますが,DataFrameのフィルタ操作では&と|であることに注意です.
|
1 2 3 4 |
# 60才以上女性 df[(df['Age'] >= 60) & (df['Sex']=='female')] # 1stクラスもしくは10歳未満 df[(df['Pclass'] == 1) | (df['Age'] < 10)] |
- ~ (スクィグル)をつけるとNOT演算でフィルタ可能
これは特に「値がbooleanのカラムでフィルタする時」によく使います.
以下のDataFrameを考えてみます.
|
1 2 3 4 5 |
data = [{'Name':'John', 'Survived':True}, {'Name':'Emily', 'Survived':False}, {'Name':'Ben', 'Survived':True}] df = pd.DataFrame(data) df |
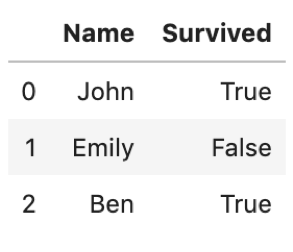
めっちゃシンプルなDataFrameです.タイタニックデータではSurvivedが0か1になっていましたが,今回はBooleanです.
それでは,生存者だけフィルタしてみます.
|
1 |
df[df['Survived']==True] |
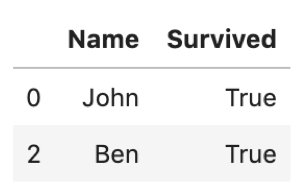
ちゃんとフィルタされてますね!
実はこのSurvivedカラムはすでにBooleanなので,==True必要ないですよね?df[‘Survived’]がすでにBooleanのSeriesになるので以下のようにそのままフィルタできます.
|
1 |
df[df['Survived']] |
Survived==Falseに絞りたい場合は, df[df['Survived'==False] なんてことする必要なく,以下のようにできるのです!
|
1 |
df[~df['Survived']] |

めっちゃスマートですよね. ~ はこのように,Booleanのカラムで使うケースが多いです.もちろん,普通にフィルタリングするときも使いますが.
indexを変更する
- .reset_index()で再度indexを割り振る
先ほど説明した通り,フィルタを通したDataFrameのindexはもとのDataFrameのままです. .reset_index() をすることでindexを0から順に再度割り振ります.
|
1 2 3 |
df = pd.read_csv('train.csv') df = df[df['Sex']=='male'] df |
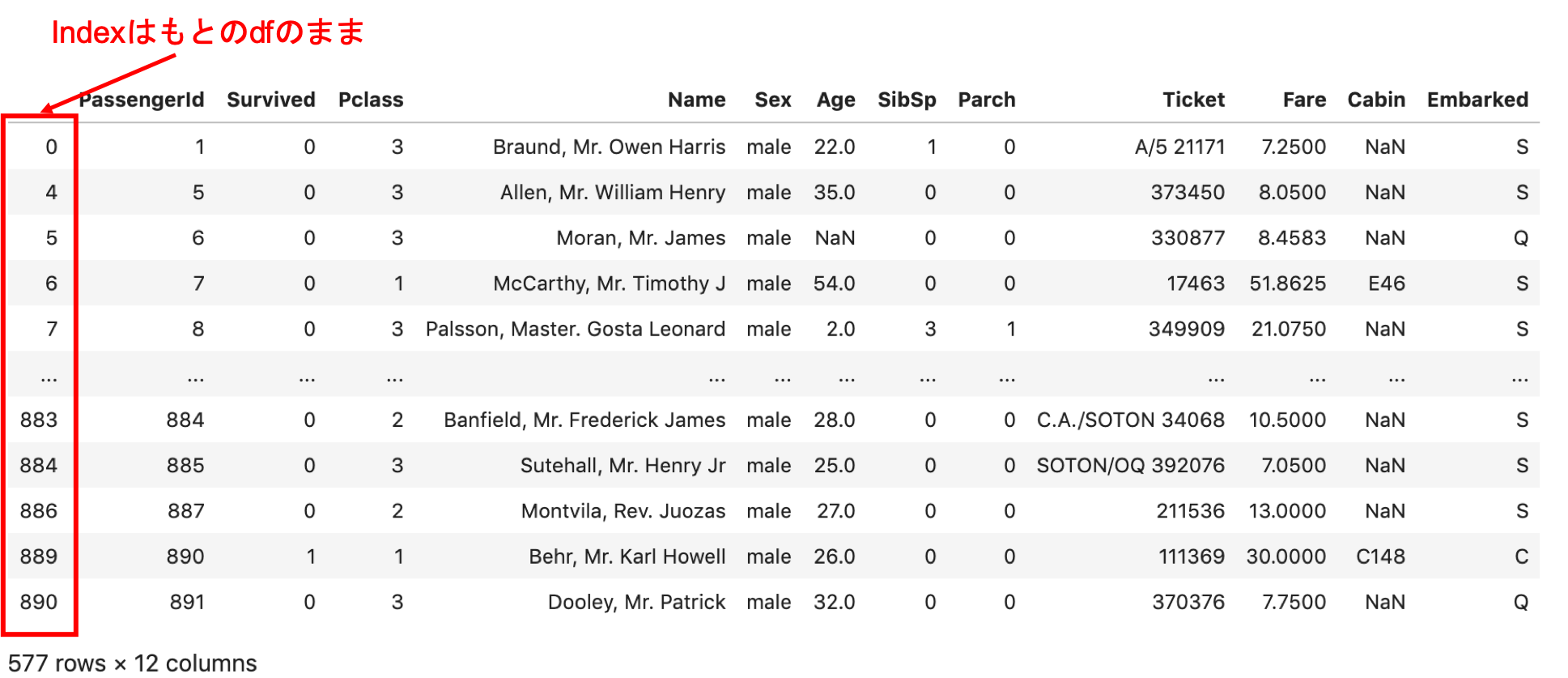
|
1 |
df.reset_index() |
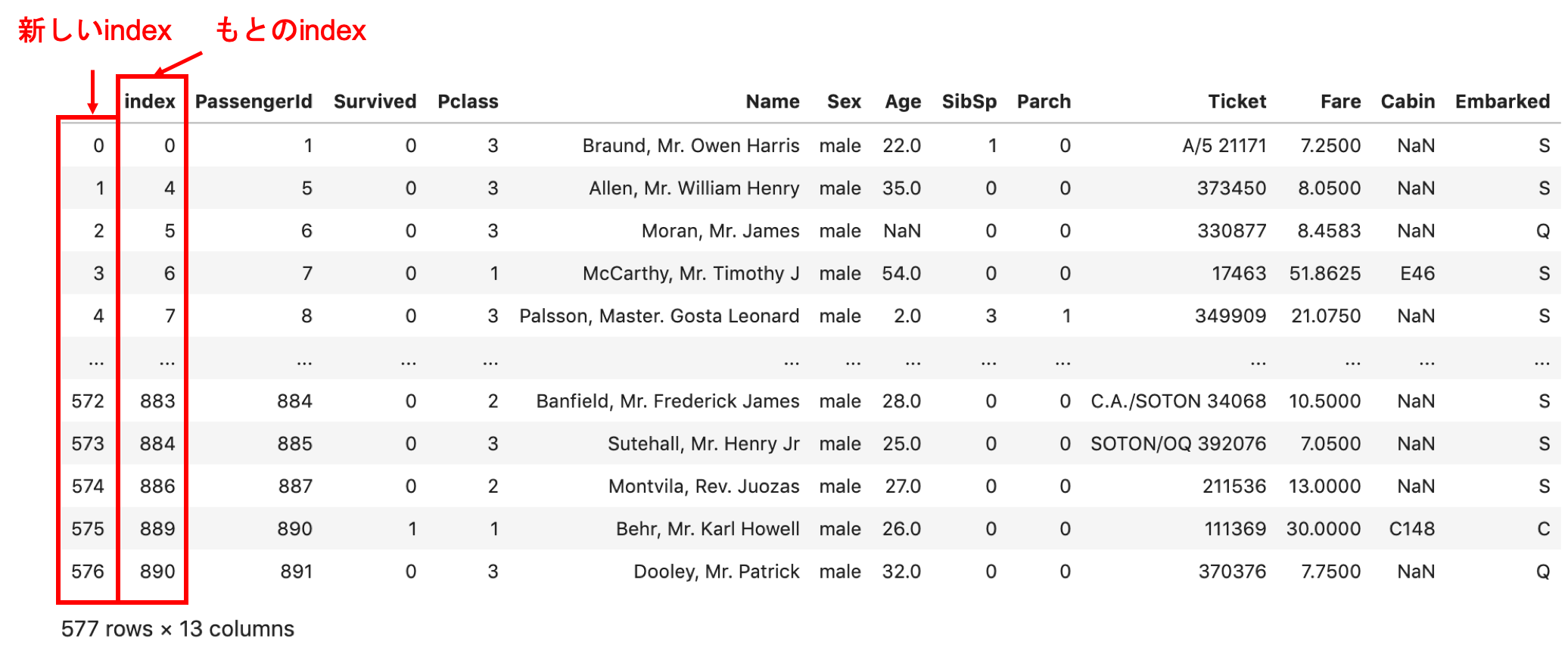
新しいindexが振られ,もとのindexは「index」というカラムになっています.(ややこし!)
また,前回説明した .drop() 同様,もとの df は上書きされないので, df を更新したい場合は inplace=True もしくは df = df.reset_index() で再代入しましょう.
- .set_index()で特定のカラムをindexにする
例えばNameをindexにしたければ以下のようにindexをセットできます.
|
1 2 |
df = pd.read_csv('train.csv') df.set_index('Name') |
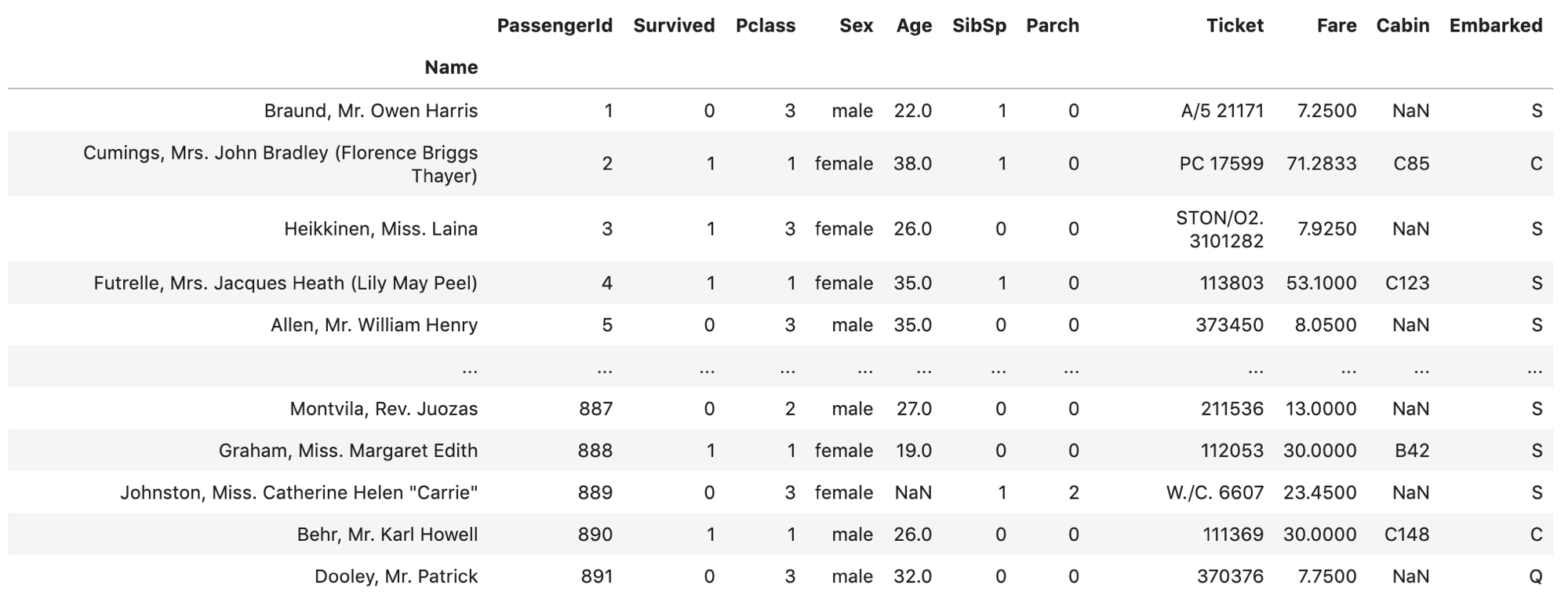
DataFrameを色々いじっていると,indexを振り直したくなる場面は結構あります.indexをセットすることはあまりないかもしれませんが,合わせて覚えておきましょう!
まとめ
- DataFrameのフィルタ操作はデータサイエンス再頻出操作の一つです.
- df[条件のSeries]でフィルタ可能.indexはそのまま
- ()&() や ()|() を複数条件でフィルタ可能⇨括弧を忘れずに!あとandとor出ないことに注意
- ~ (スクィグル)をつけるとNOT演算でフィルタ可能⇨とくにBooleanのカラムでよく使う
- .reset_index()で再度indexを割り振る
- set_index()で特定のカラムをindexにする
特に今回のフィルタ操作の説明は全て超重要事項です.
データサイエンスをする上で何度も出てきます.自分で色々なフィルタを作って試してみてください.
それでは!
↓次回書きました.DataFrameの欠損値NaNの操作についてです.欠損値の扱いはデータサイエンス超重要テーマです.