こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門18回(講座の目次はこちら)!いやー長かったなあ...Pandas編も今回と次回で最後です!
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
DataFrameのまだ説明していない他の関数たちをまとめて今回と次回で紹介します.今回紹介するのはその中でも特に頻出です!
扱う関数は以下の通りです
- .to_csv()
- .iterrows()
- .sort_values()
それぞれ解説していきますね.
目次
.to_csv()でDataFrameをcsv形式で保存
DataFrameでデータ処理をしたあとに,そのデータを保存したくなりますよね?データを保存して誰かに渡したり,ログをとったりしたくなります.
大抵のデータサイエンティストはcsv形式を好みます.ソフトに依存しないニュートラルな形式ですからね.
pd.read_csv() との対比で覚えましょう.read_csvはファイルを読み込み,to_csvはファイルを保存します.(もちろん様々データ形式をサポートしてます.試しにJupyterでdf.to_とタイプしてからTabキーを押してみてください.サポートしている関数がわかります.基本の使い方はどれも同じです.)タイタニックのデータに処理をして保存してみます.タイタニックのデータについては第11回を参照してください.
|
1 2 |
df = pd.read_csv('train.csv') df.head(3) |

今回は例としてAdultカラムを追加して,age>20ならTrue,age<=20ならFalseを格納します.いわゆる「フラグを立てる」処理です.よく出てきます.
前回の記事で紹介したapply()を使ってみましょう!
試しに自分でやってみてください!!
↓
↓
↓
↓
↓
こんな感じでできます.
|
1 2 |
df['Adult'] = df['Age'].apply(lambda x: x>20) df |
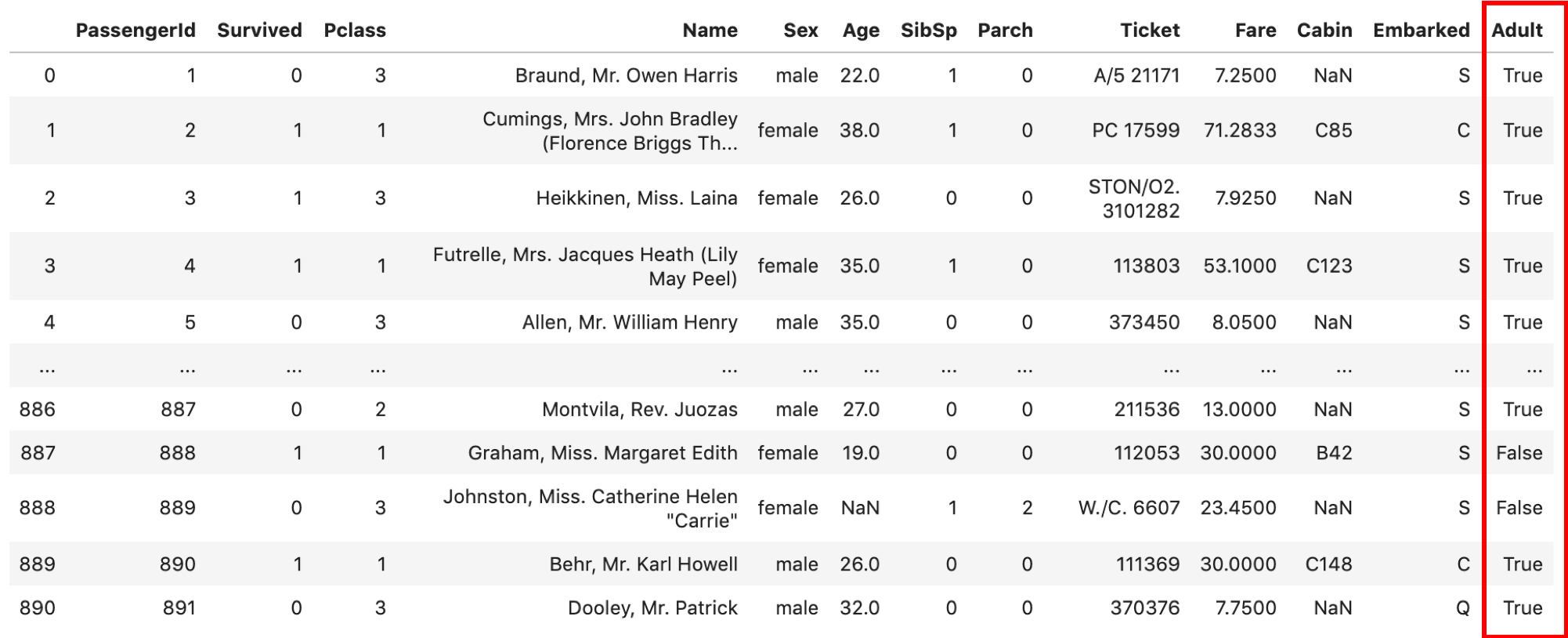
AgeがNaNのレコードにはFalseが格納されていることに注意してください.
さて,このレコードを .to_csv() を使って保存します.ファイル名を引数に渡します.
|
1 |
df.to_csv('train_w_adult.csv') |
するとJupyterの左側に新しいファイルができていると思います.

もし, to_csv() の引数にPathを渡せば指定したPathに保存されるのでやってみてください.
では,保存した’train_w_adult.csv’を pd.read_csv() で読み込んでみましょう!
|
1 2 |
df = pd.read_csv('train_w_adult.csv') df.head(3) |
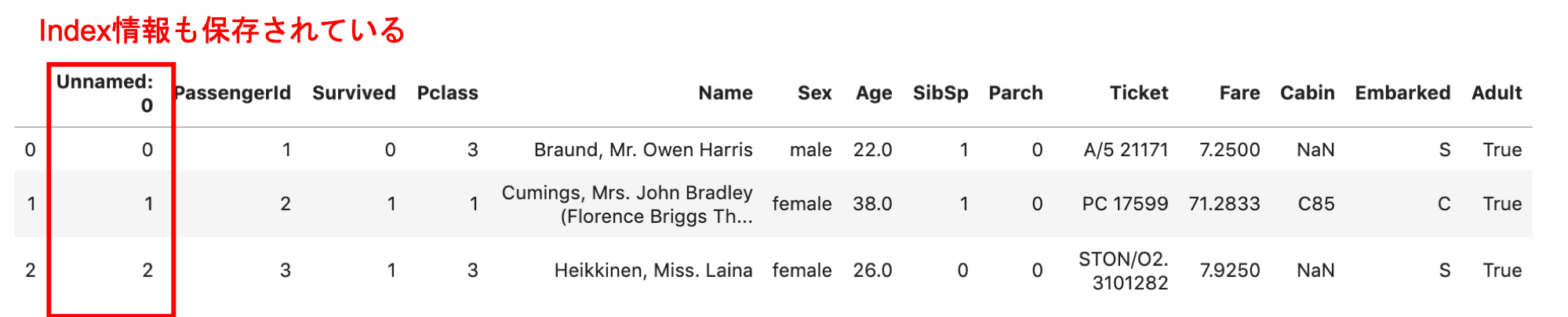 df.head(3) の結果をみると,前回保存した時のindex情報が’Unnamed:0’という謎のカラムに保存されています.
df.head(3) の結果をみると,前回保存した時のindex情報が’Unnamed:0’という謎のカラムに保存されています.
つまり, .to_csv() と pd.read_csv() を繰り返すとどんどんこの謎のカラムが増えていくわけです.
99%.indexを保存したい時はありません.だってただの連番ですもの.
.to_csv()にindex=Falseを指定するとindexを保存しないで済みます.私は基本常にindex=Falseを指定してcsv形式に保存しています.
|
1 2 3 |
df = pd.read_csv('train.csv') df['Adult'] = df['Age'].apply(lambda x: x>20) df.to_csv('train_w_adult.csv', index=False) |
保存先にすでに同じファイルがある場合,上書き保存されるので注意してください.
|
1 2 |
df = pd.read_csv('train_w_adult.csv') df.head(3) |

Indexが保存されていないのでスッキリします.
また,Booleanや数値は保存して再度読み込んでも型は変わりません.が,型によっては文字列で保存されてしまうことがあるので気をつけましょう.
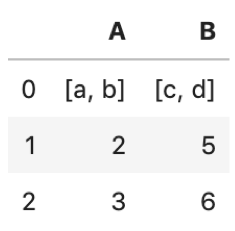
あまり使わないですが,例えばDataFrameの値がリストのケースをみてみます.↓
|
1 2 |
df = pd.DataFrame({'A': [['a', 'b'], 2, 3], 'B': [['c', 'd'], 5, 6]}) df |
|
1 2 |
# 格納されている値がリストであることを確認します. type(df['A'].iloc[0]) |
|
1 |
list |
ちゃんとリストで格納されています.
これをto_csv()してread_csv()すると・・・
|
1 2 3 4 5 |
# csvで保存 df.to_csv('temp.csv', index=False) # 保存したcsvを読み込み df = pd.read_csv('temp.csv') df |
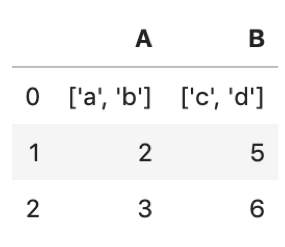
|
1 |
type(df['A'].iloc[0]) |
|
1 |
str |
listではなくstrになってますね.これはバグのもとなので気をつけてください.
.iterrows()でDataFrameをイテレーション
DataFrameをfor文でイテレーションするときに使います.覚えにくいですが,「rows」を「iteration」するのでiter + row + s. と覚えましょう.forで回せるものになるので複数系のsがあると考えましょう.
「イテレーション」というのは繰り返し処理を回すことを意味します.ループですね.例えばリストだったらfor i in list:でイテレーションできました(第4回参照)
DataFrameでは,リストのように直接for i in df:というのはできません. .iterrows() という関数を使って以下のように書きます.
いつも通りタイタニックのデータを使ってみましょう.
|
1 2 3 4 |
df = pd.read_csv('train.csv') for idx, row in df.iterrows(): if row['Age'] > 40 and row['Pclass'] == 3 and row['Sex'] == 'male' and row['Survived']==1: print('{} is very lucky guy...!'.format(row['Name'])) |
|
1 2 |
Dahl, Mr. Karl Edwart is very lucky guy...! Sundman, Mr. Johan Julian is very lucky guy...! |
.iterrows() でイテレーションを回すと,各ループで(idx, row)というタプルに値が入ります.idxはindex, rowは各行のSeriesです.
今回は40才以上でクラスが低い男性の生存者に対してvery luck…とprintする処理を入れました.
2人しかいないんですねw(当然NaNの評価はFalseになるのでデータが取れる範囲でですが)
前回の記事で紹介した .apply() では,各レコードの処理をした結果を別のカラムに保存するときに使い,今回の .iterows() では値を返すのではなく処理だけをしたいときに使うことが多いです.
例えばDataFrameにファイルパスが格納されていて,それを .iterrows() してファイルを移動させたり読み込んだりします.
何かと必要になる関数なので覚えておきましょう!
.sort_values()で特定のカラムでソート
第15回でも少し触れましたが,カラムを指定してソートします.そのままですね.SeriesではなくDataFrameの関数であることに注意してください.
ソート対象の値が複数あるのでvalue「s」と複数形になると覚えておきましょう.
|
1 2 |
# 年齢が若い順にソート df.sort_values('Age') |
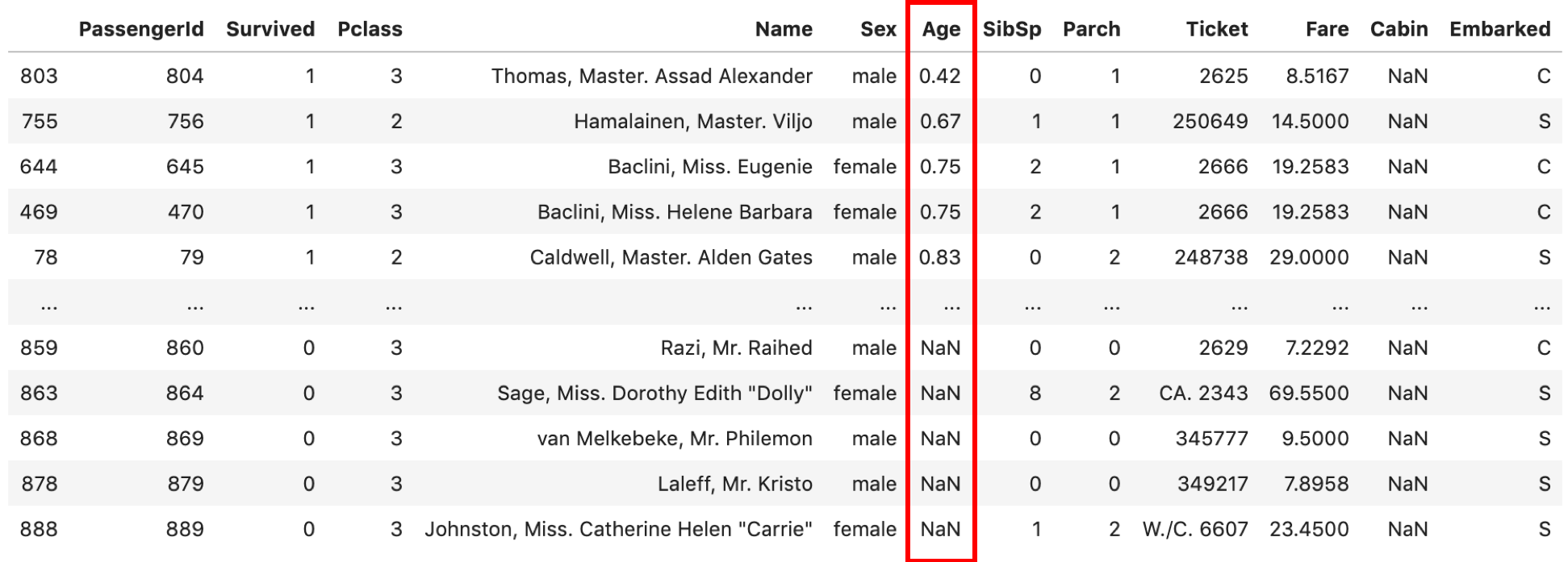
デフォルトは昇順ソート(小→大)です.降順ソート(大→小)にするには ascending=False を指定します.試してみてください.
なお, .sort_values() はソートされたDataFrameが返されます.他の関数で何度も出てきてますが,元のDataFrameを更新したい場合は inplace=True を指定するか再代入します.(第12回のdrop()を参照してください.)
まとめ
今回の記事での学習内容をまとめると以下です!
- df.to_csv('filepath', index=False) でDataFrameをcsvファイルで保存
- for idx, row in df.iterrows(): でDataFrameのrowをイテレーション
- pd.sort_values('カラム名') でソート
ファイルを保存できるようになると,もうほとんどのExcel処理をPythonでできるようになると思います.
ここまできたらあとは実践するだけ.是非日頃のExcel業務をPythonで効率化してみてください!!
それでは!!
追記:次回の記事書きました!Pandas編最後です.pivot_tableとxs関数です.
データサイエンスのためのPython入門19〜DataFrameのその他頻出関数(pivot_table, xs)を解説〜