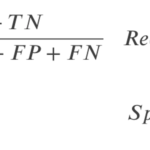
データサイエンス入門の機械学習編第19回です.(講座全体の説明と目次はこちら)
追記)機械学習超入門動画講座を公開しました!動画で効率よく学習をしたい人はこちら(現在割引クーポン配布中です)
前回までの記事で,ロジスティック回帰という分類アルゴリズムについて解説をしてきました!
モデルを構築することはできるようになりましたが,肝心のモデルの評価についてはまだ触れていませんでしたね.
今回の記事から分類器の評価指標について解説をしていきます!せっかく頑張ってモデルを構築しても,正しい評価指標で高い精度が出ていることが確認できないと意味がありません.
特に今回の記事では,分類器の評価指標を理解するのに必要&最も基礎となるTP, TN, FP, FNとConfusion Matrix(混同行列)と呼ばれるものを紹介します.
分類タスクは機械学習のメインディッシュです.精度指標なくしてそのメインディッシュを食べることはできないでしょう.
非常に重要な分野になるのでしっかり押さえておきましょう!
目次
TP, TN, FP, FN
分類器の精度指標の話をする前に,
- True Positive (真陽性:TP)
- True Negative (真陰性:TN)
- False Positive (偽陽性:FP)
- False Negative (偽陰性:FN)
について解説しておきます.
2値分類において,0を陰性(negative), 1を陽性(positive)と呼ぶことがあります.例えば病気であれば,病気であるケースを1とし,陽性:positive, 病気でないケースを0とし陰性:negativeとするのが一般的です.
さて,これらのpositive/negativeのデータに対して予測した結果,正解していることを真(True),間違っていることを偽(False)と言います.
そして,本当は陽性であるデータに対して正しく陽性と予測したケースを真陽性(True Positive: TP)といい,間違えて陰性と予測したケースを偽陰性(False Negative: FN)といいます.
同様に,本当は陰性であるデータに対して正しく陰性と予測したケースを真陰性(True Negative: TN)といい,間違えて陽性と予測したケースを偽陽性(False Positive: FP)といいます.


これは以下のように見ると覚えやすいかもしれません.
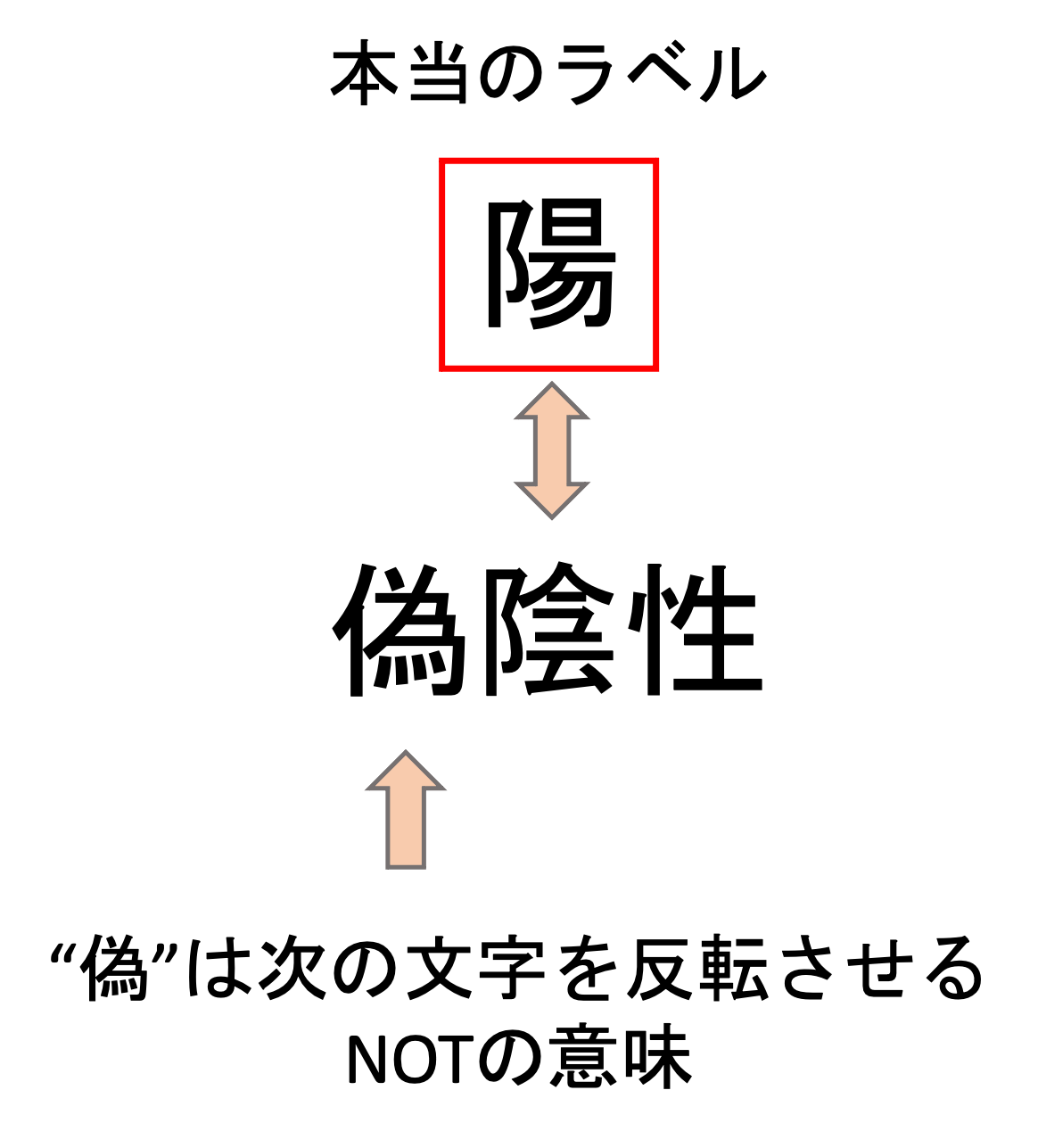
“偽”というのは”偽りの”という意味なので,「偽りの陰性」は本当は「陽性」なのがわかると思います.”偽”を”NOT”と見立てて,そのあとの文字を反転させると思えば,パッと頭の中で本当のラベルがどっちなのかイメージできます.逆に”真”は反転させず,そのまま捉えればいいでしょう.
英語での読み方もよく使われるので,必ずそちらでも覚えておきましょう.また,略称であるTP, TN, FP, FNも本当によく使います.
データサイエンティスト同士の会話では「False Positiveが多いので,False Positiveを減らすために〜」のように,毎日のように出てくる単語です.
いちいち頭の中で「False Positiveは,偽陽性で,本当は陰性だけど,間違えて陽性って予測したデータだな」とか考えてると会話についていけないので,パッと頭の中で一瞬でどのデータのことを言っているのかわかるようにできると◎です.まぁこの辺りは慣れですね!!今すぐにできる必要はないです.
今後紹介する精度指標の中ではこれらTP, TN, FP, FNを使って説明できるものがあるので,しっかり押させておきましょう!
Confusion Matrix (混同行列)
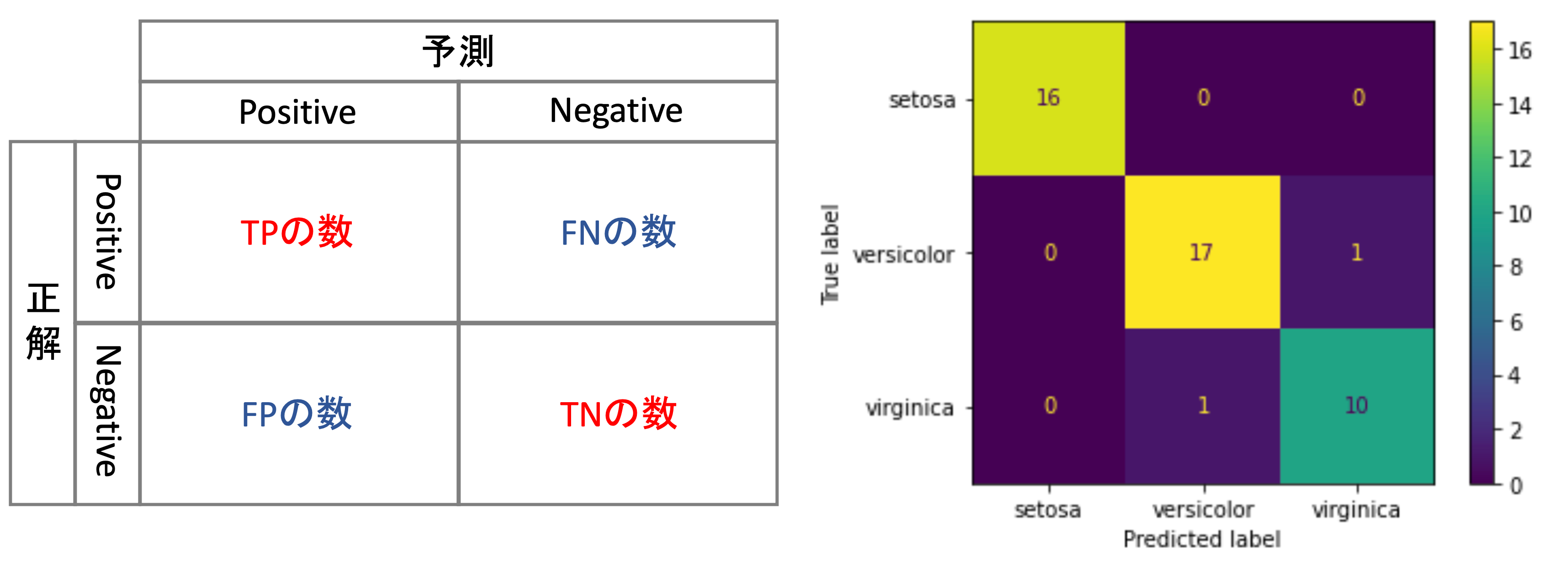
Confusion Matrix (混同行列)は,どのクラスがどれくらい間違えたのかを表で表したものです.一目でみてモデルがどう間違えているかの傾向が掴めるので非常に重宝します!
TP, TN, FP, FNの数をこんな感じで表にします.
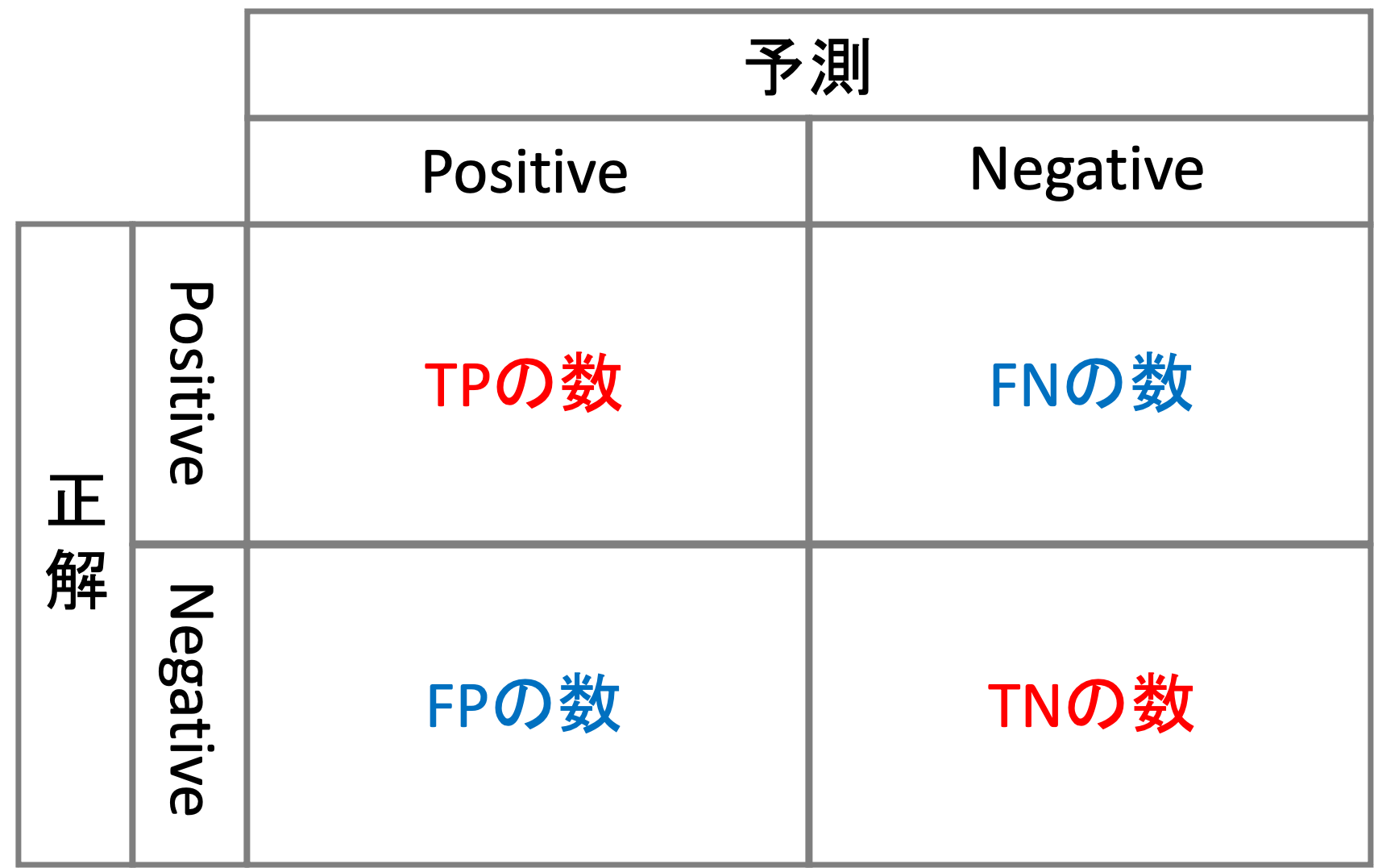
多クラスの場合はPositive、Negativeがそれぞれのクラスになって,\(k\times k\)の表になるわけです.(ただし\(k\)はクラス数.書籍によって軸が逆だったりするので注意してください.)
これをみることで,モデルがどのクラスに対してどれくらい正解していてどれくらい間違えているのかが分かります.非常に便利な図で,分類器を構築したらとりあえず結果をConfusion Matrixで確認すると言っても過言ではないくらいよく使われます.
PythonでConfusion Matrixを作る
scikit-learnには簡単にConfusion Matrixを作る関数が用意されています. sklearn.metrics.confusion_matrix を使います.
こちら回帰のmetrics同様, y_true と y_pred を渡します. y_pred は確率のリストではなく予測ラベルのリストを入れることに注意しましょう.
前回の多項ロジスティック回帰のモデルのテストデータにおける結果のConfusion Matrixを見てみましょう!(コードの学習部分については前回の記事を参考にしてください.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
y_pred = model.predict(X_test) confusion_matrix(y_test, y_pred)import seaborn as sns from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split # データロード df = sns.load_dataset('iris') # 学習データとテストデータ作成 X = df.loc[:, df.columns!='species'] y = df['species'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # モデル構築 model = LogisticRegression(penalty='none') model.fit(X_train, y_train) # 予測(ラベル) y_pred = model.predict(X_test) confusion_matrix(y_test, y_pred) |
|
1 2 3 |
array([[16, 0, 0], [ 0, 17, 1], [ 0, 1, 10]]) |
するとNumpy Arrayの形でConfusion Matrixを返してくれます.これが最もシンプルな形のConfusion Matrixです.
しかし,この形だとイマイチわかりにくいですよね,どっちの軸が正解/予測なのかもわからないですし,それぞれの行列がどのクラスを表しているのか不明です.
scikit-learnにはConfusion Matrixを綺麗に表示してくれる便利なクラスも用意されています. sklearn.metrics.ConfusionMatrixDisplay クラスを使います.
このクラスには,インスタンス生成時の引数に confusion_matrix 引数と display_labels 引数を渡します. confusion_matrix にはConfusion MatrixのNumpy Arrayを, display_labels には y_pred のラベルのリストを渡します(通常は model.classes_ でいいでしょう.)
|
1 2 3 4 5 |
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay cm = confusion_matrix(y_test, y_pred) disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=model.classes_) disp.plot() |
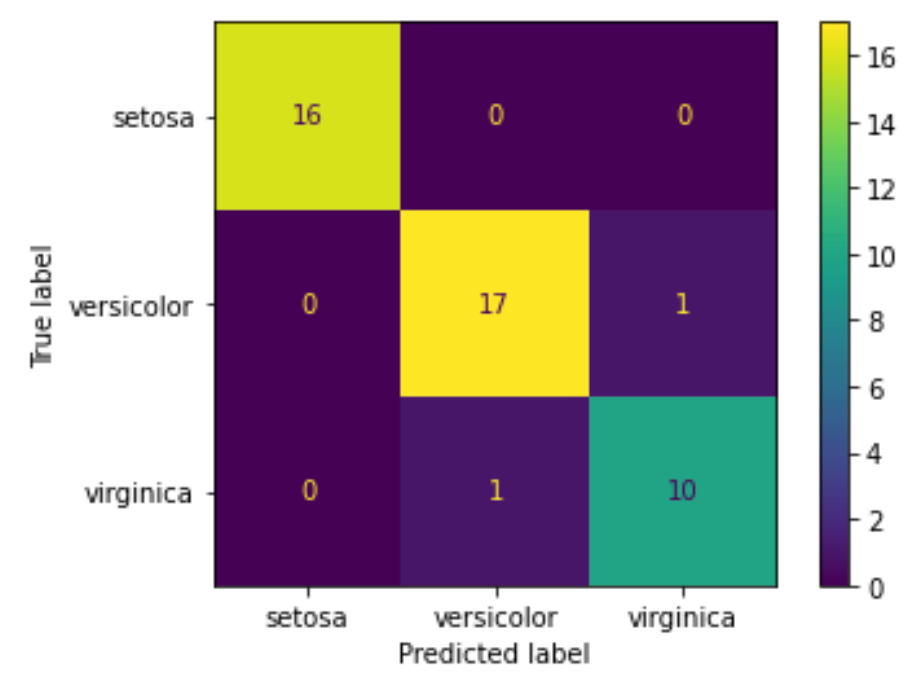
このように,heatmapの形で表示することで一目でどこの値が高いのか,低いのかが分かります.今回は2つのデータを間違えて分類していることが一発でわかりますね.versicolorをvirginicaと分類したデータと,virginicaをversicolorと分類したデータの2つです.setosaについては全てのデータで正しく分類できていることがわかります.
めちゃくちゃ便利なので是非使っていきましょう!
まとめ
今回の記事ではTP, TN, FP, FNとConfusion Matrix(混同行列)について解説をしました.
- 本当は陽性であるデータに対して正しく陽性と予測したケースを真陽性(True Positive: TP)
- 本当は陽性であるデータに対して間違えて陰性と予測したケースを偽陰性(False Negative: FN)
- 本当は陰性であるデータに対して正しく陰性と予測したケースを真陰性(True Negative: TN)
- 本当は陰性であるデータに対して間違えて陽性と予測したケースを偽陽性(False Positive: FP)
- “偽(False)”は”偽りの”という意味なので,その後の文字(陽/陰)を逆にしたものが本当のラベルだと考えると覚えやすい
- TP, TN, FP, FNを表にまとめたのがConfusion Matrix(混同行列)
- Confusion Matrix を使うことで,一目でモデルがどのクラスに対してどれくらい間違えているのかの傾向がわかる
次回はこの基礎知識をもとに,具体的な分類器の精度指標を紹介していきます!
次からが本番です.それでは!!
追記) 次回の記事書きました!
分類器の評価指標~Accuracy, Precision, Recall, Specificity~【機械学習入門20】