








こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第33回です(講座の目次はこちら).
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
ついに,
ついに,,,,
ついに!!!2ヶ月に及んだ本講座も最終回です!
2ヶ月前,この講座の第一回を書いた時はまだTwitterのフォロワーが350人程度でした.
その時に出したツイートが瞬く間に拡散され,その次の2日間でフォロワーが+700人くらい増えましたw
今日からデータサイエンスのためのPython講座を連載します
Pythonの基本⇨統計学,機械学習を扱っていく予定です.この講座を一通りやればJr.データサイエンティストになれるレベルを目指します.まず第一回は基本環境のセットアップで,Docker+Jupyter Labを使いますhttps://t.co/unvAmuJZCw— かめ@米国データサイエンティスト/ブロガー (@usdatascientist) January 14, 2020
それから2ヶ月,地道に講座を書き進めたところ,今ではフォロワーが7300人を超えました.
いかにPython+データサイエンスが今世間でホットで,多くの方々が学習したい分野であることがわかりました.
これからも本ブログでは私の知識を共有していく予定ですのでお願いしますmm
この辺りはまた落ち着いたら別記事にまとめようと思います.
さて,今日は最終回ということですが,「データサイエンスのためのPython講座」ではデータサイエンスをPythonで行うための基本的なツールの使い方に焦点を当てています.一部データサイエンスだけでなくPythonの一般的な使い方も紹介してきました.(globやtqdmなど)
今回はもっとPythonの汎用的な話をします.
それは「Pythonのスクリプトファイルを作って,それをJupyterで呼び出して実行する」というものです.
今までの講座では全て,Jupyterのセルに直接関数を定義して実行していました.
しかしこれだと,その関数を使い回すのが難しいですよね?Jupyterはあくまでも実行環境であり,関数やクラスを定義する場所ではありません(クラスについては今回やりません.オブジェクト指向の書き方を講座で扱ってないのと,考え方は関数と同じなので割愛します.)
コードが長くなるとかなり汚くなりますし,あとで見た時にどの関数がなんなのかわからなくなります.ほかのJupyterファイルで使い回すこともできません.
簡単なコードをサクッと書くだけであれば今までのようにJupyterに書いていくだけでもいいんですが,少し複雑になるとたちまちカオスになるので,基本的には本記事で紹介するように,Pythonのスクリプトを別途作成し,関数やクラスをそこにまとめましょう.
それは,毎回関数を定義していたら大変だったのと,なるべくハンズオンでやって欲しかったので簡単にコードを書けるJupyterを使っていました.
目次
Pythonのスクリプトを作る
それでは,Pythonのスクリプトを作ってみましょう.
と言っても普通に.pyのファイルを作ればいいだけです.Jupyterの画面から作ってもいいですし,TerminalやGUIを使って普通にファイルを作ればOKです.
第一回の通りに環境構築をしている人は,コンテナからアクセスできるフォルダ(私の場合は~/Desktop/ds-python/)にファイルを作ってください.
今回はutil.pyというファイルを作ります.本ブログではSublimeというエディタの使用を推奨しているので本記事でもSublimeを使って作ります.
Sublimeについてはこちらの記事を参考にしてください.↓
sublコマンドでutil.pyを作成します.
|
1 2 |
$ cd ~/Desktop/ds_python/ $ subl util.py |
するとSublimeが開くと思います.とりあえずctrl+Sで保存しておきましょう.
Sublimeを使ってない人はお好きなエディタで同じようにファイルを作ればOKです.特にエディタも持っていない人はぜひこちらからSublimeをインストールして欲しいですが,JupyterLabからも作ることができます.こちらの記事で紹介したように,新しいNotebookファイルを作成するのと同じ手順で,作成時に「TextFile」を選択してファイル名をutil.pyにすればOKです.

util.pyに関数を定義
なんでもいいんですが,今回はシンプルに以下のような関数をutil.pyに定義してみようと思います.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np def crop_img(im, crop_size=60): ''' 画像の周りをcrop_sizeだけ切り落とします Params ---------------- im: image (NumPy Array) crop_size: crop size (int) Returns ---------------- im: croped image (NumPy Array) ''' im = im[crop_size:-crop_size, crop_size:-crop_size, :] return im |
(NumPyのIndexingについては第7回に詳しく書いています.また,関数の書き方については第5回を参考にしてください.)
関数を定義したら,なるべくリファレンス用にコメントを書きましょう(トリプルクオテーション ''' で囲む,)
今回のように独立したPythonスクリプトを作成する場合は,そのスクリプトには関数やクラスを定義するだけにしましょう.(場合によっては変数を定義することもあります)
Jupyterからインポートする
今までNumPyをインポートしていたのと同じようにインポートすればOKです.今回はカレントディレクトリに作っているので
|
1 |
import util |
のようにインポートできます.
もしこれを別のフォルダを作ってその中にutilを入れた場合は
|
1 |
from フォルダ名 import util |
のようにします.
多くの場合,Pythonスクリプトは別フォルダにまとめておくことになると思うので, from フォルダ名 import ファイル名 が一般的です.
|
1 |
util |
Jupyterでutilを実行すると
|
1 |
<module 'util' from '/work/util.py'> |
が表示され,ちゃんとインポートされていることがわかります.
/work/util.pyはコンテナ内でのパスです.第一回で-vオプションに -v ~/Desktop/ds_python:/work を指定したことで,ホストの~/Desktop/ds_pythonがコンテナの/workフォルダにマウントされているのでコンテナ内では/work/util.pyになります.(ここで第一回の伏線回収!w)
Jupyterから使ってみる
こちらも今までのモジュール同様に使えばOKです.cv2とmatplotlibを用いて,今回定義した util.crop_img() 関数を使ってみましょう.
cv2については第28回を,matplotlibについては第20回を参考にしてください.データは第28回で使ったlennaを使いました.なんでもいいですが.
|
1 2 3 4 5 6 |
import matplotlib.pyplot as plt import cv2 %matplotlib inline im = cv2.imread('lenna.png') plt.imshow(im) |
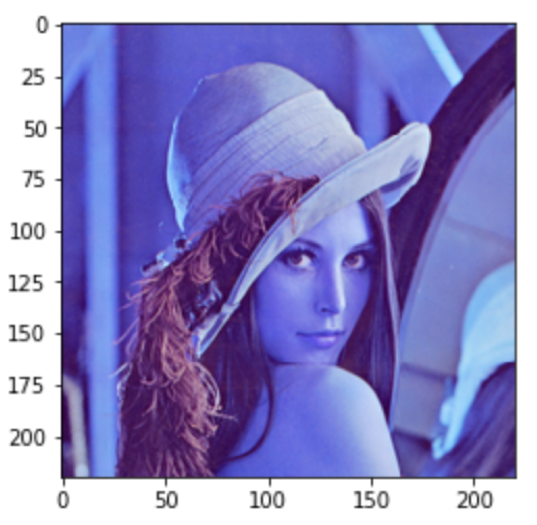
第28回で説明した通りOpenCVはBGRで取り込んでおり,matplotlibではそれをRGBとして表示しているので,RとBが逆転して表示されています.(今回は関係ないですが)
それでは, uti.crop_img() でクロップした画像を表示してみましょう.
|
1 2 |
crop_im = util.crop_img(im) plt.imshow(crop_im) |
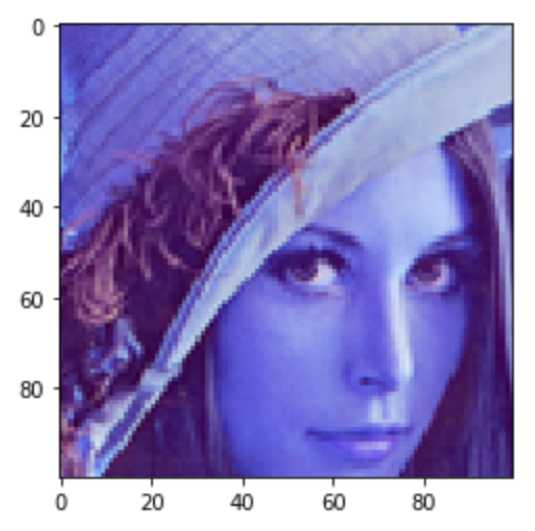
周りの部分が60pixel削られて,真ん中の顔部分だけが残ってるのがわかると思います.
Shift+Tabで,リファレンスを確認することも可能です.ここで,先ほどのコメントが役に立ちます.(この辺りの使い方は第2回で解説してます.)
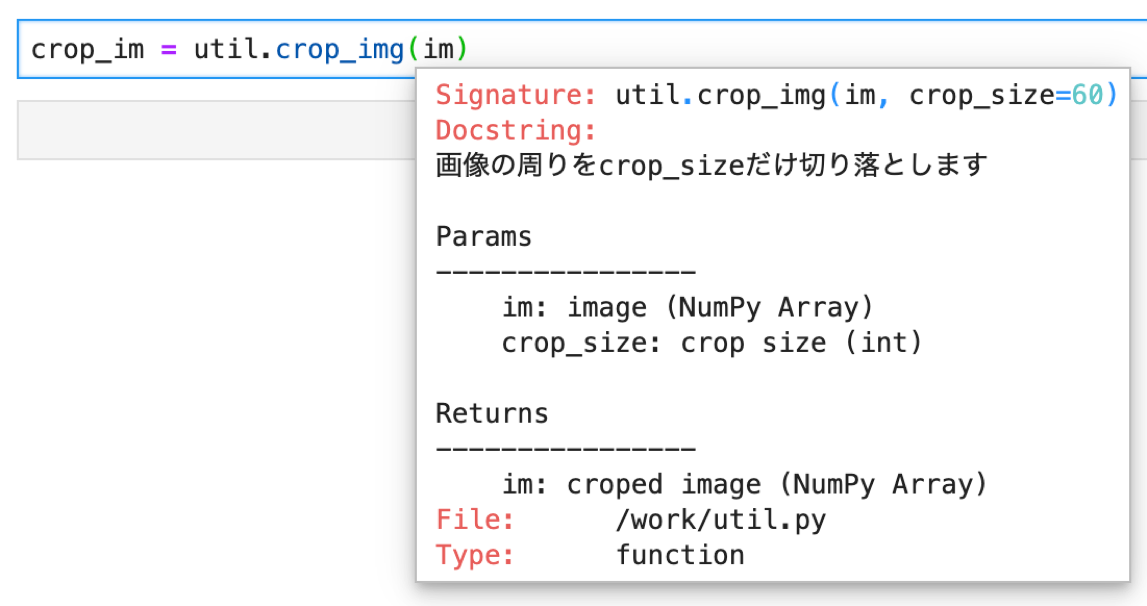
実際の開発では画像がcrop_sizeより小さい場合のエラーハンドリングが必要です.今回はただのサンプルコードなのでそこまではやりません.
(重要)スクリプトの更新を随時Jupyterで読み込む
util.pyは何度も更新することになると思います.しかし,Jupyterでは一度読み込んだutilモジュールは,その後util.pyが更新されてもutilモジュールに反映されません.(実際にcrop_sizeのデフォルト値を変えて再度コードを実行してみてください.Jupyterでは変わらないはずです.)
そこで,関数を呼ぶ度に最新のモジュールを反映するおまじない(magic command)を覚えておきましょう.第20回ででてきた %matplotlib inline もmagic commandです.
この二行をJupyterの一番上のセルの一番上の行に書いておきましょう.
|
1 2 3 |
%load_ext autoreload %autoreload 2 |
そうすることで,常に新しいモジュールを実行してくれます.
コードを更新しているにも関わらず,Jupyter側で反映されなかったらバグに気づかなかったりして危険です.
必ずこのおまじないを置いておきましょう.kernelをリスタートして再度crop_img関数を実行してみてください.変更が反映されているはずです.
「おまじない」のあとにインポートしたモジュールのみが反映されます.基本すべてのモジュールに適用したいので,一番上に書くようにしましょう.
また,「おまじない」の原理,しくみについては重要ではないので割愛します.毎回コピペでいいと思います.興味がある人は各自ググってください.
本記事の内容はこれで以上です.このように関数やクラスを別ファイルにすることで,Notebookが綺麗になりますし,Notebookを横断して使えるようになりコードの汎用性が高まります.
私は基本,よほどその場でしか使わない関数でない限りJupyterには定義せずに都度スクリプトファイルを作ってそこに定義しています.
そうすることで,コードを簡単に使いまわせるし,Notebookが汚くならないし,管理や修正が楽にになりバグも減りますし作業効率も格段に上がります.
コードの管理がうまくできていないデータサイエンティストの方は多いです.特に開発経験が少なく,Jupyterからコーディングを始めた人に多い印象です.是非これからはPythonファイルを作って,そこに関数やクラスを定義してJupyterから呼び出すようにしてください!
まとめ
今回はPythonファイルを作って,そこに関数を定義してJupyterから呼び出す方法について紹介しました.
なにも難しいことはなく
1.ファイルを作って
2.from フォルダ名 import ファイル名でインポート
3.普通に使う
でOKです.以下のmagic commandにより,常に最新のスクリプトを読み込むようにしましょう.
|
1 2 3 |
%load_ext autoreload %autoreload |
Pythonでデータを解析しようとすると,多くのコードを書くことになると思います.
できるだけ関数やクラスを作って,またそれらを別ファイルにすることで管理しやすくしましょう.
今回でデータサイエンスのためのPython入門講座は終了です.この講座で学んだ内容は,世界の最先端で働くほとんどのデータサイエンティストが当たり前のように日々使っている内容だと思います.
本講座を執筆するにあたって,私はあまり調べたりすることはなかったです.業務で使っている内容をただ書いていただけです.
なので,本当に基礎だし当たり前の内容だと言えます.
慣れてスラスラ書けるようになると,自分のやりたいことがパッとコードでかけたり,欲しいデータやグラフをすぐ作れたりします.するとデータサイエンスが一層楽しくなるし,できることが広がります.
今後,本ブログでは本講座の内容を活かして統計学や機械学習の講座も書いていこうと思います.
特にPythonでは,簡単に機械学習を扱うことができます.そのためのモジュールは,本講座ではなく機械学習講座で理論と合わせて説明する予定です.
あーはやくデータサイエンスの理論に入りたい!!
というわけでこれからもよろしくお願いします!&今後の更新をお楽しみに!
最後まで読んでいただいてありがとうございます.もし本ブログが役に立ったら友人や同僚に紹介していただけると嬉しいです.
また,最近は全然リプも返せてませんが,Twitterのフォロー(@usdatascientist)&ブログに関するTweetやRTをお願いします.「役に立った」「こんなことができるようになった」など,コメント・ツイートいただけると嬉しいです.今後の励みになります.
それでは!








