こんにちは,米国データサイエンティストのかめ(@usdatascientist)です.
データサイエンスのためのPython入門第23回です(講座の目次はこちら).matplotlibを使って,色々なグラフを描画したいと思います.
(「データサイエンスのためのPython講座」動画版がでました!詳細はこちら)
今回でmatplotlibは最後になりますが,次回から紹介するseabornというライブラリに繋がる内容なので今回の内容もしっかり押さえておくと◎です.
さて,本記事では以下の内容を扱っていきます.
- グラフの装飾
- 散布図(scatter plot)
- ヒストグラム(histogram)
- 箱ひげ図(box plot)
今まで扱ってきたグラフはどれもデータとデータを線で結んだものでしたが,「グラフ」と一言で言っても実はいろんな種類があると思います.
私が実際に業務でよく使うグラフは散布図,ヒストグラム,箱ひげ図です.この3つを覚えておけば問題ないでしょう.あとは必要になった時に色々調べればOKです.
まずは,グラフの装飾についても触れていきます.色の変更とか,マーカーを変えたりできます.
目次
グラフの装飾の仕方
第20回で使った指数関数のグラフを例に,様々な装飾をしてみようと思います.また,装飾については第20回でも少し触れました.今回はもう少し詳しく解説します.
自分はあまり装飾しないですが,論文書く人やお客様への報告なんかでこだわりたい時が出てくると思います.どれも直感的にわかるものばかりなので,使いやすいと思います.覚えておきましょう.
|
1 2 3 4 5 6 7 |
import numpy as np import matplotlib.pyplot as plt %matplotlib inline x = np.linspace(-3, 3, 10) y = np.exp(x) plt.plot(x, y) |
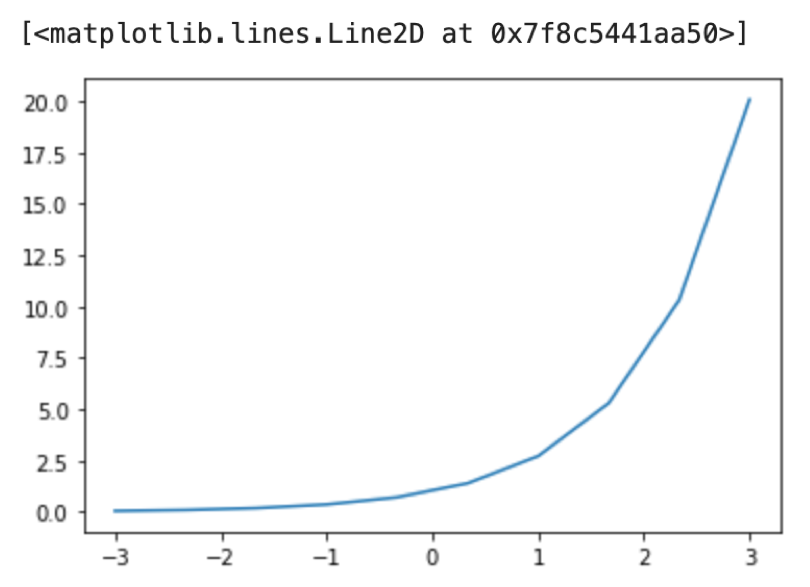
まずこれがデフォルトですね.
どんな装飾パラメータがあるかというと...Shift+Tabでリファレンスを確認してみてください.(リファレンスの確認の仕方は第2回で!)
...めっちゃあります.
スペースとるんでここには貼り付けませんっ
今回は特に使う以下のパラメータを紹介します.これ以外は使わないと思う.
- color : グラフの線の色 ⇨ ’red’や’green’のように色の名前を指定します.’r’や’g’のように頭文字でもOKです.
- lw (line width) : 線の太さ ⇨ 数字です.好みの大きさにしてください
- ls (line style) : 線の種類 ⇨ ’-‘や’–‘のように指定します.よく使うのはこの二つのどちらかです.
- marker : マーカーの種類 ⇨ ’o’や’x’ように指定します.マーカーの形が変わります.
- markersize : マーカーの大きさ ⇨ 数字です.好みの大きさにしてください
- markerfacecolor : マーカーの色 ⇨ ’red’や’green’のように色の名前を指定します.’r’や’g’のように頭文字でもOKです.
- markeredgecolor : マーカーの枠に色 ⇨ ’red’や’green’のように色の名前を指定します.’r’や’g’のように頭文字でもOKです.
- markeredgewidth : マーカーの枠の太さ ⇨ 数字です.好みの大きさにしてください
- alpha : plotの透明度 ⇨ 0から1の間をfloatで指定します.0に近い程透明度が上がります.
要は,「線」に対しての装飾と「マーカー」の装飾です.
一つ一つ説明すると大変なので,一気に説明します.どんな値を取れるかはリファレンスを見るとだいたいわかります.
|
1 |
plt.plot(x, y, color='red', lw=5, ls='--', marker='o', markersize=15, markerfacecolor='yellow', markeredgecolor='blue', markeredgewidth=4, alpha=0.5) |
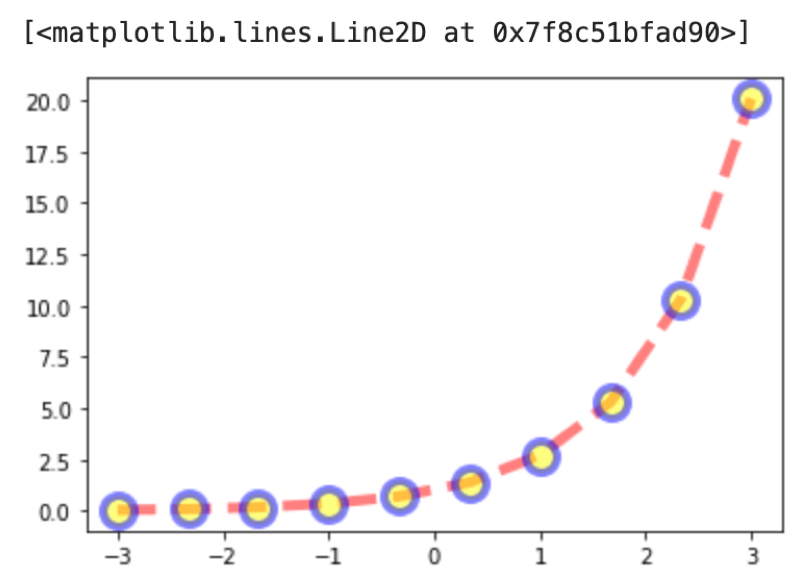
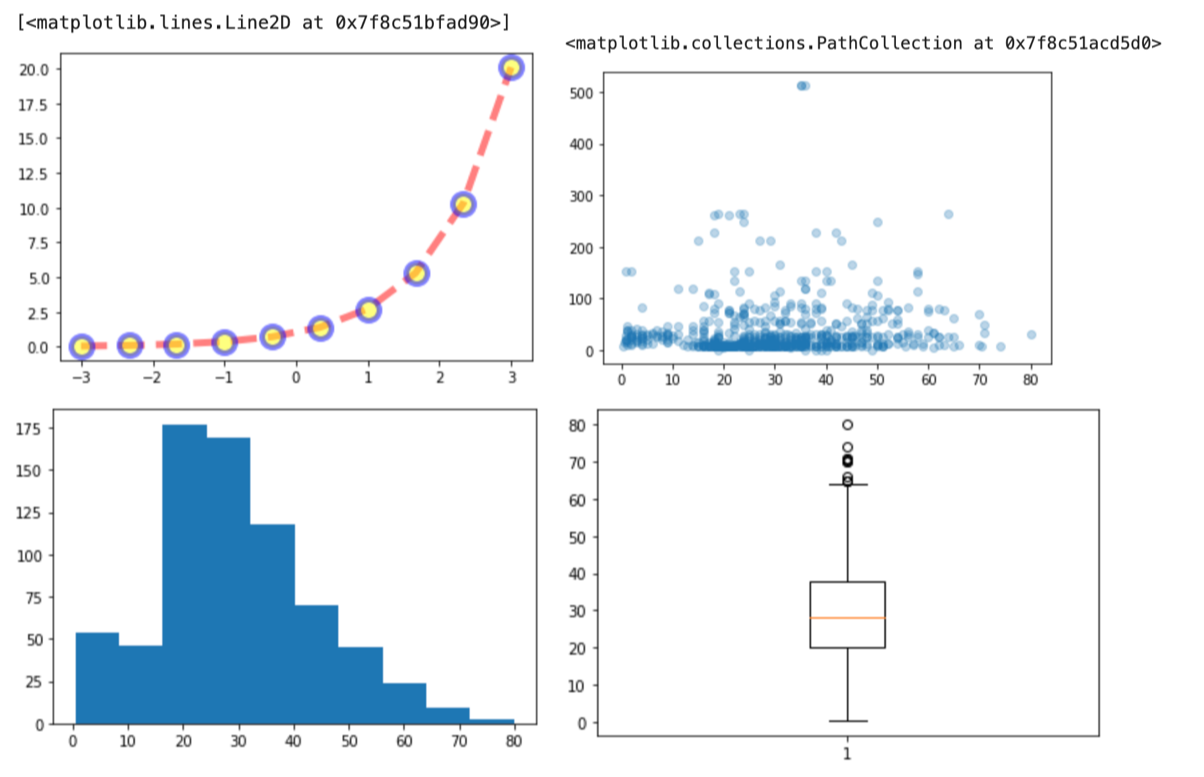
こんな感じです.特に説明は不要かと思います.それぞれのパラメータを色々な値で試してみてください!
散布図:plt.scatter()
今までのグラフは,それぞれの点を結んで軌跡になるようなグラフでした.数式をグラフにしていたので当然です.
しかし,実業務で扱うデータはある数式に沿ったデータではなくある程度のランダム性を備えたデータであることがほとんどだと思います.
なので,実際にみなさんがデータサイエンティストとしてplotする図って,今まで扱っていた「数式のグラフ」の形ではなく,これから説明する散布図,ヒストグラム,箱ひげ図などのグラフであることが多いと思います.
特にその中でも散布図は一番頻度が高いです.
散布図というのは,データを点でプロットしたものです.今までのように点と点を線で結ぶことはしません.データの全体的なばらつきや傾向をみるのに使います.
タイタニックのデータを例に散布図を作ってみましょう.散布図を作るには plot.scatter() 関数を使います.(タイタニックデータについては第11回を参照ください.)
|
1 2 3 |
import pandas as pd df = pd.read_csv('train.csv') plt.scatter(df['Age'], df['Fare'], alpha=0.3) |
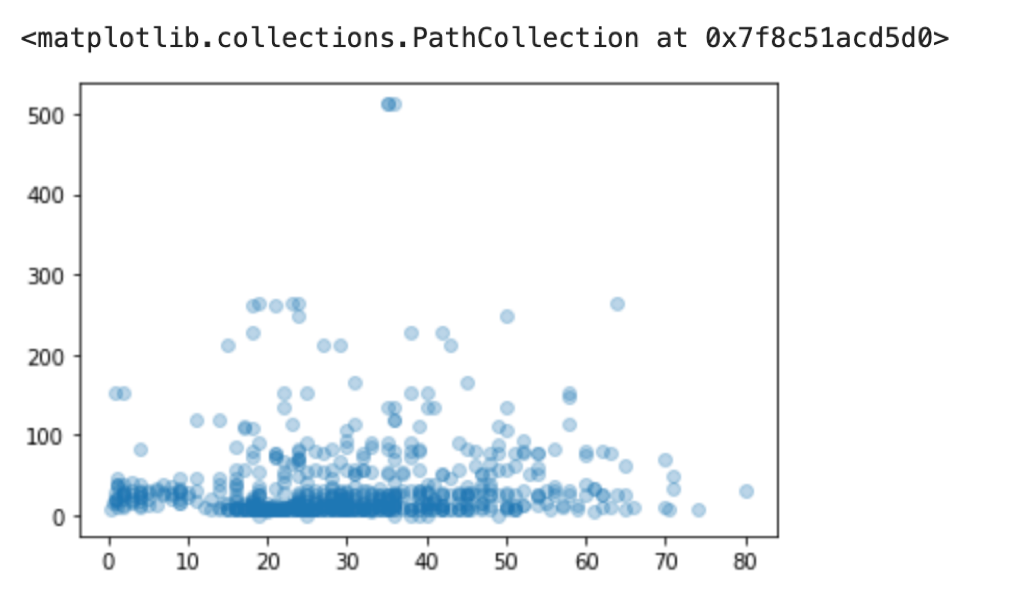
データが多くなるとマーカーが重なるので alpha を指定して透明度をあげるとデータの重なり具合もわかって便利です.
散布図でデータをみることで,乗客の年齢層とか料金の分布がわかります.やけに値段の高いデータがありますね笑 あと,年齢が高いと値段も高いかなと思ったのですが,あまりそういう風には見えないですね.(統計学を使うと,こういったことをもっと定量的に評価することができます.)
ヒストグラム : plt.hist()
ヒストグラムも,データの分布状況を確認するのに有益な図です.
縦軸に「度数」,横軸に「階級」を表しています.「度数」というのはfrequencyで,頻度を表すものだと思ってください.「階級」はcategoryで,値の区間(例えば温度なら0~10度, 10度~20度,,,)だと思ってください.「階級」のことをbin(ビン)とも呼びます.
説明するよりみた方が早いです.ヒストグラムを今まで見たことない人はいないと思うので,見たら「あーこれね」ってなると思う
|
1 2 |
plt.hist(df['Age']) plt.show() |
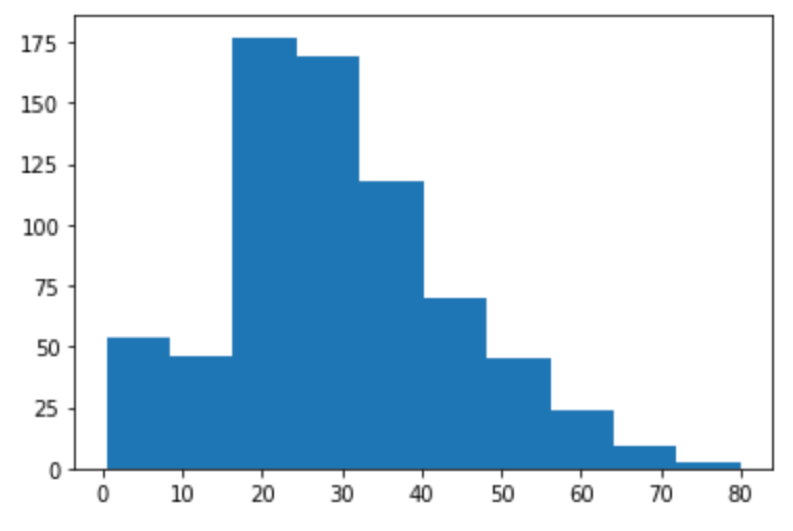
(plt.show()はなくてもいいんですが,これがないとplt.histの返り値が表示されて鬱陶しいのでつけてます)
あるAgeの区間(階級)に何人いるか(度数)を棒で表したのを区間ごとに並べているグラフ(=ヒストグラム)です.
この区間(=bin)の幅を変更したい時がよくあります. bins 引数を指定しましょう.横軸の値の幅をbinsに指定した値で割った区間にすることができます.
|
1 2 |
plt.hist(df['Age'], bins=50) plt.show() |
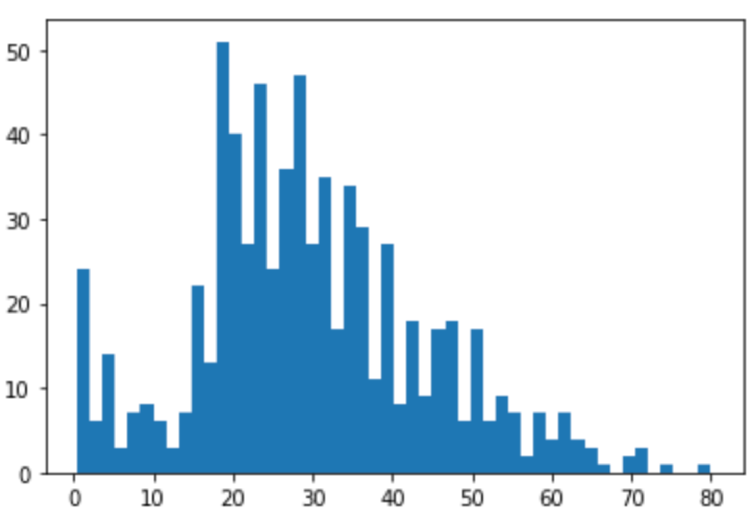
先ほどのヒストグラムよりbinが細かくなっているのがわかります.(50で分割してますからね!)
ヒストグラムを見ると,「20代が多いな〜」とか,「キッズも結構いるなぁ」とか,そんな感じでデータの分布が視覚的に認識できるので便利です.
20才以上は年齢があがるにつれ乗客が減ってますね.
箱ひげ図 : plt.boxplot()
箱ひげ図って,変な名前ですね.私はいつも「box plot」と読んでます.日本でもbox plotで通じると思います.
統計学を勉強してないと,もしかしたら知らない人も多いかもしれません.
box plotは統計量も一緒に表すことができるので,論文などではよく使う図です.
|
1 2 3 |
df = df.dropna(subset=['Age']) plt.boxplot(df['Age']) plt.show() |
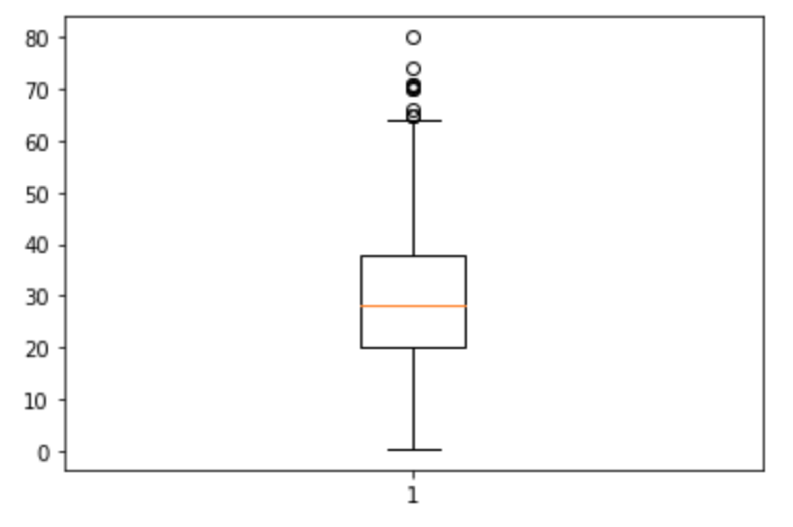
NaNがあると表示できないので,dropna後にplotします.(dropnaについては第14回を参照ください)
以下のようにみます.
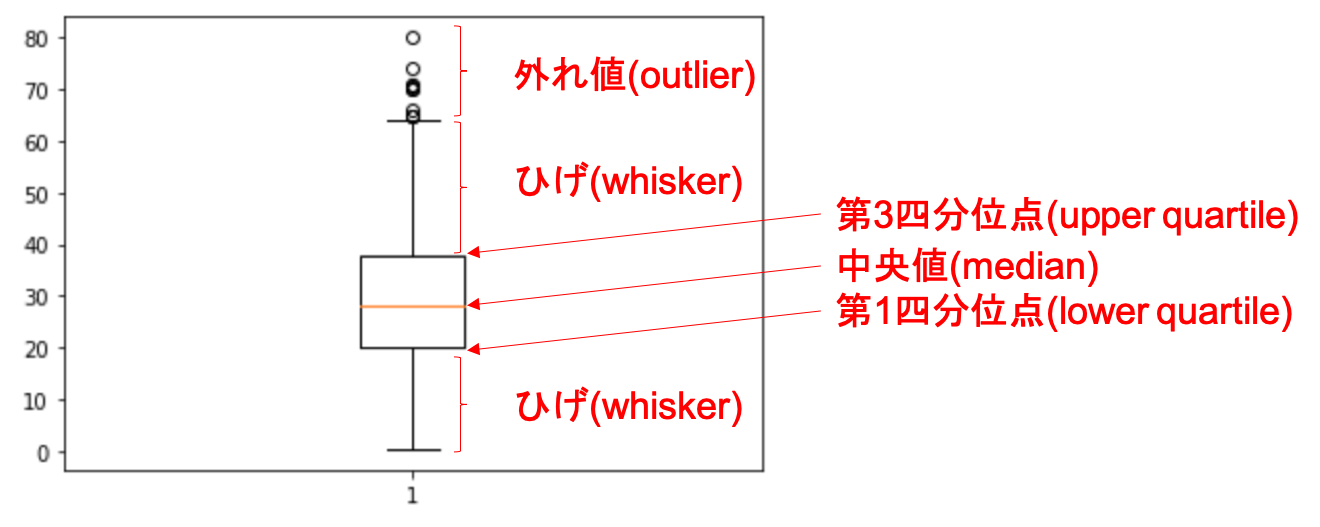
ひげの端をどうするかとか,外れ値を表示するかとか,箱の形,幅が違うとか,色々な変種がありますが,基本はこれです.
第3四分位点(Q3) – 第1四分位点(Q1)のこと(つまりbox plotの箱の高さ)をIQRといいますが,ひげの端はQ1-1.5*IQRとQ3+1.5*IQRになってます.
1.5というのはデフォルトの値で,whis引数で変更が可能です.ただ,今はあまり気にしなくていいと思います.
データの分布が統計量と一緒にわかるので,より定量的に分布を認識できます.便利です.
まとめ
今回はグラフの装飾と,散布図,ヒストグラム,箱ひげ図を紹介しました.
- plt.scatter() : 散布図
- plt.hist() : ヒストグラム
- plt.boxplot() : 箱ひげ図
これでmatplotlibについては終わりです.
plotって,本当に色々と細かい調整ができるので,正直ブログでは細かいところまで紹介することはできません.
公式ページに色々なグラフの例があるので,余力がある人は参考にしてみてください.
それでは!
追記)次回書きました.plotライブラリのド本命Seabornを使います!実業務ではmatplotlibではなくSeabornを使うことの方が多いと思います.是非使えるようにしましょう!