こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
今日から久々にブログ連載を再開したいと思います!題して「Pythonで学ぶデータサイエンス:統計編」です!!
Pythonを使って,統計学の基礎を学習していきたいと思います.本講座ではPythonを使うので,「Pythonでちゃんと学びたい!!」という人は,こちらのブログ講座でPythonの基本とデータサイエンスに必要なPythonを学習してください.
もっと効率よく学習したい人は動画講座で学習することをお勧めします.全23時間超えの大ボリュームです.非常に高い評価をいただいているので,自信をもってお勧めできます.
また,コミュニティ“DataScienceHub”では,Coding Challengeという毎週プログラミングの課題を出しています.Pythonについてはコードレビュー もしてますし,他の人のコードをみれたりするので,「もっとPythonを勉強したい」という人は是非参加してみてください.
(追記)
全16時間を超える統計学動画講座を公開しました!あらゆるUdemyにある統計学講座の中でもトップ評価(☆4.8)をいただいています.是非こちらで受講ください!
目次
講座の範囲とレベル
本講座は統計学の基本的な内容を勉強していきます.もう本当に基本中の基本.統計学を勉強したことない!!っていう人でも進められるようにしているので,小難しい本を読む前に是非本講座に取り組んで欲しいです.
講座の範囲は,統計的記述から始まり,推定と検定を軽く扱います.その後機械学習講座に繋げていければいいかなと.
なので,マニアックな検定には触れません.あくまでも「最初の一歩」を踏み出すための講座だと思ってください.
ただ,統計学の土台にある考え方はしっかりと学べるようにするので,本講座を一通り学習すれば他の統計本を読み進められるようになると思います.機械学習を勉強するのにも必要な知識になってくるので,是非今回の講座で基礎を固めておきましょう!
なお,ベイズ統計はまた別の講座作ります.
本講座ではPythonを使っていきます
本講座ではPythonを使って学習していきますが,Pythonが分からなくてもある程度進められるように設計するので,Pythonがわからない!って人はPythonのコードの部分は飛ばして進めてください.
ただ,今後データサイエンティストを目指すのであれば絶対にPythonはできたほうがいいと思うので.是非本記事の前半に書いた講座を受けてPythonを習得しましょう!
(追記)Python自体触ったことがない!という人や,Pythonの勉強をしたいという人は,是非僕のUdemy講座を受講ください!こちらも☆4.8という超高評価(Udemyでダントツトップです)でベストセラーになっています.(↓の記事にクーポンを載せているので使ってくださいね!)
本講座で扱うPythonのライブラリは,本ブログの「データサイエンスのためのPython講座」で扱ったライブラリ(主にはNumPy, Pandas, matplotlib, seaborn)に加え,新しくSciPyのstatsとscikit-learnというライブラリを扱います.

SciPyはScientificな(科学的な)Pythonのオープソース・ライブラリです.’サイパイ’と呼びます.
NumPyを基盤にして作られていて,統計や最適化問題,積分や線形代数など,科学や工学で使用する際に非常に役立つモジュールを揃えています.
本講座では,特に統計に特化したstatsモジュールを使っていきます.(統計学入門ですからね!)
scikit-learn(サイキットラーン)は,Pythonの機械学習用のオープンソース・ライブラリです.主要な機械学習のアルゴリズムはだいたい網羅してます.略してsklearn(エスケイラーン)と言ったりもします.scikitは,SciPy Toolkitから来てる通り,SciPyの拡張的なライブラリですが,ユーザ目線ではSciPyとは独立した別のライブラリと思っておいていいと思います.
scikit-learnは機械学習用のライブラリですが,統計講座でも少し使います.
SciPyもscikit-learnも,Anacondaに入っています.今回もJupyterLabを使ってハンズオン的に進めたい方はこちらの記事や,こちらの動画講座で環境構築をしてください.
なお,本講座では実際にコードを書いていきますが,本講座のコードは必ずしも”最適な”コーディングをしていないことに留意してください.(“Python”講座ではないので)
場合によっては,アルゴリズムを理解するため,ライブラリの関数を使わずにあえてスクラッチからコードを実装しています.また,PandasやNumpy,SciPyを使って同じことができたりもしますが,全てを紹介するのは無理なのでご了承ください.
そもそも統計学とは?
そもそも統計学ってなんでしょう?
統計学というのは,統計データの分析の考え方やその方法を扱う学問です.
「統計データ」というのは,なにか観察したいものがあったときに,それについて得られた測定値や観察値の集合です.例えば,日本のデータサイエンティスト職の年収を知りたかったら,実際にまずは何名かのデータサイエンティストの年収を調べますよね?その値の集合が「統計データ」です.
本講座では”統計”を大きく分けて2つに分けます.
- 統計的記述(記述統計)(descriptive statistics)
- 統計的推論(推測統計)(inferential statistics)
んー,なんか小難しい単語が出てきましたが,なにも難しい話じゃないんです.
データを散布図などを使って可視化することの重要性はPython講座でもやりました.(こちら)
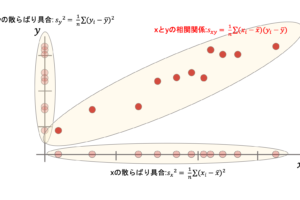
でも,実際に散布図だけだとなんとなくデータの傾向はわかるけど,それだけだと限界があるので何か具体的な数字を使って「このデータは〇〇だ」って言いたいですよね?
例えば日本で働くデータサイエンティストの友人数名の年収をみた時に「なんとなく普通の人より高そう」じゃ困る.どれくらい高いの?というのに対してわかりやすい指標が必要です.
例えば平均値をみるのもいいですし,中央値も使えるかもしれない.
こういった指標を使えば,少なくとも観察したデータについては分析できますよね?このように,「実際に観察した統計データに対して,そのデータ自体の範囲内での分析を行うこと」を統計的記述や記述統計と言います.
一方,実際に観察した統計データの背後にあるそのデータを生み出したデータ(例えば日本で働くデータサイエンティストの全員の年収)の分析を行うことを統計的推論や推測統計と言います.
え,そんなことできるの?って思うかもしれませんが,それを頑張って(?)やるのが統計学.
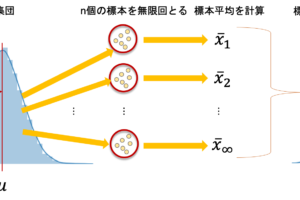
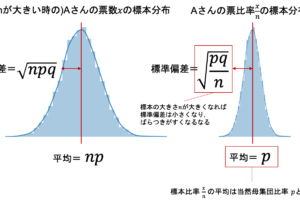
実際に興味があるその背後のデータを母集団(population)と言って,そこから観察に使う一部のデータを標本(sample)といいます.推論統計は「標本データを使って,母集団の特性を推論する」ものです.
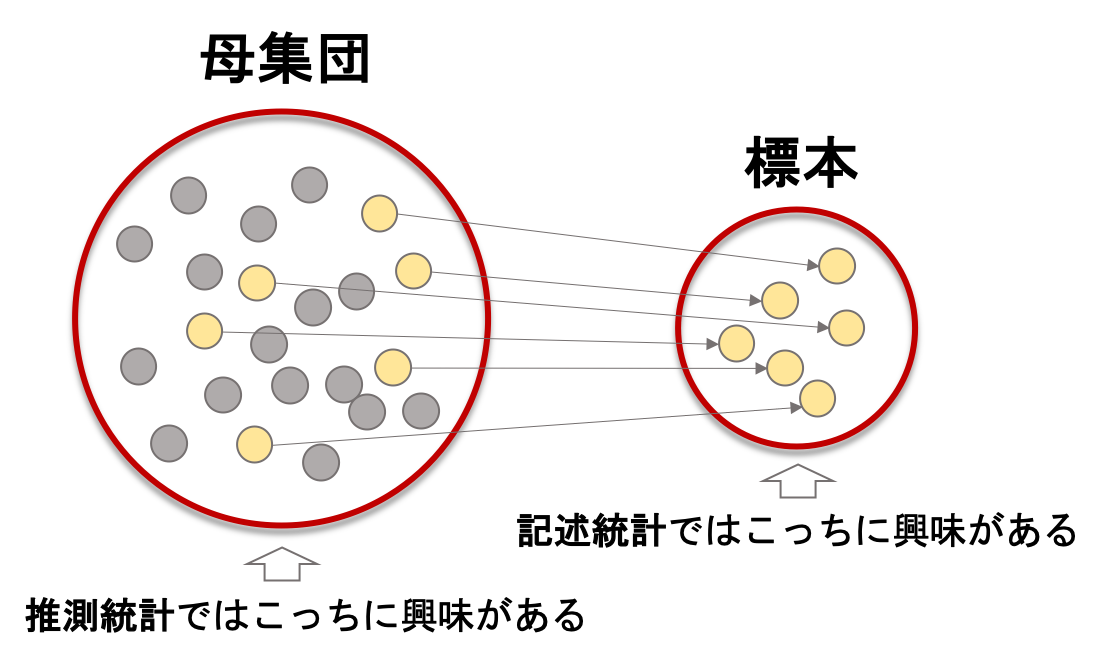
そして推測統計には推定と検定という2つのタイプがあります.
推定というのは,母集団の割合とか平均を標本から推論すること
(例えば「日本のデータサイエンティストの平均年収はきっと○○だ!」とか,「日本のデータサイエンティストの男女比はきっと○:○だ!」とかです)
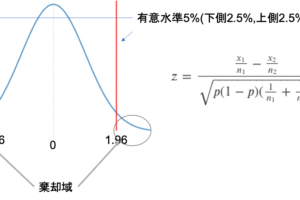
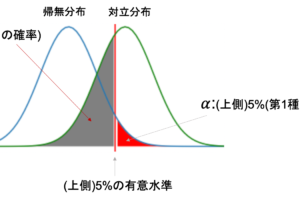
検定というのは,何かの”問い”に対して標本の調査結果を元にYes/Noで答えを与えるものです.(例えば「日本のデータサイエンティストの年収は去年より上がったか?」に対してYes/Noで答える)
一般的に「統計学」といったらほとんどの人が推測統計をイメージするかな?実際に推測統計が統計学のメインです.が,推定や検定をするのに記述統計の知識が欠かせないので,本講座では記述統計を勉強してから推測統計に入っていきます.
ちょっとまだよくわからない?今はまだわからなくてよろしい!別に単語もおぼえなくてOK !徐々に慣れていきましょう!
それでは,次回から記述統計の一発目の「代表値」について解説していきます!早速Pythonも書いていくよ!
それでは!
(追記)次の記事書きました