







データサイエンス入門の機械学習編第9回です!(講座全体の説明と目次はこちら)
追記)機械学習超入門動画講座を公開しました!動画で効率よく学習をしたい人はこちら(現在割引クーポン配布中です)
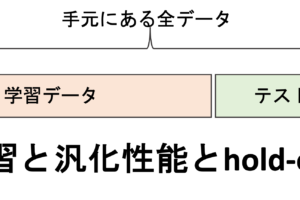
前回の記事では汎化性能を測る手法としてLOOCVについて述べました.
LOOCVは,データの数やモデル構築が簡単な場合はいいんですが,一般に機械学習は学習データが多かったり,モデル構築に時間がかかることが多いです.(高い精度のモデルを構築するには,大量のデータが必要だったり,計算コストが高いアルゴリズムを使う必要がでてきます)
そこで,今回の記事で紹介するk-Fold Cross Validation (k-Fold交差検証)の出番です.K-Fold Cross Validationは,hold-outとLOOCVの中間的な手法で,実際の業務では最も使われる汎化性能の測定手法です.
なので,今回の記事でしっかりk-Fold Cross Validationを学び,自分で学習したモデルの汎化性能を測定できるようにしましょう!
目次
k-Fold Cross Validation
k-Fold Cross Validationは,hold-outとLOOCVの中間のような手法です.日本語ではk-Fold交差検証といったりしますが,日本語でもCross Validation(クロスバリデーション)というので本講座では英語表記で書いていきます.また,略してk-Fold CVと略したり,単にCross Validation やCVといったらk-Fold Cross Validationを指します.
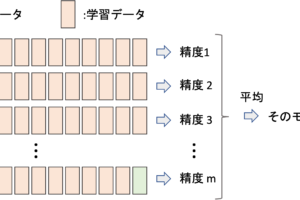
k-Fold Cross Validationは,手元のデータをk個のグループに分割して,k個のうちひとつのグループをテストデータとして,残りのデータを学習データとします.それを全てのグループがテストデータになるようk回繰り返します.
図にするとわかりやすいと思います.
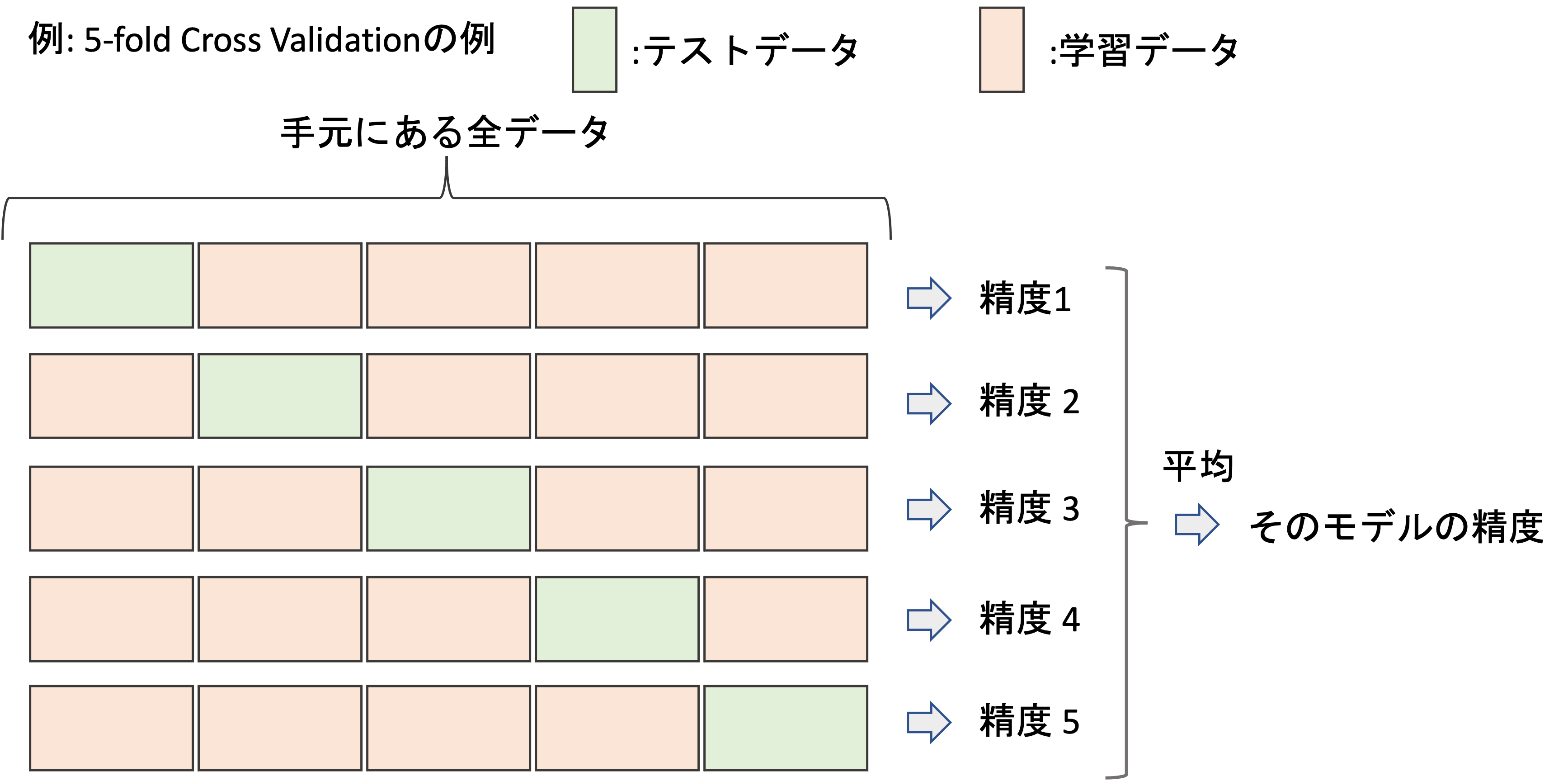
上図はk=5の例です.
データを5分割して,それぞれのグループをテストデータ,それ以外のデータを学習データにしてモデルを構築し精度を測ります.(LOOCVでは各データで行われていたことが,k-Fold Cross Validationでは各グループごとに行われるということですね,)
これを5回繰り返すので5つの結果がでますが,それを平均した値を最終的な精度の結果とします.この辺りはLOOCVと同じです.
このように,各データやグループに分けて交差(Cross)させて検証(Validation)するので,Cross Validationというのですね!
k-Fold Cross ValidationをPythonで実装する
それでは今回もPythonでk-Fold Cross Validationを実装してみましょう!
前回同様,今回もtipsデータセットを使って,total_billからtipを予測する予測モデルを構築し,k-Fold Cross Validationで汎化性能を測ってみましょう.
|
1 2 3 4 5 |
import numpy as np import seaborn as sns df = sns.load_dataset('tips') X = df['total_bill'].values.reshape(-1, 1) y = df['tip'].values |
k-Fold Cross ValidationをPythonで実装するには, scikit-learn.model_selection の KFold クラスを使います.前回やった LeaveOneOut クラスと同じ要領で使うことができます.例えば以下のように cv インスタンスを生成し, cv.split() に学習データ X を入れると,それぞれの交差の train_index および test_index を返すジェネレータの役割をします.
インスタンス生成時の引数は, n_splits にk, random_state に乱数の種, shuffle にbooleanをセットしてグループ分けの前にシャッフルするかを決めます.
エラーが発生しました。後でもう一度やり直してください。 |

上記のコードを実行すると, train_index と test_index がそれぞれのイテレーションで異なっているのがわかると思います.
今回はk=5の5-Fold Cross Validationを実装してみましょう.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from sklearn.model_selection import KFold cv = KFold(n_splits=5, random_state=0, shuffle=True) model = LinearRegression() mse_list = [] for train_index, test_index in cv.split(X): # get train and test data X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] # fit model model.fit(X_train, y_train) # predict test data y_pred = model.predict(X_test) # loss mse = np.mean((y_pred - y_test)**2) mse_list.append(mse) print(f"MSE(5FoldCV): {np.mean(mse_list)}") print(f"std: {np.std(mse_list)}") |
|
1 2 |
MSE(5FoldCV): 1.080211088394392 std: 0.16170100507039514 |
これも,前回の記事と同じですね.
毎回のイテレーションで sme を計算して,その結果を sme_list に入れて最後に平均を求めています.
もっと簡単にscikit-learnでCross Validationを実行する
先のコードや前回のLOOCVのコードでは, .split() をcallしてイテレーションを回す必要がありました.
実は,scikit-learnにはもっと手軽にCross Validationを実行できる関数があります.
めちゃくちゃ便利でよく使うので,是非使えるようにしましょう!!
scikit-learn.model_selection の cross_val_score 関数を使います. cross_val_score 関数には,主に以下の引数を入れます. estimator : scikit-learnの機械学習モデルのインスタンスX : 学習データのX
y : 学習データのy
scoring : 計算する評価指標(文字列で指定)(後述)
cv : KFold や LeaveOneOut のインスタンスでCross Validationをするジェネレータ
n_jobs : 並列処理の際のプロセッサーの数. -1 を指定すると使える全てのプロセッサーを割り当ててくれる
先ほどの5-Fold Cross Validationを cross_val_score を使って実行すると以下のようになります.
|
1 2 |
from sklearn.model_selection import cross_val_score scores = cross_val_score(model, X, y, scoring='neg_mean_squared_error', cv=cv, n_jobs=-1) |
すると,各交差での scoring に指定した評価指標をリストにして返してくれるので,以下のように平均を取ればOKです.
|
1 |
np.mean(scores) |
|
1 |
-1.0802110883943918 |
今回はMSE(mean squared error)を指標にしたかったので, scoring 引数には "neg_mean_squared_error" を指定しました.
scoring 引数に指定する文字列は公式ドキュメントに一覧があるので確認してください. cross_val_score 関数に使われる精度指標は基本的に「大きい方が精度が良い」ようにしています.SMEは”損失”を表す指標なので,そのままでは「小さい方が良い」指標になってしまうので,負の符号をつけて「大きい方が良い」ようにしています.そのため, scoring に指定している文字列にもnegatedのnegが接頭辞にあり,結果も不の値の-1.08になっているのがわかります.
符号以外は先のコードの結果と一致していますね.このように,イテレーションを回すことなく一行でCross Validationを実行できる素敵関数なのです!!
LeaveOneOut のインスタンスでも同様にしてLOOCVを実行できます.興味がある人は試して,前回の結果と同じになることを確認しましょうまとめ
今回はk-Fold Cross Validationのやり方とその実装を紹介しました.Cross Validationの結果をみると,それぞれの交差で(当然ですが)結果が多少異なっているのがわかると思います.ひとつひとつの交差ではhold-outが行われていると考えると,どれだけhold-outはランダム性があり分散が高いかがわかると思います.
普通機械学習のモデルを評価する際にはk-Fold Cross Validationでの評価の結果を報告するのがほとんどです.また,よく使われるのはk=5とk=10なので,これも覚えておきましょう!
- k-Fold Cross Validationは,最も一般的に使われる汎化性能を測る手法
- k-Fold Cross Validationは,hold-outとLOOCVの中間的な手法であり,k個のグループに分けてCross Validation(交差検証)する
- scikit-learn.model_selection の KFold クラスを使ってk-Fold Cross Validationを実装する
- scikit-learn.model_selection の cross_val_score 関数を使うことで簡単にCross Validationを実行できる
次回の記事では,回帰モデルの評価指標について解説します.今まではMSEを使ってましたが,他にも回帰モデルを評価する指標があるので使えるようにしましょう!
それでは!
追記)次回の記事書きました!






[…] […]