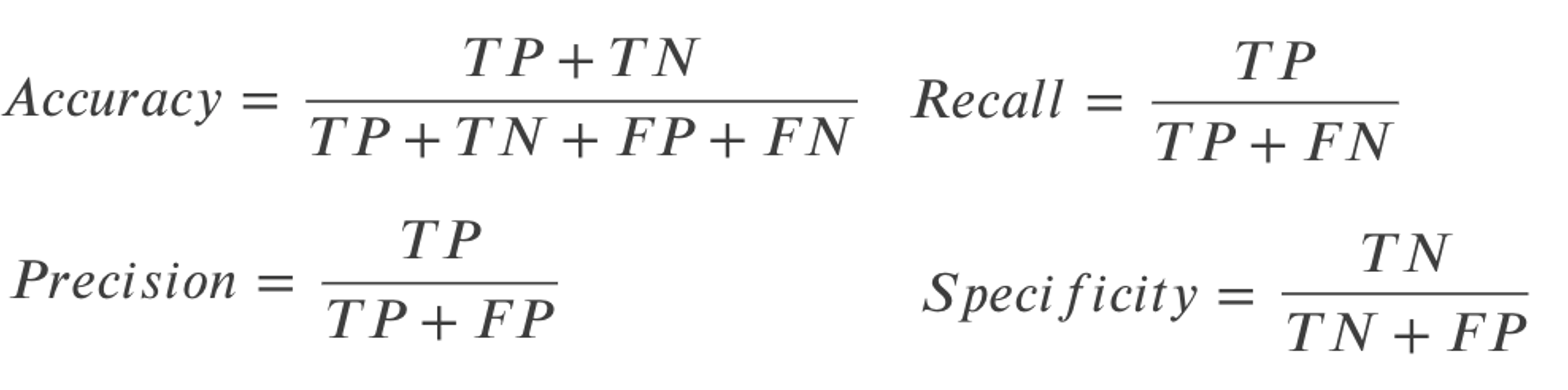
データサイエンス入門の機械学習編第20回です.(講座全体の説明と目次はこちら)
追記)機械学習超入門動画講座を公開しました!動画で効率よく学習をしたい人はこちら(現在割引クーポン配布中です)
前回の記事ではTP, TN, FP, FNやConfusion Matrix(混同行列)を紹介しました.
今回の記事ではこれらを使って表せれる様々な精度指標を紹介します.数はありますが,どれも超重要です.
機械学習をする上で,一つも逃すことはできません.それでは見ていきましょう!
目次
分類器の精度指標

分類器の精度指標を見てみましょう!一覧にするとざっとこんな感じです〜
- Accuracy (正解率)
- Precision (適合率)
- Recall (再現率)
- Specificity (特異度)
- F値 (F-score)
- AUC (ROC曲線)
- 交差エントロピー(Log loss)
ちょっとまって!笑
たくさんあるように見えますが,結構どれも繋がってるので覚えやすいです.全然難しくもないので簡単に理解できるはず♪
F値 (F-score),AUC (ROC曲線),交差エントロピー(Log loss)は次回の記事以降で紹介します.今回は上4つだけ!
Accuracy (正解率)
Accuracy(正解率)は,その名の通り全てのデータの中でどれくらい正解しているかを表す指標です.英語名がよく使われるので是非英語名で覚えてください.
数式で表すと
$$Accuracy=\frac{TP+TN}{TP+TN+FP+FN}$$
ですね.これは分かりやすいと思います.正解の数/全データ ってことです.
機械学習を勉強していない一般の人にも馴染みのある指標かと思います.
PythonでAccuracy (正解率)を計算する
sklearn.metrics.accuracy_score で簡単に計算することができます.こちらも今までのmetrics同様, y_true と y_pred を渡します.前々回の多項ロジスティック回帰のモデルの評価指標を見てみましょう!(コードの学習部分については前々回の記事を参考にしてください.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import seaborn as sns from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split # データロード df = sns.load_dataset('iris') # 学習データとテストデータ作成 X = df.loc[:, df.columns!='species'] y = df['species'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # モデル構築 model = LogisticRegression(penalty='none') model.fit(X_train, y_train) # 予測(ラベル) y_pred = model.predict(X_test) # accuracy accuracy_score(y_test, y_pred) |
|
1 |
0.9555555555555556 |
つまり,今回のテストデータの95.5%は正しく分類できているということになります.
今回の例のように,Accuracyの場合は多クラス分類でも2値分類同様の式を使えます.正しく分類できた数がTP, TNになるので,その数を全データ数で割ればOKです.これは後述するmicro平均というものになります.
しかし,Accuracyには問題点があります.評価するデータセットのうち,PositiveとNegativeの割合に偏りがある場合は注意が必要です.
例えば難病を分類するモデルを考えてみましょう.ほとんどの人は陰性(Negative)で,1%の人だけが陽性(Positive)だった場合,そのモデルが100%全てのデータに対して単に”Negative”と予測するゴミモデルだったとしても,99%のデータに対して正しく予測できてしまっているので,Accuracy=99%になってしまいます.
このようなケースでも正しく精度を計測するためには次に説明する他の指標たちが必要になってきます.
Precision (適合率)
適合率は,“陽性”と分類した中で実際に”陽性”だった割合です.英語での読み方の方が圧倒的に使われるのでこちらも英語表記で覚えてください.
つまり,「あなたは病気です!」って言った人のうち,どれだけの人が本当に病気だったかってことですね.
数式で表すと
$$Precision=\frac{TP}{TP+FP}$$
です.
PPV(Positive Predictive Value)ということもあります.こちらも頭に入れておくといいです.(ドメインや人によって言い方が違うところがめんどくさいんですよね...)
多クラスの場合は工夫が必要です.あるクラスをPositiveとしてその他のクラスをNegativeとすると,クラスの数だけパターンができてしまうからです.
そのため,普通は各クラス毎のPrecisionを計算して,それを単純に算術平均します.これをmacro平均と言います.
PythonでPrecision (適合率)を計算する
sklearn.metrics.precision_score で簡単に計算することができます.こちらも今までのmetrics同様, y_true と y_pred を渡します.多クラスの場合は average 引数に None , 'micro' , 'macro' を渡します.他にも種類があるんですが,今回の講座では割愛します.(詳細は公式ドキュメントをご確認ください.)デフォルトは 'binary' で,2値分類用になってます.
None を渡すと,各クラスのPrecisionを計算してくれます. 'macro' を渡すと上述した各クラスのPrecisionの算術平均を計算します. 'micro' を渡すとAccuracyと同じ値を計算します.(先程のコードの続きとして実行してください. y_true は,今回のコードでは y_test という変数に入っていることに注意です.)|
1 2 3 4 5 6 7 |
from sklearn.metrics import precision_score # None print(precision_score(y_test, y_pred, average=None)) # macro print(precision_score(y_test, y_pred, average='macro')) # micro print(precision_score(y_test, y_pred, average='micro')) |
|
1 2 3 |
[1. 0.94444444 0.90909091] 0.9511784511784511 0.9555555555555556 |
macro平均は,クラス毎に値を計算して平均をとるいわゆる「クラスレベルの平均」だったんですが,micro平均はもっと細かいレベルの,各データレベルの平均だと思ってください.
macro平均ではクラス数に偏りがあると実際の精度と異なってしまう場合があります.
例えばA, B, Cという3つのクラスがあって,それぞれデータ数が100, 50, 10だっとします.それぞれのクラスのAccuracyが0.1, 05, 0.3だった場合,macro平均を取ると,\(\frac{0.1+0.5+0.3}{3}=0.3\)ですよね?でも,正解の数はそれぞれ10, 25, 3なのでAccuracyは\(\frac{10+25+3}{160}=約0.24\)となります.
microは言うなればGlobalに平均を取ってる感じです.全体で平均を取っているので,各データレベルでの平均と言えるでしょう.
ではこれをPrecisionに適用するとどうなるか?Precisionの式は\(\frac{TP}{TP+FP}\)でしたが,これをデータ全体でTP,FPを数えると,結局他のクラスのTN, FNもカウントされてしまいます.つまりTPはTP+TN(あるクラスのTNは他のクラスのTPになるので)となり,FPはFP+FN+TN(同様に,あるクラスのFPは他のクラスのFNもしくはTN)になり,結果\(\frac{TP+TN}{TP+TN+FP+FN}\)となりこれはAccuracyの式になります.
つまり,Precisionのmicro平均はAccuracyと同じになるということです.これは後述するrecall, specificityやF値についても同じです.なので,多クラスの場合は基本的にはmacro平均をとると思っておきましょう!
Recall (再現率)
Recall(再現率)は,Positiveのデータをどれだけ正しくPositiveと言えたかです.これも英語名で覚えておきましょう.また,(特に医療系の分野では)Sensitivity(感度)ということもありますが,これは同じ指標を指しています.
つまり,「病気の人をどれだけ正しく病気と言えたか」ですね.医療系のような陽性データを見逃したくない(誤診したくない)ようなケースでは高いRecallを目指します.True Positive Rate (真陽性率)とも言います.
式は
$$Recall=\frac{TP}{TP+FN}$$
です.
個人的には一番よく会話ででてくる指標な気がします.自分が医療系AIの分野に関わることが多いからでしょうか...
PythonでRecall (再現率)を計算する
sklearn.metrics.recall_score で簡単に計算することができます.こちらも今までのmetrics同様, y_true と y_pred を渡します.また, precision_score() 同様,多クラスの場合は average 引数に None , 'macro' , 'micro' などの値を入れることができます.|
1 2 3 4 5 6 7 |
from sklearn.metrics import recall_score # None print(recall_score(y_test, y_pred, average=None)) # macro print(recall_score(y_test, y_pred, average='macro')) # micro print(recall_score(y_test, y_pred, average='micro')) |
|
1 2 3 |
[1. 0.94444444 0.90909091] 0.9511784511784511 0.9555555555555556 |

Recallの精度だけをみても正しくモデルを評価できないことに注意しましょう.予測結果を全て”Positive”と返すゴミモデルでも,Recallは100%になるからです.Recallと合わせてみるのが先ほどのPrecisionや,次に説明するSpecificityです.
Specificity (特異度)
どんどんいきましょう〜!Specificity(特異度)は,“Negative”のデータを正しく”Negative”と分類できたデータの割合です.つまりRecallの”Negative”版です.True Negative Rate (真陰性率)とも言います.
$$Specificity=\frac{TN}{TN+FP}$$
「予測結果を全て”Positive”と返すゴミモデルにおけるRecall=100%」は,Specificityで陰性(Negative)データもちゃんと拾えてるかを見ればOKです.このようなゴミモデルではSepecifictyは0になります.
例えば,「医師の誤診断をアラートするAI」を開発したいとした時には高いSpecificityが必要になったりします.医師が陰性と診断したデータに対して予測モデルを使って医師の偽陰性を拾うようなケースです.この場合,Specificityが低いとモデルの偽陽性(FP)が多くなってしまい狼少年的なAIになってしまいますからね!
PythonでSpecificity (特異度)を計算する
実は,Specificityはscikit-learnには実装されていません.(なんでなんでしょう...知っている人いたら教えてください.)
PythonでSpecificityを計算するには色々あるんですが,先の recall_score を使って簡単に求めることができます.
Recallのデータの陽性と陰性を逆にすればSpecificityになることをうまく使います.
|
1 2 3 4 5 |
import numpy as np res = [] for c in model.classes_: res.append(recall_score(np.array(y_test)!=c, np.array(y_pred)!=c)) res |
|
1 |
[1.0, 0.9629629629629629, 0.9705882352941176] |
このように,各データに対して !=c ( c には各ラベルが入ります.)を実行することで, y_true と y_pred を True と False の2値にしますが,この時 != としているので,positiveには False 、negativeには True が入りますが, recall_score は True を陽性(positive)として計算するので,結果Specificityが計算されます.
少しトリッキーでややこしいんですが,このようにRecallを求める関数を使って簡単にSpecificityを求めることができます.(もちろん上記のコードで != を == に置き換えたらRecallが計算されます.興味がある人は試してみてください.)
この平均をとればmacro平均のSpecificityになります.
|
1 |
np.mean(res) |
|
1 |
0.9778503994190269 |
SpecificityもRecallと同じように,全てのデータに対して’Negative”と予測するゴミモデルでもSpecificity=100%となってしまうので注意が必要です.
この辺りは,次回以降の記事で解説するF値やROCという指標を使って解決します.
まとめ
今回は,分類器の精度指標の一部を紹介しました.
- Accuracy: 全データのうち正解した割合.\(\frac{TP+TN}{TP+TN+FP+FN}\)
- Precision: Positiveと分類した中で実際にPositiveだった割合. \(\frac{TP}{TP+FP}\)
- Recall: Positiveのデータのうち正しくPositiveと分類した割合. \(\frac{TP}{TP+FN}\)
- Specificity: Negativeのデータのうち正しく”Negative”と分類できたデータの割合. \(\frac{TN}{TN+FP}\)
これらの指標単体だけではモデルの精度の良さを表すには不十分であることも述べました.
実際の業務ではこれらの指標を組み合わせるのが一般的です.
次回以降の記事では,これらの指標を組み合わせた指標を紹介していきます!
それでは!
追記)次回の記事書きました!