機械学習入門講座第35回です.(講座全体の説明と目次はこちら)
追記) 機械学習超入門本番編にて,ハイパーパラメータのチューニングについてさらに詳しく解説をしています!
長かった本講座も今回の記事で最終回です.ここまで学習した人は,機械学習についてかなり詳しくなれたことと思います.
今回の記事は最適なモデルやハイパーパラメータを探索するやり方を解説します.
モデルを実際に構築する際には様々なアルゴリズムで様々なハイパーパラメータを試し,最終的に精度がいいモデルを選択するのが一般的です.
高精度のモデルを構築する必要がある場合は必ず実施するものであり,これをうまくやれるかがデータサイエンティストとしてのスキルだったりもします.
Scikit-learnのPipelineとGrid Searchと呼ばれるものを組み合わせることで簡単に行うことができるので,その辺りも解説していきます.
それではみていきましょう〜!
目次
GridSearchでハイパーパラメータをチューニング
SVMの”C”や決定木の”深さ”のように,それぞれの機械学習アルゴリズムにはハイパーパラメータ(hyperparameter)がありました.
本講座ではそこまで厳密に区別しませんでしたが,使い手が任意の値を指定するパラメータをハイパーパラメータといい,モデルが学習の過程で自動で最適化するパラメータ(\(\theta\)など)を単にパラメータといい,この二つを区別して呼ぶことが多いです.
高精度のモデルを構築するためには最適なハイパーパラメータを見つける必要があります.この作業を「ハイパーパラメータをチューニングする」と言います.

通常,やり方は二種類
- Random Search: あらかじめ決められた範囲でランダムなハイパーパラメータを組み合わせて最も精度が高い組み合わせを探します.
- Grid Search: あらかじめ決めた値を”総当たり”で組み合わせて最も精度が高い組み合わせを探します.
Random Searchでは思いがけないハイパーパラメータを組み合わせることができるというメリットがありますが,かなり時間がかかるというのが実情です.
追記)機械学習超入門本番編では,これらに加えて最適化手法を用いた高度なテクニックも紹介しています.
本記事ではGrid Searchのやり方を紹介します.まぁ実際にやるのはほとんどのケースでGrid Searchと言っていいでしょう
例えば下の図のように,パラメータ1とパラメータ2の候補の値をあらかじめきておきます.Grid Searchでは単純に総当たりしてハイパーパラメータの組み合わせでモデルを構築します.(下図はSVMの例です.実際にはさらに他のハイパーパラメータを掛け合わせることもあります.)
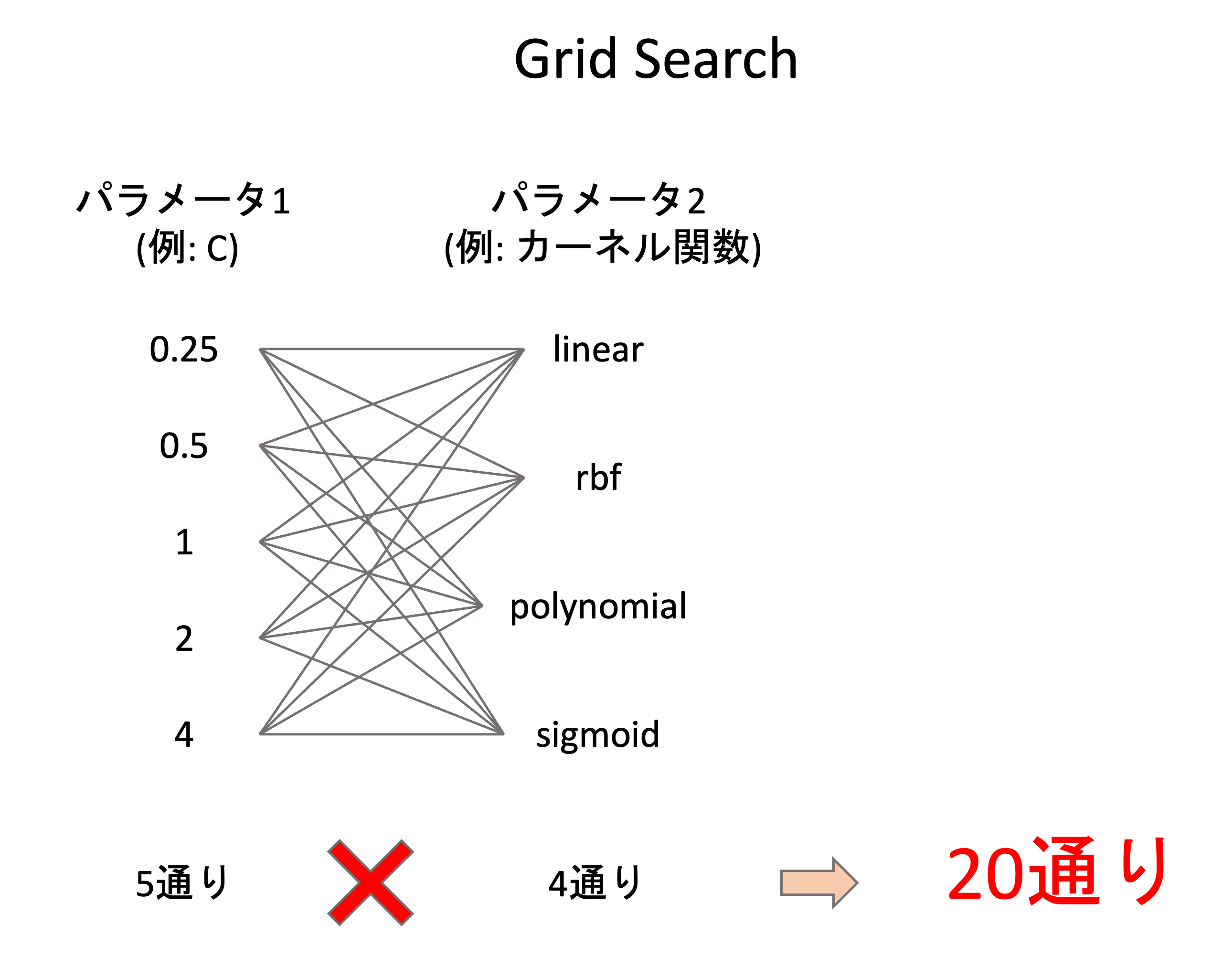
あらかじめ値をある程度決めておく必要がありますが,大抵モデルのハイパーパラメータというのはある程度とりうる値が決まっているので,それを事前に調べたり,他の論文や過去の事例で使われていたハイパーパラメータを調べればいいでしょう.
Grid Searchではそれぞれのハイパーパラメータの組み合わせ通りのモデルを構築し,それぞれの組み合わせでk-Fold CVを使って汎化性能を測ります.
PythonでGrid Searchを実施する
それでは早速PythonでGrid Searchによるハイパーパラメータのチューニングをやってみましょう!
scikit-learnにはすでに sklearn.model_selection.GridSearchCV クラスというのが実装されていて,簡単にGrid Searchすることができます.
使い方は簡単で,インスタンスを生成し, .fit() を実行するだけ.今まで扱ってきた機械学習モデルと同じですね!
インスタンス生成時に,以下の引数を入れていきます.
- estimator : .fit() できるモデルオブジェクト
- param_grid : Grid Searchするハイパーパラメータとその値のリストのディクショナリー
- scoring : 評価指標.文字列や自作の評価指標を入れる(文字列の場合はこちら,自作はこちらを参考)
- cv : k-Fold CVのオブジェクト
これだけ言われてもピンとこないので,実際にコードを見てみましょう!
データ準備
今回はいつも通りのタイタニックのデータを使います.
欠損値はdropし,質的変数はダミー変数にしておきます.
|
1 2 3 4 5 6 7 8 |
import pandas as pd import seaborn as sns df = sns.load_dataset('titanic') df = df.dropna() X = df.loc[:, (df.columns!='survived') & (df.columns!='alive')] X = pd.get_dummies(X, drop_first=True) y = df['survived'] |
モデル準備
今回はSVMを例にしてみます.それぞれのハイパーパラメータの評価を比較できるように, random_state を指定しておきます.
|
1 2 |
from sklearn.svm import SVC model = SVC(random_state=0) |
ハイパーパラメータの組み合わせディクショナリーを作成
ハイパーパラメータのリストをディクショナリー形式にしてGridSearchCVに渡します.
ディクショナリーのkeyにはモデルの引数名,valueにはそのハイパーパラメータの値のリストを指定します.
例えば以下のような感じ↓
|
1 2 |
param_grid = {'kernel': ['linear', 'rbf'], 'C': [2**i for i in range(-2, 3)]} |
パラメータCの値は,こちらの論文を参考にしました.あくまでも例なので,実際にはもっと幅広く設定してその後徐々に範囲を狭めていってもいいかと思います.カーネル関数は "linear" と ”rbf' のとりあえず二つです.多すぎると実行時間が長くなるので減らしてます
cvオブジェクトを作成
k-Fold CVのオブジェクトを作成します.詳細は第9回を参照ください.
分類タスクであれば,第31回でも使用した RepeatedStratifiedKFold クラスを使うのがいいです(回帰の場合は RepeatedKFold ).これは指定したk-Foldをさらに複数回実行します(Repeated).また,クラスの偏りが無いようにもとのクラスの割合をキープしてデータを分割してくれます(Stratified).
今回は5-Foldを3回繰り返すようにします.
|
1 2 |
from sklearn.model_selection import RepeatedStratifiedKFold cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=0) |
RepeatedStratifiedKFold では複数回”Repeat”するので時間がかかります.ただでさえGridSearchは何度もモデルを学習し時間がかかるので,時間を短縮したい人は,StratifiedKFoldクラスを利用しRepeatを無くしたり,5-Foldではなく3-Foldにして実行してみてください.
GridSarchCVオブジェクト作成&実行
それではこれらのオブジェクトを使ってGrid Searchしてみましょう!以下のように実行できます.
今回はシンプルに評価指標に 'accuracy' を採用してます.
|
1 2 3 |
from sklearn.model_selection import GridSearchCV grid_search = GridSearchCV(estimator=model, param_grid=svm_param_grid, scoring='accuracy', cv=cv) grid_search.fit(X, y) |
かなーり時間がかかりますが, .fit() が終了すると, .best_params_ や .best_score_ で最高精度のハイパーパラメータの組み合わせや,その精度を確認することができます.
|
1 |
print(grid_search.best_params_, grid_search.best_score_) |
|
1 |
{'C': 0.25, 'kernel': 'linear'} 0.7618118118118118 |
結果の詳細は .cv_results_ で確認できます.興味がある人は見てみてください!
そうなんです.GridSearchCVは便利なんですが,標準化などの前処理を組み込むことができません.標準化のような”学習データと検証データを分けてから実行するような前処理”は,CVの処理の中に組み込む必要があります.
これをうまくやってくれるのがPipelineと呼ばれるものです.GridSearchと組み合わせて使うことで簡潔に探索することができます.
Pipelineとは
Pipelineは,前処理とモデルを一つのオブジェクトとして扱うことができるものです.scikit-learnの sklearn.pipeline.Pipeline クラスを使います.
言葉で説明するよりも,実際にPipelineを使うとコードがどうなるのかをみた方がわかりやすいと思います!
PipelineなしでSVMを構築するやり方と,Pipelineありで構築するやり方を比較してみます.(どちらもデータセット X と y は先ほどのコードを流用します.)
Pipelineなしバージョン
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split # 学習データとテストデータ分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 標準化 scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) # SVMのインスタンス生成 (predict_probaが使えるようにprobability=Trueを指定) model = SVC(probability=True, random_state=0) #学習 model.fit(X_train_scaled, y_train) # テストデータを予測 X_test_scaled = scaler.transform(X_test) y_pred = model.predict_proba(X_test_scaled) |
Pipelineありバージョン
これをPIpelineクラスを使うと以下のようになります.
|
1 2 3 4 |
from sklearn.pipeline import Pipeline pipeline = Pipeline(steps=[('scaler', StandardScaler()), ('model', SVC(probability=True, random_state=0))]) pipeline.fit(X_train, y_train) y_pred_p = pipeline.predict_proba(X_test) |
かなりスッキリしましたね
Pipelineクラスのインスタンスを生成する際に, steps 引数にタプルのリストを渡しているのがわかります.
steps には, .fit() や .transform() が実装されているオブジェクトとその名前をタプル形式にして,それをリストにします.今回の場合,標準化→モデル構築という流れなので, [('scaler', StandardScaler()), ('model', SVC(probability=True, random_state=0))] というリストにします.
他に処理を入れたければ,同様にこのリストにタプル形式でいれればOKです!
あとはPipelineオブジェクトに対して .fit() や .predict_proba() を使って,他の機械学習モデル同様に学習や予測ができます.
PipelineなしバージョンとPipelineありバージョンの結果は等しい
それぞれの予測の結果は全く同じになります.
|
1 |
y_pred_p.all() == y_pred.all() |
|
1 |
True |
PipelineとGridSearchCVを組み合わせる
GridSearchCVでは,標準化のような前処理を含むことができなかったのですが,Pipelineを組み合わせることでそのような前処理を含めることができる上に,コードもスッキリします.
是非アルゴリズムやハイパーパラメータを探索する際にはPipeline+GridSearchの組み合わせで書けるようにしましょう!!
それではコードを書いていきます
ポイントとしては,GridSearchCVの estimator 引数にPipelineオブジェクトを渡し, param_grid 引数に渡すディクショナリーのキーには,Pipelineの”処理名__パラメータ名”のような命名規則(Naming convention)に従ったものを使います.
・・・・はい,言葉で説明してもピンと来ないと思うので,コードを見てみましょう!笑
Pipelineオブジェクト作成
まずPipelineオブジェクトを作ります.今回は先ほどと同様に標準化+SVMにしておきます.
|
1 |
pipeline = Pipeline(steps=[('scaler', StandardScaler()), ('model', SVC(random_state=0))]) |
param_dict作成
次に,GridSearchCVの param_grid 引数に渡すディクショナリーを作ります.
今回はPipelineを使っているので,Pipelineの“どの処理のパラメータなのか”がわかる必要がありますよね.なので,”処理名__パラメータ名”をキーにします.
|
1 2 |
svm_param_grid = {'model__kernel': ['linear', 'rbf'], 'model__C': [2**i for i in range(-2, 3)]} |
今回はSVMの処理を”model”という名前でPipelineを作っているので,”model__<param>”の形にしてキーにします.
GridSearchCVを実行
|
1 2 3 |
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=0) grid_search = GridSearchCV(estimator=pipeline, param_grid=svm_param_grid, scoring='accuracy', cv=cv) grid_search.fit(X, y) |
GridSearchCVの estimator にはPipelineオブジェクトを渡すことに注意しましょう.
あとは同様に .best_params_ や .best_score_ , .cv_results_ で結果を確認します.
ハイパーパラメータだけではなく複数のアルゴリズムのモデルに対しても探索をしたい場合は,アルゴリズムごと(例えばSVM用と決定木用とLasso用のような感じで)PipelineとGridSearchCVのオブジェクトを作り,for文で回して実行して結果を格納していけばOKです.
そして,最終的に高精度だったモデルを採用するわけです.場合によってはその後その最高精度のモデルとハイパーパラメータで手元にある全てのデータで学習をしたモデルを最終的なモデルとして採用することもあります(この場合,きちんとしたテストデータがない場合は,精度を測ることができないことに注意しましょう.)
今回も長くなってしまったのでこの辺りでまとめます.
まとめ
今回は最適なアルゴリズムやハイパーパラメータを探索するやり方を紹介しました.
- 最適なハイパーパラメータを探索することをチューニングするという
- ハイパーパラメータのチューニングにはGrid Searchというやり方があり,あらかじめ指定したハイパーパラメータの値を総当たりで組み合わせてモデルを学習&評価する
- 通常Grid Searchではk-Fold CVで汎化性能を計測することが望まれる
- Pipelineを使うことで標準化のような学習データとテストデータを分割した後に行う前処理をGridSearchに含むことができる上に,コードを簡潔に書くことができる
- アルゴリズムやハイパーパラメータのチューニングの際にはPipelineとGrid Searchを組み合わせて行う
高精度のモデルを探索する際には,PipelineとGrid Searchを組み合わせて行い,まずはよく使われるモデルとハイパーパラメータのレンジで探索を進めたり,他の事例などで使われている組み合わせで試したりして,その結果を見てさらに細かい範囲のハイパーパラメータを指定したりアルゴリズムを絞っていくことで最終的に高精度だったモデルを採用します.
今回の記事で,「データサイエンス入門講座: 機械学習編」は終わりです.
ここまで読んでいただいた方はありがとうございます&お疲れ様でした.かなりデータサイエンスの基礎力がついたと思います.
是非何度も読み返して自分のものにしてください!質問があれば随時コミュニティにて承っておりますので,是非日々の学習に活用してください!!
それでは!!