データサイエンス入門の機械学習編第30回です.(講座全体の説明と目次はこちら)
ついに本講座も30回突破です...あと数回で終われると思います^^;
今回の記事ではアンサンブル学習というものを紹介します.
これは,複数のモデルを組み合わせて最終的な予測値を出すやり方で,一般的にかなり高い精度を期待することができます.
追記) 機械学習超入門本番編ではアンサンブルについてさらに詳しく解説をしています.さらに理解を深めたい方は是非受講ください:)
いまや機械学習をする際には必ずと言っていいほど使われる手法で,Kaggleなどのコンペの上位にくるようなモデルはほとんどこのアンサンブル学習を使っているといっても過言ではありません.
今回の記事ではアンサンブル学習の概要を,次回以降の記事では詳細と具体的なコード例を紹介していきます!
目次
アンサンブル学習とは?
アンサンブル(ensemble)というのは,音楽の用語で二人以上が同時に演奏することです.機械学習では,複数のモデルを学習させて多数決(や平均)で予測値を出すことを指します.
例えばランダムに60%の正解率である分類ができるモデルが3つあるとします.(ランダムなので,データによらず60%の確率で正解します)
このようなモデルを3つ使って多数決で予測すれば,正解率は65%弱に上がります.まさに三人寄れば文殊の知恵といったところでしょうか?
これがイメージし難い人は,100個のモデルを使うと考えてください.それぞれのモデルはランダムで60%の確率で正解するので,もし多数決を取れば,ほとんどのデータで正解ラベルを予測できることがイメージできると思います.

そう思うかもしれませんが,実はそういうわけではないんです.
アンサンブル学習に使うモデルは「弱学習器(weak learner)」である必要があります.
弱学習器というのはその名の通り,単独で使うと精度が低い学習器のことであり,「ランダムよりも多少はいい」くらいのイメージです.bias-varianceトレードオフでいうとhigh baiasでlow varianceであることが多いです.過学習していない単純なモデルといったところですね!
また,アンサンブルを行う場合はそれぞれのモデルの相関が少ない方がいいです.例えば完全に相関関係にあるモデル(=つまり同じモデル)を複数使っても意味がないですからね.
例えば先ほどの「ランダムに60%の正解率を持つモデル」はそれぞれのモデル同士に相関はありません,このようなケースではアンサンブル学習で大きな精度向上を期待できるわけです.まぁ実際にはここまでお互いに相関がないモデルを作り出すことは難しいんですが...(学習データセットは一つしかないですからね.同じデータセットでモデルを作ると相関が強くなるのは仕方ありません)
アンサンブルにはいくつか種類があります.今回の記事では有名なバギング・ブースティング・スタッキングという3つのやり方を簡単に紹介していきます.
また,次回以降の記事でそれぞれの手法を使った具体的なアルゴリズムを紹介します.
バギング
バギング(bagging)はbootstrap aggregatingの略です.
ブートストラップ(bootstrap)というのは,母集団からのサンプリング(標本抽出)手法の一種で,重複を許してランダムにデータを取ってきて標本にするやり方です.
例えば\(x_1, x_2, x_3, x_4, x_5\)という5つのデータから3つの標本を複数回ブートストラップ法でサンプリングする場合,以下のようなサンプル群が出来上がります
サンプル群1: \(x_1, x_2, x_2\)
サンプル群2: \(x_4, x_3, x_3\)
サンプル群3: \(x_2, x_5, x_1\)
サンプル群4: \(x_1, x_4, x_1\)
それぞれのサンプル群でデータが重複しているし,同一サンプル群の中でもデータが重複していることがわかります.
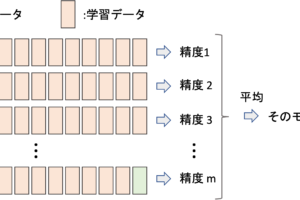
この手法によって全ての学習データから新たに学習データ群を複数作ってそれぞれの学習データ群でモデルを学習させるのがバギングです.(以下はバギングのイメージです)
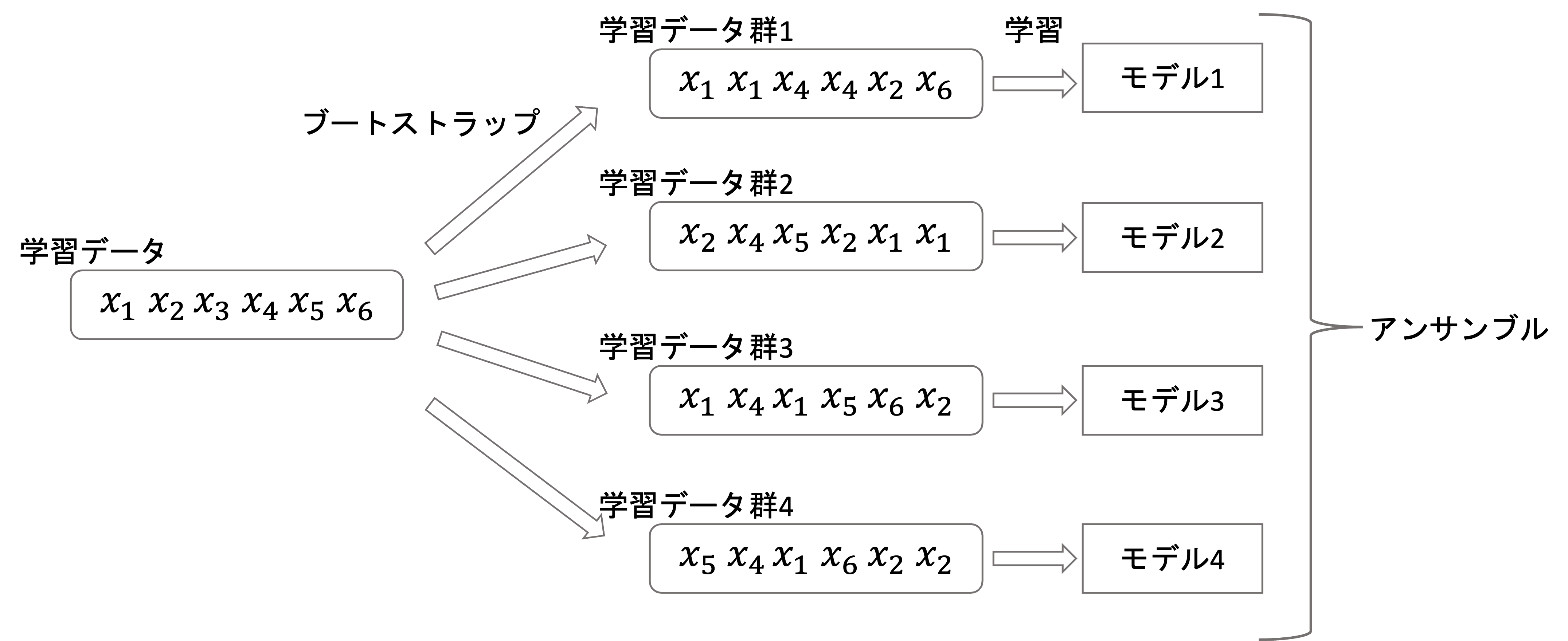
最終的な出力結果は,回帰なら平均値,分類なら多数決をとるのが一般的です.
バギングの特徴
バギングは,bias-varianceトレードオフでいうvarianceを下げる効果があり,過学習を抑えることができます.
これは,統計学講座第7回などで登場でした,標本分布の分散は,母集団の分散\(\sigma^2\)の\(\frac{1}{n}\)であることからもわかると思います.(下の図は標準偏差\(\sigma\)で表していることに注意)
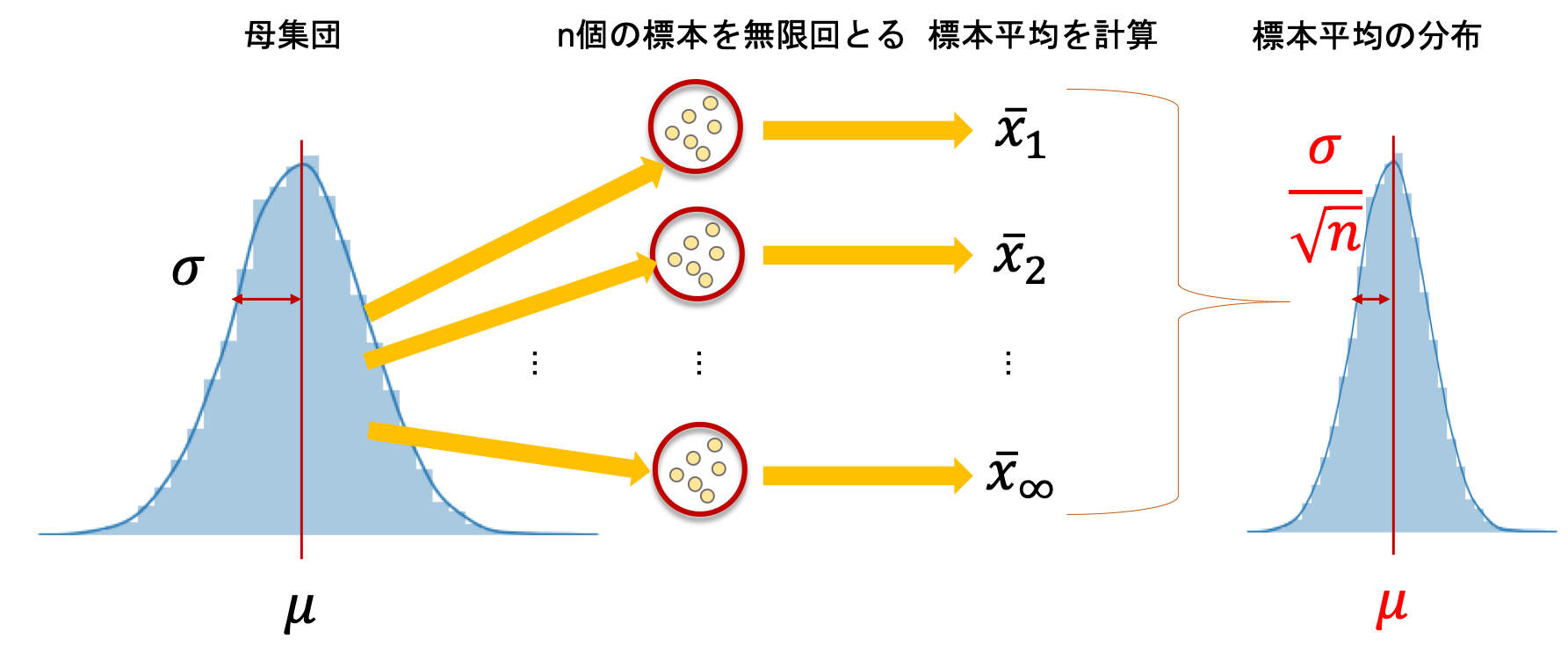
それぞれのモデルが,母集団から抽出された一つのデータだと考えてください.これらの各モデルの分散を\(\sigma^2\)とすると,平均をとることで最終的なモデルの分散は\(\sigma^2\)よりも下がるわけです.
バギングはvarianceを下げる効果があるため,varianceが高い弱学習器である決定木によく使われます.
前々回の記事で決定木は,データの分割が違ったり,少し学習データに違いがあると結果が変わってしまう高varianceなモデルのアルゴリズムであることを述べました.
ブートストラップ法で決定木を複数学習させ,その複数のモデルの予測結果の平均(や多数決)を最終的な予測とします.
(これを応用したのが,次回の記事で解説するランダムフォレストという超有名な決定木の応用アルゴリズムです)
ブースティング
ブースティング(boosting)は,バギングのように並列に複数のモデルを学習するのではなく,直列にモデルを学習していきます.
どういうことかというと,学習したモデルがうまく予測できなかった学習データに重みをつけてさらにモデルを学習するというのを繰り返していきます(下図はイメージです)
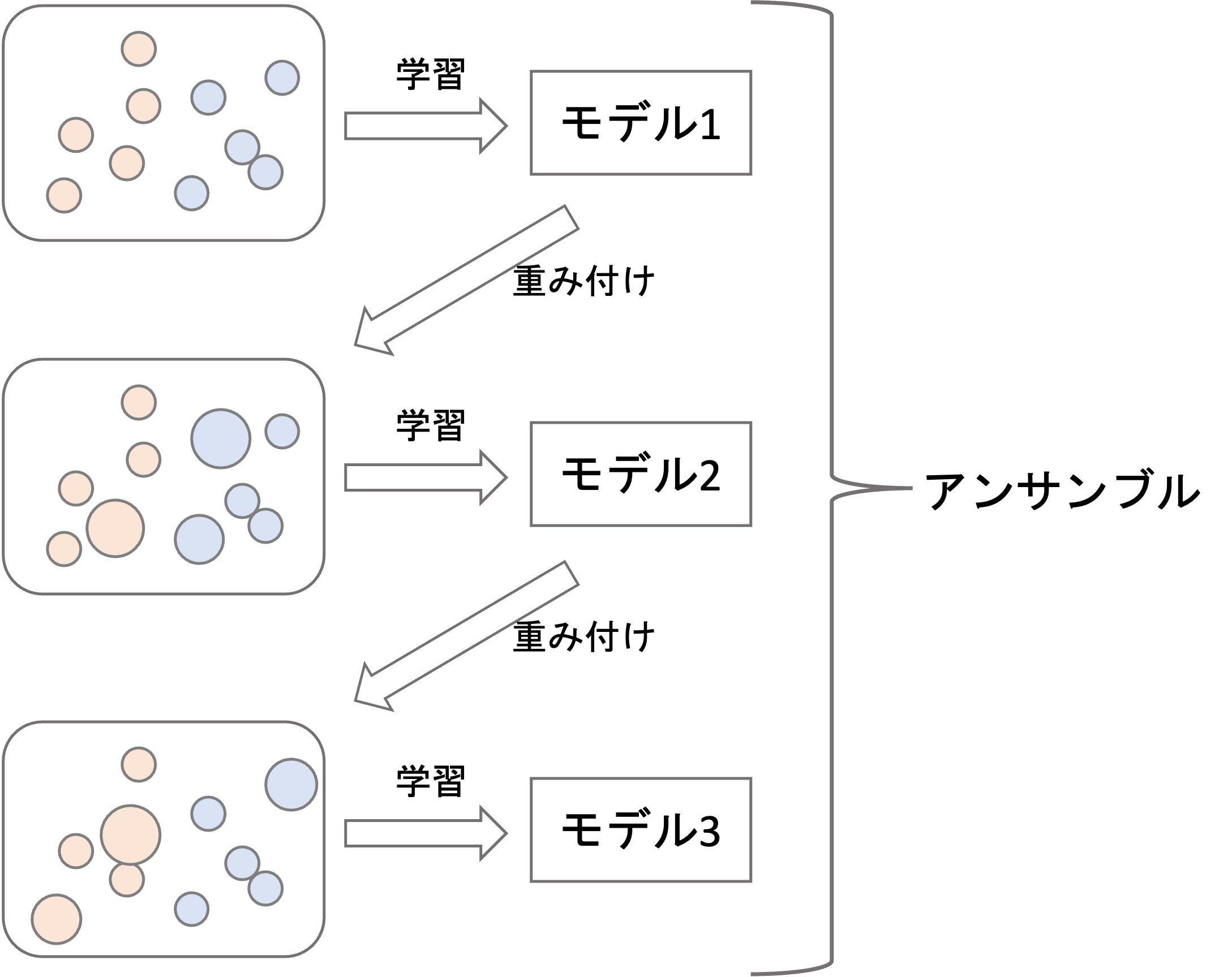
そうしてできた複数のモデルを組み合わせて最終的な予測をします(この際,単純に予測値を足すのではなく,0〜1の係数をかけて足し合わせるのが一般的です).まさにモデルを”ブースト”していくイメージですね!
バギングと違って,それぞれの学習時にブートストラップはせず,基本的には全ての学習データを使います.が,重みが付いているので,学習データをそのまま使うわけではありません.
ブースティングにも色々アルゴリズムがあり,どのように重みを変更していくのか,どのようにエラーを定義するのかは,アルゴリズムによって変わります.この辺りは今後の記事で詳しく解説していきます.
ブースティングの特徴
ブースティングは直列にモデルを処理していくので,学習時間が長くなることがあるので注意しましょう.ただ,ブースティングは一般的にvarianceとbiasの両方を下げることができるので,その分バギングよりも精度が高くなる傾向にあります.(必ずしもvarianceとbiasの両方が下がるとは限りませんが)
ブースティングは,データサイエンスのコンペ上位によく登場するモデルに使われているほど高精度であることが知られています.詳細なアルゴリズムや実装についてはまた今後の記事で紹介できたらと思います.
スタッキング
スタッキング(stacking)もよく使われるアンサンブル手法です.色々と応用例がありますが,ここでは最もシンプルな例を紹介します.
スタッキングは複数段階に分けて学習・予測をしていきます.今回はシンプルに2段階のもので解説をします.
まず,1段階目には普通に学習データを作ってモデルを複数構築します.(この時点でのモデルが既にバギングやブースティングを用いたアンサンブル学習のモデルであることもよくあります.)
そして2段階目では,それぞれのモデルの予測値(出力結果)を学習データとしてさらにモデルを作ります.
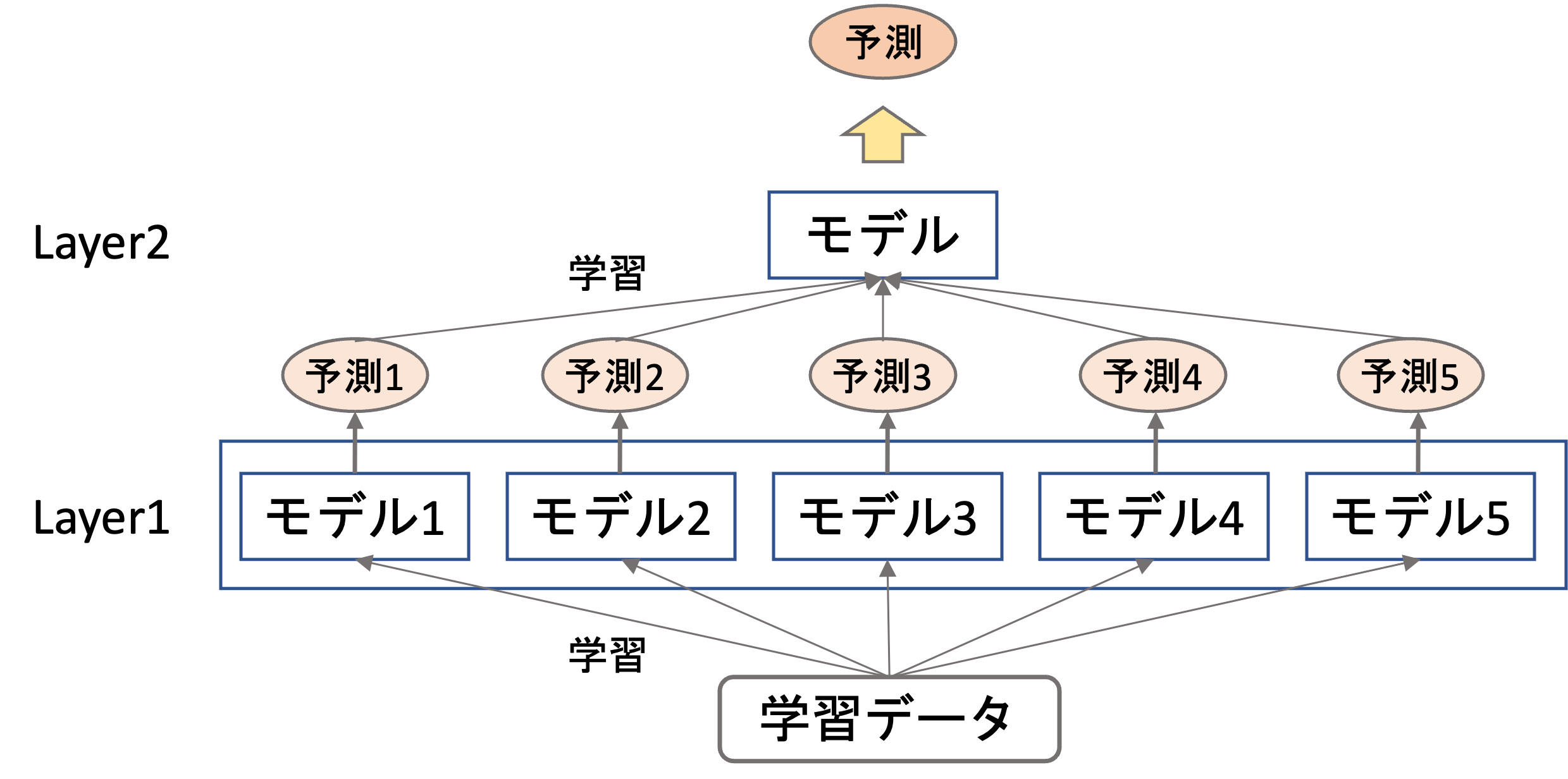
上図はイメージですが,例えば5つの別々のモデルを作って,それぞれのモデルの出力結果をさらに学習データ(特徴量)として最終的なモデルを作ります.
こうすることで,それぞれのモデルがhigh varianceだったりhigh biasだったりするのを最終的に調整し,非常に高い精度を出すことができます.
スタッキングでは名前通り,このようにモデルを積み上げて(stack)いきます
まとめ
今回の記事ではアンサンブル学習の概要について解説をしました.
- アンサンブル学習は,複数の互いに相関の弱い弱学習器を組み合わせて高い精度のモデルを構築するアルゴリズム
- バギングは,ブートストラップ法を使って抽出した複数のデータ群に対してそれぞれモデルを学習し組み合わせる手法
- バギングではvarianceを抑えることができるので,一般に高varianceである決定木に使うことが多い
- ブースティングは,モデルが予測を誤ったデータに重みづけをし繰り返し学習して最終的に複数のモデルに重みを付けて予測する手法
- ブースティングではvarianceとbiasの両方を下げることができ,バギングよりも高い精度を期待することができる
- スタッキングでは複数のモデルの予測値を新たな特徴量として別のモデルを学習させ予測する手法
最近のKaggleなどのコンペや,AI開発ではアンサンブル学習が当たり前になりつつあります.
一つのモデルのみを使って高い精度を出すのも重要ですが,コンピュータのリソースが許すのであれば,沢山のモデルを作ってアンサンブルして高い精度がでればいいよね?という風習があります・・・
ただ,これには注意が必要で,やりすぎるとやはり学習や推論に時間がかかります.
また,アンサンブル学習は複数のモデルの組み合わせなので,最終的な結果がブラックボックスになりがちです.
精度を求めるならアンサンブル学習は不可欠といってもいいくらい当たり前になってきましたが,データの解釈性を求める場合はアンサンブル学習ではなく単独モデルを使っていきましょう.単独モデルでデータを解釈して,アンサンブル学習で精度を極めるといった流れが最近は一般的です
次回以降の記事ではさらにこれらのアンサンブル学習を詳しくみていき,Pythonでの実装もやっていきたいと思います!
それでは!
追記) 次回の記事書きました!次回はバギング+決定木を応用したランダムフォレストというアルゴリズムを紹介します.非常に精度が高いことで知られている超有名アルゴリズムです.