こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第15回です(講座の目次はこちら).ここまで続けてこれている人,どれくらいの割合いるのかな笑
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
今日はgroupbyについて解説します.groupbyというのは以下のような操作です.
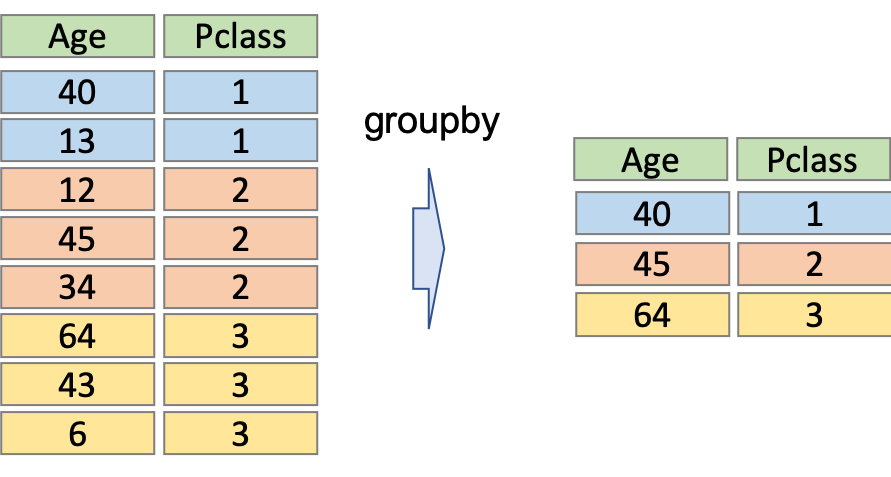
SQLを扱ったことがある人はイメージしやすいかもしれませんが,上の例はPclassでgroupbyして,Ageにはそのグループの最大値を取っている例です.他にも平均値をとったり,数をカウントしたり,様々な関数(aggregate functionと呼びます.)を使うことができます.
データを扱う上で,各々のグループで数値を比較することがよくあります.頻出操作の一つなので覚えておきましょう!
目次
.groupby().関数()で,groupbyする
今回もタイタニックデータを使いましょう!(タイタニックデータについては第11回を参照ください)
|
1 2 |
df = pd.read_csv('train.csv') df |
それでは試しに,Pclassでgroupbyしてみましょう.Pclassは1, 2, 3の3種類ありますが,試しにそれぞれのグループの平均値をaggregate functionに指定します.
こんな風に書けます↓
|
1 |
df.groupby('Pclass').mean() |
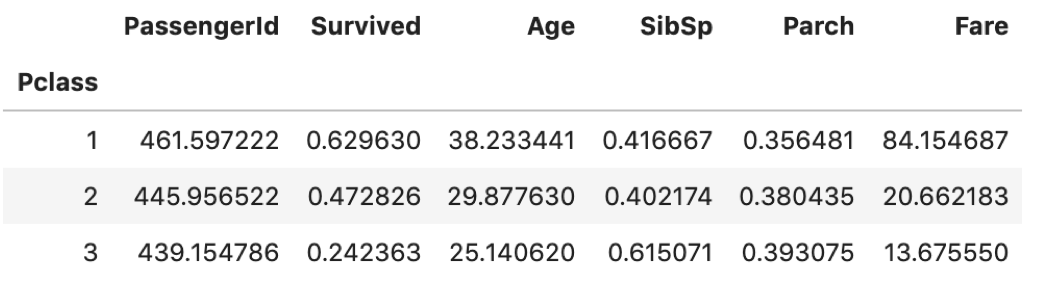
df.groupby(‘Pclass’)だけではgroupbyしてグループにまとめた後になにすればいいかわからないですよね?なのでその後に.mean()や.count()などの関数をコールします.
試しにPclass==1の時の平均が正しいか確認してみましょう.
まず,Pclass==1をフィルタします.フィルタ操作については第13回を参照ください.
|
1 |
df[df['Pclass'] == 1] |
これだけだと各カラムの平均はわからないので, .descirbe() で統計量を取ってみましょう.( .describe() については第12回を参照ください.)
|
1 |
df[df['Pclass'] == 1].describe() |
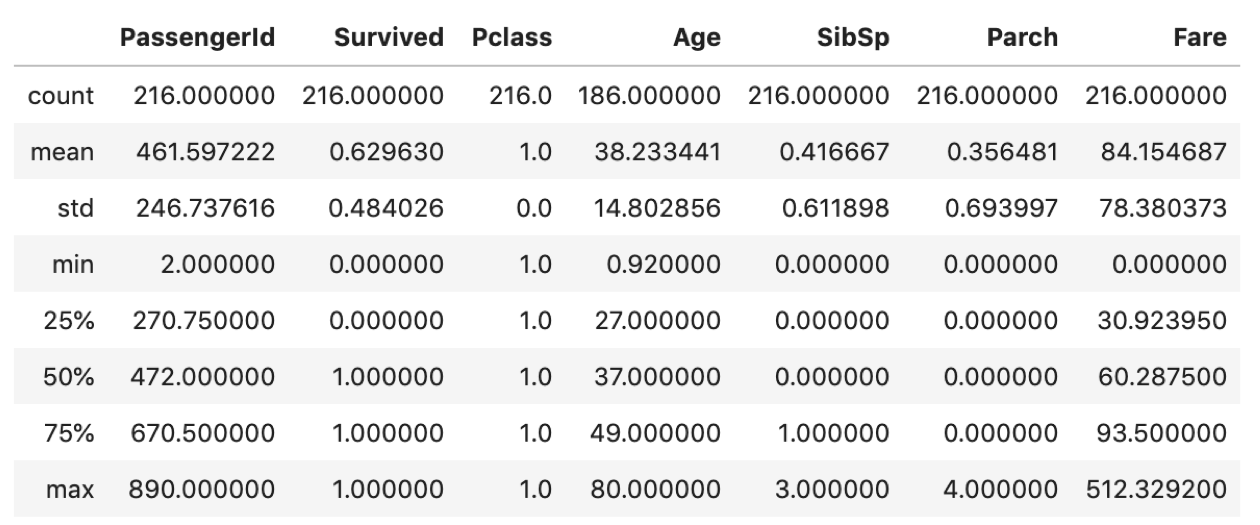
これだけでも確認できますが,今回はmeanにしか興味ないのでindexにmeanを指定してSeriesを取り出します. .loc[] については第12回を参照ください.
|
1 |
df[df['Pclass']==1].describe().loc['mean'] |
|
1 2 3 4 5 6 7 8 |
PassengerId 461.597222 Survived 0.629630 Pclass 1.000000 Age 38.233441 SibSp 0.416667 Parch 0.356481 Fare 84.154687 Name: mean, dtype: float64 |
df.groupby('Pclass').mean() の結果と見比べてみてください.一致してますね.フィルタで一つ一つのグループの統計量を取っていたら大変ですが,groupbyを使えば簡単に各グループの統計量を確認することができます.
また, df.groupby('Pclass').mean() の結果をみるに,Pclassの値が大きくなるにつれ,Survivedの値が減っているのがわかります.Ageも減っているし,Fareも当然安くなっています.groupbyすることで簡単にデータのインサイトを得ることができます.
非常に便利です.
groupby後は,indexにgroupbyの第一引数である by に指定した値をとります.上の例ではPclassの値(1, 2, 3)です.groubyの結果も当然DataFrameなので, .loc[] で特定のグループのSeriesを取ってくることができます.
|
1 |
df.groupby('Pclass').mean().loc[1] |
|
1 2 3 4 5 6 7 |
PassengerId 461.597222 Survived 0.629630 Age 38.233441 SibSp 0.416667 Parch 0.356481 Fare 84.154687 Name: 1, dtype: float6 |
慣れたら頭のなかで結果を想像しながらドット( . )で繋げていって値を取れるようになります.これくらいの長さであれば問題ないです.長すぎるとわかりにくくてチームの人から嫌われるので注意しましょう.
統計量の他にも, sum() や count() も使えます. sum() は合計を, count() は数のカウントを表示します.試してみてください.
.groupby[].describe() で,グループ別のdescribe()を一気に表示してくれます.|
1 |
df.groupby('Pclass').describe() |

なにがなんだかわからないですねw
左からPassengeridのグループごとのdescribe()結果,Survivedのdescribe()結果,,,Fareのdescribe()結果と並んでいます.
試しにAgeだけ取り出してます.当然これもDataFrameなので.以下のようにカラムを指定して取り出すことができます.
|
1 |
df.groupby('Pclass').describe()['Age'] |
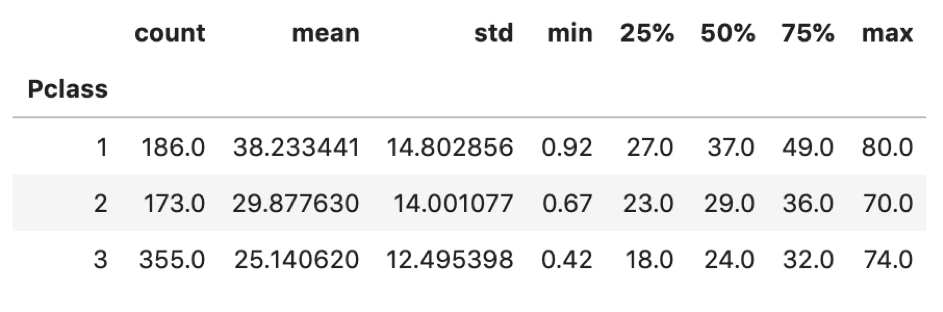
このように.特定のカラムのグループ別のdesribe()を確認できます.これ,めっちゃ便利なのでぜひ使ってみてください.
あと,JupyterではDataFrameのカラムや行が表示しきれない場合は省略されて表示されます.
省略させずに全てのカラムを(もしくは全ての行を)表示させたい場合はそれぞれ以下を実行することで省略させないようにすることができます.試してみてください.参考ページはこちら
|
1 2 3 4 |
# カラムを省略せずに表示 pd.set_option('display.max_columns', None) # 行を省略せずに表示 pd.set_option('display.max_rows', None) |
(上級者向け)groupbyの結果をfor文でまわす
やりたいことがmin()やmax()のような単純な操作ではなく,複雑な処理をしたい場合には,groupybyの結果をfor文で回して処理します.
本当はもっといい方法があるのかもしれませんが,私はこれで済ませます.わかりやすい方法なのでこれでいいでしょう.
もしかしたらPython初心者には難しく感じるかもしれません.今は理解できなくてOKです.「こういうこともできる」程度に覚えておいてください.
.groupby() の結果はfor文で回すことができ,(index, groupbyされたDataFrame)のタプルの形で回せます.どういうことかというと以下の例をみてください. i と group_df にはそれぞれ1, 2, 3およびPclass==1, ==2, ==3でフィルタされたときのDataFrameが格納されています.(例として len() で各DataFrameのレコード数を表示してます.)
|
1 2 |
for i, group_df in df.groupby('Pclass'): print("{}: group_df's type is {} and has {}".format(i, type(group_df), len(group_df))) |
|
1 2 3 |
1: group_df's type is <class 'pandas.core.frame.DataFrame'> and has 216 2: group_df's type is <class 'pandas.core.frame.DataFrame'> and has 184 3: group_df's type is <class 'pandas.core.frame.DataFrame'> and has 491 |
このforf文のなかに処理を入れます.
例えば,各Pclassのグループの中で,各レコードが何番目にFareが高いか数字を振ってみましょう!(あまりいい例が思いつかなかった...w)
|
1 2 3 4 5 6 7 8 |
df = pd.read_csv('train.csv') results = [] for i, group_df in df.groupby('Pclass'): sorted_group_df = group_df.sort_values('Fare') sorted_group_df['RankInPClass'] = np.arange(len(sorted_group_df)) results.append(sorted_group_df) result_df = pd.concat(results) result_df |
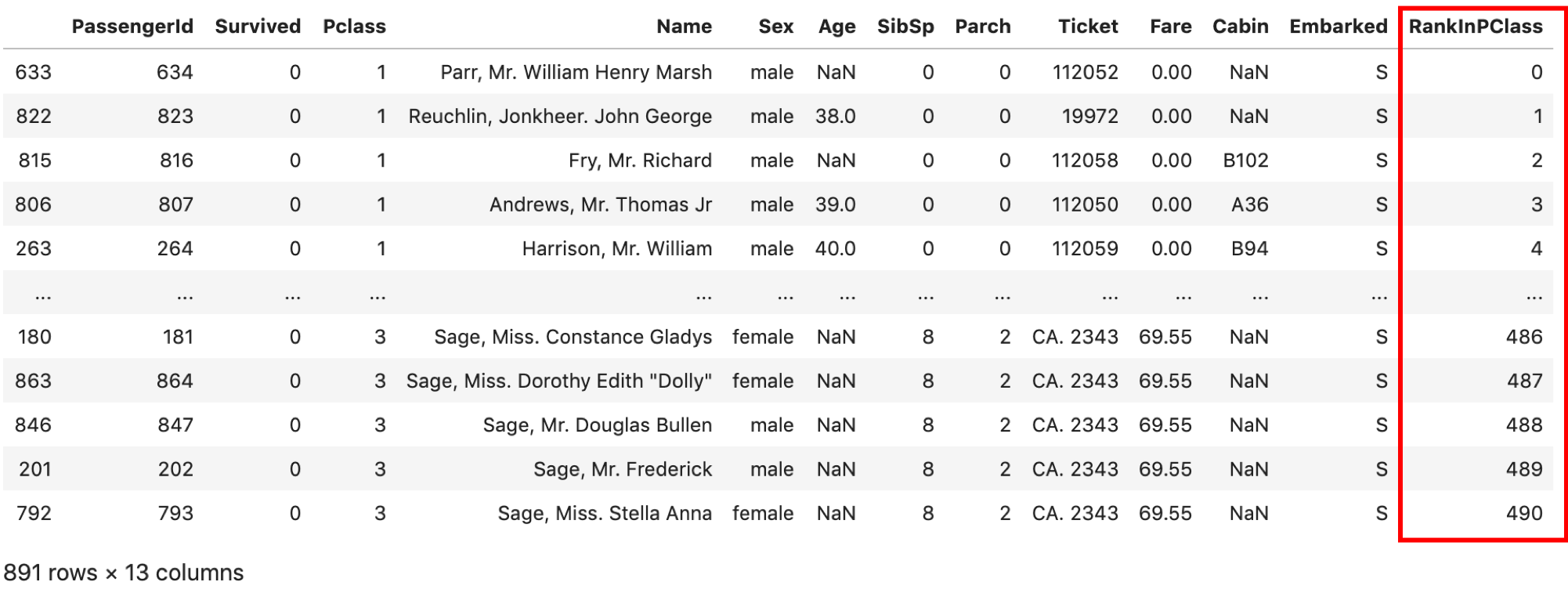
forの中でgroupbyされたDataFrameを’Fare’カラムでソートしてます.ソートは .sort_values(カラム名) でソートされます.
その後’RankInPClass’に0からgroupbyされたDataFrameのレコードの数だけ数字を振っていき, results リストに格納します.
results リストには各groupbyされたDataFrameが入っているので,それを最後 pd.concat() 関数で連結させます. pd.concat() 関数や .sort_values() 関数についてはまた改めて紹介するので,今回は一例として「こんなことができる」程度に覚えておけばいいと思います.あまり理解できてなくても気にせず次に進みましょう!(concat関数については次回を,sort_values関数については第18回をご参照ください)まとめ
今回は.groupbyについて紹介しました.
特に groupby('カラム名A').describe()['カラム名B'] で,カラムAのグループ別のカラムBの統計量を見れるのは結構便利です.覚えておきましょう!
実際に自分で手を動かしながら,タイタニックデータを色々いじってみてください.ただブログを読んでいるだけだと上達は難しいですよ!
それでは!
次回はテーブル結合の関数を使って,DataFrameを連結させます!
データサイエンスのためのPython入門16〜DataFrameのテーブル結合を完全解説(merge, join, concat)〜