データサイエンス入門の機械学習編第8回です!(講座全体の説明と目次はこちら)
追記)機械学習超入門動画講座を公開しました!動画で効率よく学習をしたい人はこちら(現在割引クーポン配布中です)
前回の記事では,未知のデータに対しても高い精度で予測できる能力(汎化性能)が重要であることを述べ,汎化性能を測る最もシンプルな方法としてhold-out法を紹介しました.
hold-out法では,一部のデータしか学習に使えなく,分割にランダム性が生じるので結果が毎回同じにならない問題があるんでした.
これらの問題を緩和するのが,今回の記事で紹介するLOOCVという手法です!
目次
LOOCVとは
LOOCVって,名前がゴツくてとっつきにくいんですが,何も難しいものじゃないので安心してください笑
LOOCVは,Leave-One-Out Cross Validationの略です.略を見ても何言ってるかわかりませんね笑
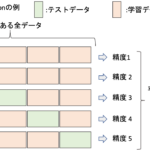
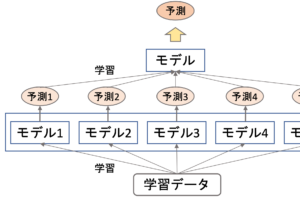
hold-outでは,全てのデータを学習データとして使えないことが問題でした.それを緩和する方法がLOOCVで,手元のデータのうち,一つだけをテストデータとして他の全てを学習データとします.
ひとつ以外の全てのデータで学習をしてモデルを作って,そのモデルをたったひとつのデータで評価します.
これだけだとテストデータによって評価の分散が非常に大きくなってしまうので,全てのデータがテストデータになるように,この作業をデータの数だけ行います.図に表すと以下のような感じです.
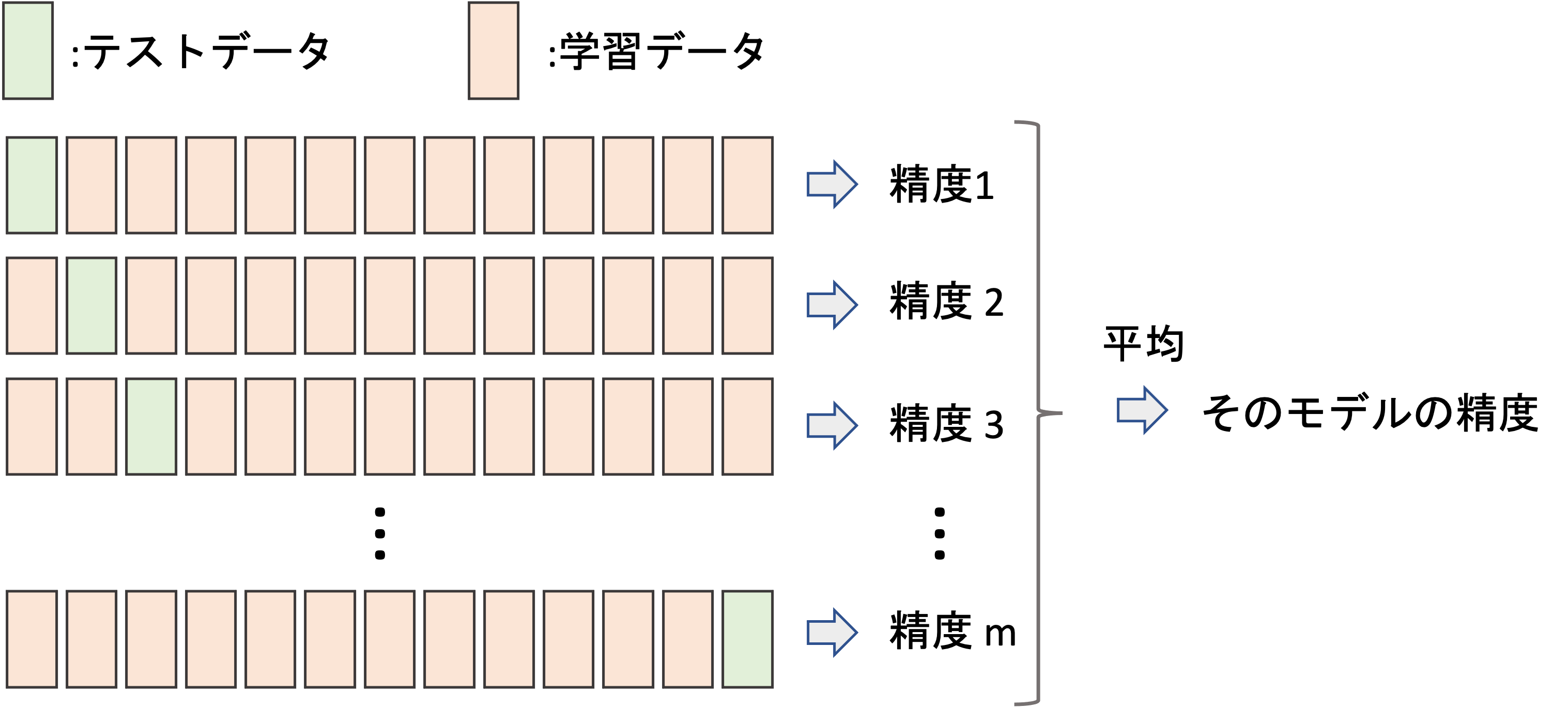 つまり,データの数だけモデルを作って精度を測るわけです.で,最後にその精度の平均を求めます.精度の標準偏差も求めることが多いです.
つまり,データの数だけモデルを作って精度を測るわけです.で,最後にその精度の平均を求めます.精度の標準偏差も求めることが多いです.
こうすることで,ほぼ全てのデータを学習データとして使うことができるので,手元にあるデータを無駄なく使用することができますし,hold-outでは学習データとテストデータの分割をランダムにするため,精度の結果にランダム性が生じますが,LOOCVの場合はランダム性はなく最終的な評価は常に同じになります.
PythonでLOOCVを実装する
それではPythonでLOOCVを実装してみましょう!
今回はサンプルデータとしてtipsデータセットを使ってやります.特徴量total_billからtipの値段を予測する線形回帰を作ります.(データの中身については,今回は本題ではないので割愛しますが,tipsデータセットは統計学動画講座でも扱っています.)
|
1 2 3 4 5 |
import seaborn as sns import numpy as np df = sns.load_dataset('tips') X = df['total_bill'].values.reshape(-1, 1) y = df['tip'].values |
scikit-learnの model_selection モジュールの LeaveOneOut クラスを使います. LeaveOneOut のインスタンスを生成し, .split() メソッドが学習データとテストデータのindexを返してくれるジェネレータの役割をします.以下のコードを実行してみるとわかりやすいと思います.
|
1 2 3 4 |
from sklearn.model_selection import LeaveOneOut loo = LeaveOneOut() for train_index, test_index in loo.split(X): print("train index:", train_index, "test index:", test_index) |

すると,test indexが0, 1, 2, ….と続いて行き,それ以外のindexがtrain indexになっているのがわかると思います.
このindexを使って, X と y から X_train , X_test , y_train , y_test を毎回のイテレーションで作って,モデルを学習させ評価することになります.
今回はSE(squared error)を精度の指標とし,LOOCVでデータの数だけSEを計算し,その平均を取ってみたいと思います.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from sklearn.linear_model import LinearRegression from sklearn.model_selection import LeaveOneOut loo = LeaveOneOut() model = LinearRegression() mse_list = [] for train_index, test_index in loo.split(X): # print("train index:", train_index, "test index:", test_index) # get train and test data X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] # fit model model.fit(X_train, y_train) # predict test data y_pred = model.predict(X_test) # loss mse = np.mean((y_pred - y_test)**2) mse_list.append(mse) print(f"MSE(LOOCV): {np.mean(mse_list)}") print(f"std: {np.std(mse_list)}") |
|
1 2 |
MSE(LOOCV): 1.0675673489857438 std: 2.099794455177631atest |
毎回のイテレーションでいられた mse を mse_list に append し,それをイテレーションの最後に平均をとっています.コード自体は何も難しくないと思います.(毎回の評価に使うデータはひとつなので,平均を取る必要はないんですが,汎用的なコードにしたいのでここでは毎回 np.mean で平均をとっています)
LOOCVの欠点

そうなんです.LOOCVは非常にコストがかかるという欠点があります.
だって学習データの数だけモデルを構築するなんて,めちゃくちゃ大変ですからね!データ数が多い場合や,一つのモデルを構築するのに時間がかかる場合は現実的ではありません!
そこで考えられたのが次の記事で紹介するk-Fold Cross Validationです.最も一般的に使われている汎化性能を測る手法なので次回の記事で使えるようにしましょう!
まとめ
今回は汎化性能を測る手法としてLOOCVを紹介しました.
- LOOCVはLeave-One-Out Cross Validationの略
- LOOCVは,ひとつだけテストデータとして使い,残り全てのデータを学習データとしてモデルを構築し精度を測り,それを全データが一度テストデータになるようにデータの数だけイテレーションをして,得られた全データ分の評価を平均することで汎化性能を測る
- LOOCVは,手元のデータのほとんどを学習データに使うことができることと,ランダム性がないので毎回同じ結果を得ることができることが利点である
- LOOCVは,データの数分モデルを構築する必要があるため,非常にコストが高く,データ数が多かったりモデル構築に時間がかかるアルゴリズムの場合は現実的には使えない
次回は,hold-outとLOOCVの中間的な手法であるk-Fold Cross Validationについて解説します!実際の業務では最も使われる手法なので超重要記事となります.
追記) 次回の記事を書きました!