追記)機械学習超入門動画講座を公開しました!動画で効率よく学習をしたい人はこちら(現在割引クーポン配布中です)
データサイエンス入門の機械学習編第7回です!(講座全体の説明と目次はこちら)
今回の記事以降,学習した機械学習モデルの精度の測り方にフォーカスして解説していき,今回の記事では過学習や汎化性のという概念と,汎化性能を測る最もシンプルな方法であるhold-out法と言うものを紹介します.
今までの記事では手元にあるデータを全て学習データとして扱って機械学習のモデルを構築していました.
そして,学習データの損失が一番小さくなるようにモデルのパラメータを求め,それを最適なモデルとして選んでいましたね.
実は,学習データの損失が一番小さいモデルが必ずしも最適なモデルとは限らないんです!
これには”過学習”と”汎化性能”という概念が絡んできます.機械学習のモデルを構築する上で絶対に知っておくべき内容なのでしっかり抑えておきましょう!
これらがわかっていないと,どんなに機械学習のアルゴリズムを理解していても,それらを使って正しいモデルを構築することができません.
それではみてみましょー!
目次
過学習と汎化性能とは
過学習(overfitting)とは,簡単にいうと学習データにフィットしすぎていて,未知のデータに対して高い精度で予測や分類ができない状態のことを言います.
例えるなら,本当は英語力を上げたいのに,TOEICの猛勉強して高い点数を取れるようになったけど,一般的な英語力はさほど向上してないって感じでしょうか?
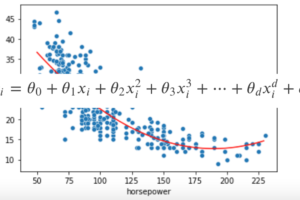
第一回で紹介した家賃と広さのデータで考えてみましょう.
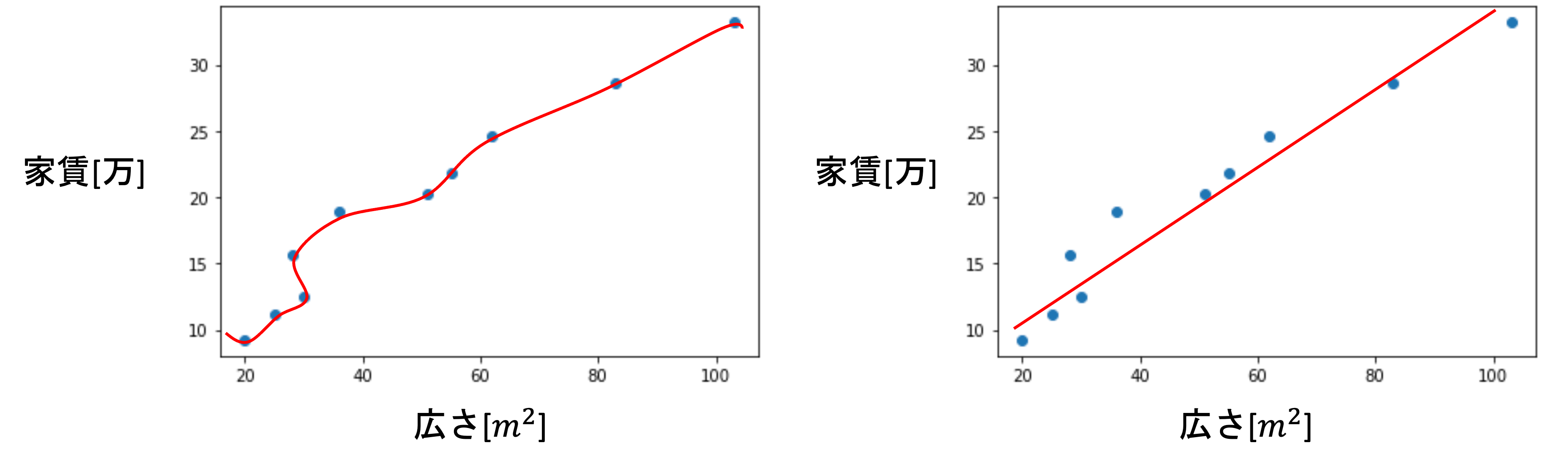
右の図は線形モデルでモデルを構築した例で,左の図は学習データにピッタリとあったモデルを構築した例です.
左の方は損失が限りなく0に近く,右の方はある程度損失があるモデルです.
学習データというのは,数あるデータからたまたま得られたデータであり,そのたまたま得られたデータに完全にフィットさせてしまうと,あまりにも偏ったモデルになってしまい,未知のデータに対して損失が大きくなる可能性が高いです.
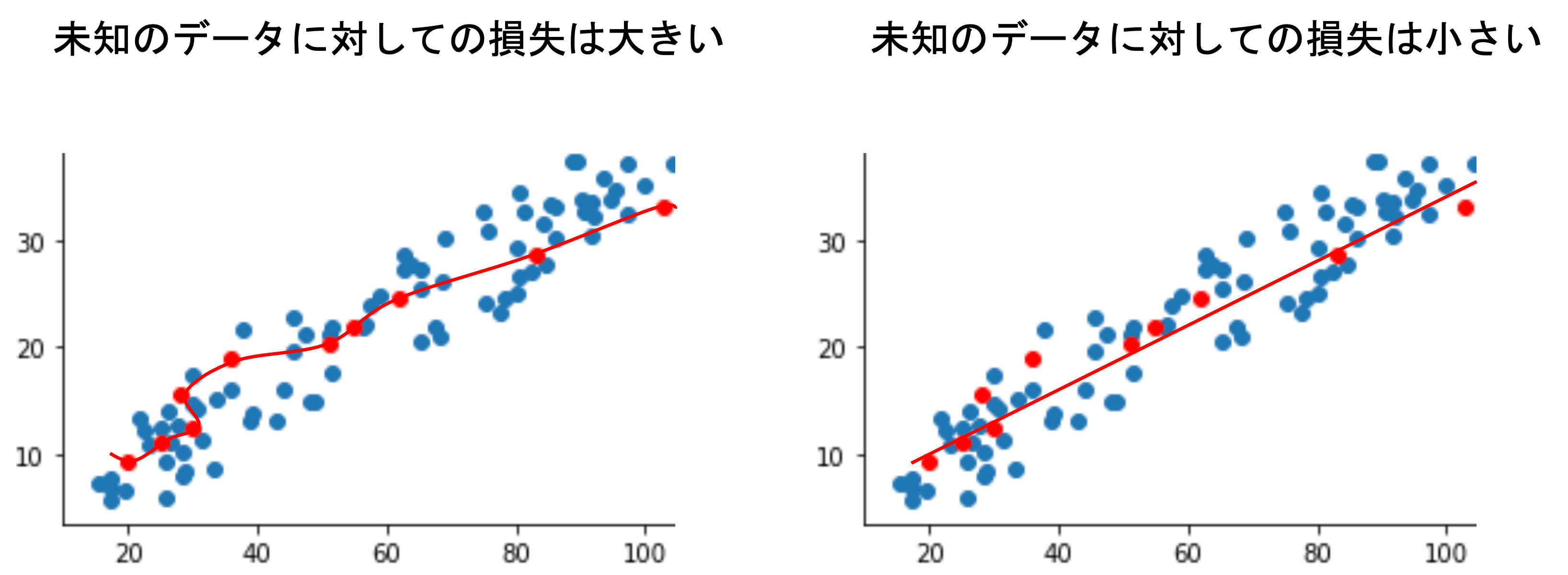
このような状況に陥っていることを「モデルが過学習(overfitting)している」といいます.

その通り!機械学習のモデルを構築する真の目的は,未知のデータや将来のデータに対して高い精度で予測できることです.
例えば株価を予測するモデルを作ったとして,過去の株価に対して精度よく予測しても意味がないですよね?将来の未知の株価に対して高い精度で予測できないと意味がありません.
このように,学習データだけでなく未知のデータに対しても正しく予測できる性能のことを汎化性能と言います.
機械学習でモデルを構築する際には,必ずこの汎化性能が高くなるように構築してください.
常に「過学習してないか?」「未知のデータに対して精度が高いか?(汎化性能は高いか?)」を意識する必要があります.

汎化性能の計り方は色々あります.今回の記事から複数に分けて一つ一つ解説して行きます.
今回の記事では最もシンプルで使いやすいhold-outという手法を紹介します.
1. hold-out法(データセットを学習データとテストデータに分ける)
最もシンプルな方法はhold-out法と呼ばれる手法で,手元にあるデータセットを学習用と汎化性能を測るためのテスト用の二つに分けて,学習用のデータのみでモデルを構築し,テスト用のデータで汎化性能を測ります.
テスト用のデータを未知のデータとして扱うことで汎化性能を測れるというわけです.
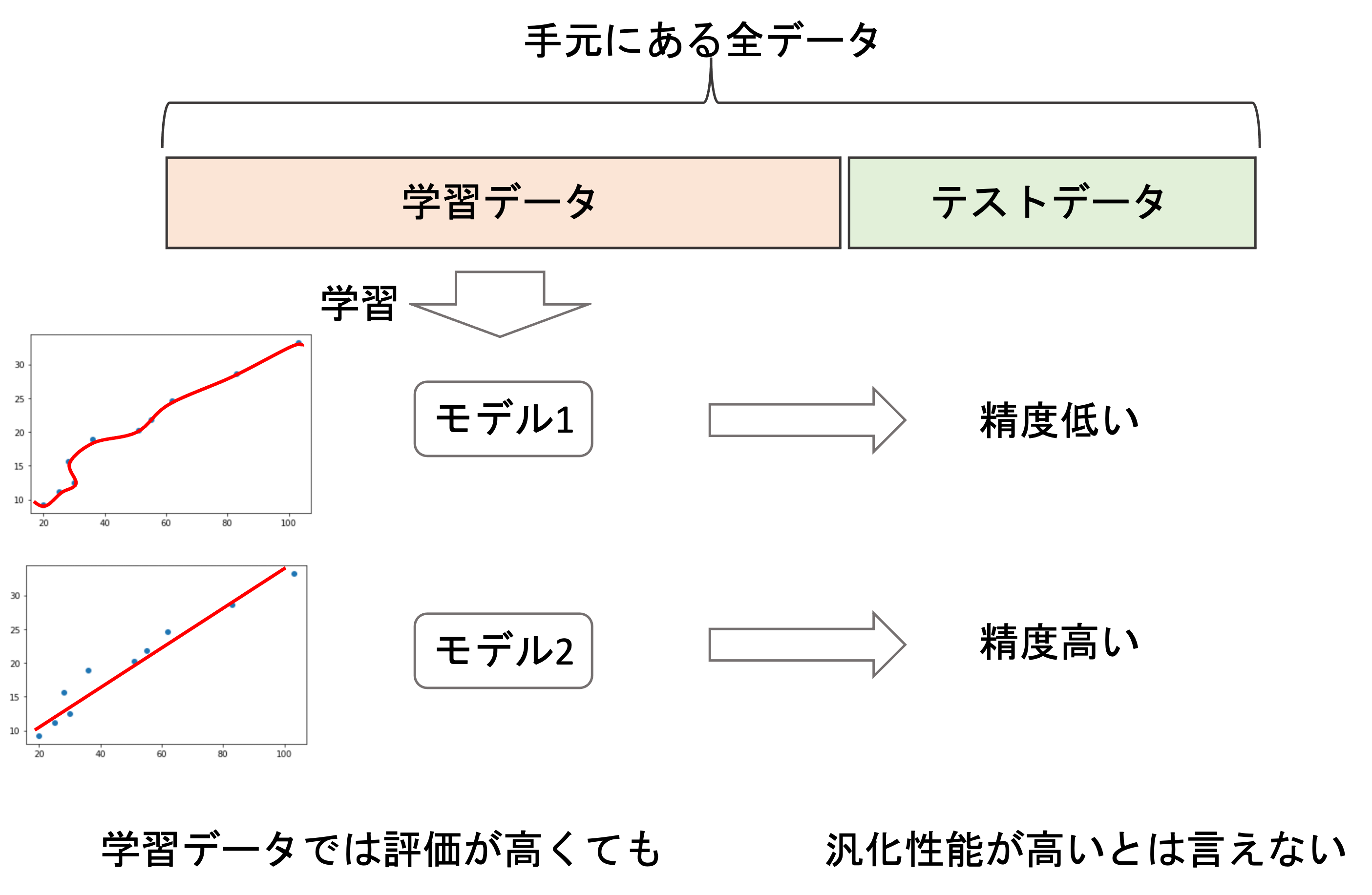
例えば学習データを使って複数のモデルを構築し,どれが最良のモデルなのかを選択する際に,テストデータを使って汎化性能がもっとも高いモデルを選ぶことができます.ここで,必ずしも学習データでの精度が高いモデルが汎化性能も高いとは限らないことに注意しましょう
よく使われる学習データとテストデータの割合は,7:3や5:5です.普通学習データの方が多くなるようにします.学習データを増やすことで精度が上がるからです.また,分割は基本的にはランダムに行います.(完全にランダムではない場合がありますが,それについては今後の記事で取り上げます.)
それでは早速Pythonで実装してみましょう.scikit-learnを使えば簡単に実装することができます.
Pythonでhold-outでデータを分割する
今回も第4回で使ったdiamondsデータセットを使いましょう.
|
1 2 3 4 5 |
import seaborn as sns df = sns.load_dataset('diamonds') df = df[(df[['x','y','z']] != 0).all(axis=1)] X = df['carat'].values.reshape(-1, 1) y = df['price'].values |
第4回同様,特徴量caratからpriceを予測するモデルを考えます.第4回や第5回の時は全データをそのまま学習( .fit() )させていたんですが,hold-outを使ってこれを学習用とテスト用に分割しましょう.
scikit-learnの model_selection というモジュールにある train_test_split 関数を使えば簡単にhold-outで分割することができます.
|
1 2 |
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True, random_state=0) |
train_test_split関数には,全データの X , y のNumPyArrayを入れればOKです.すると,それぞれ学習用とテスト用に分けてくれます.
主な引数としては, test_size にテストデータの割合, shuffle に分割前にデータをシャッフルするかどうか, random_state には乱数のタネを指定することで,シャッフルおよび今回の分割を再現できるようになります.
こうして分割され,得られた学習データのみでモデルをfitさせます
|
1 2 3 4 |
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test) |
このようにして X_train を使って学習したモデルに対してテストデータ X_test を .predict() させた結果 y_pred と y_test を比較して精度を測ります.具体的な精度の指標についてはまた今後の講座で紹介しますが,ひとまずhold-outの流れと,Pythonでのやり方は分かったかと思います!
検証データ(Validation data)について
今回は学習データとテストデータの分割について述べましたが,検証データという別のセットを作って,3分割にすることもあります.
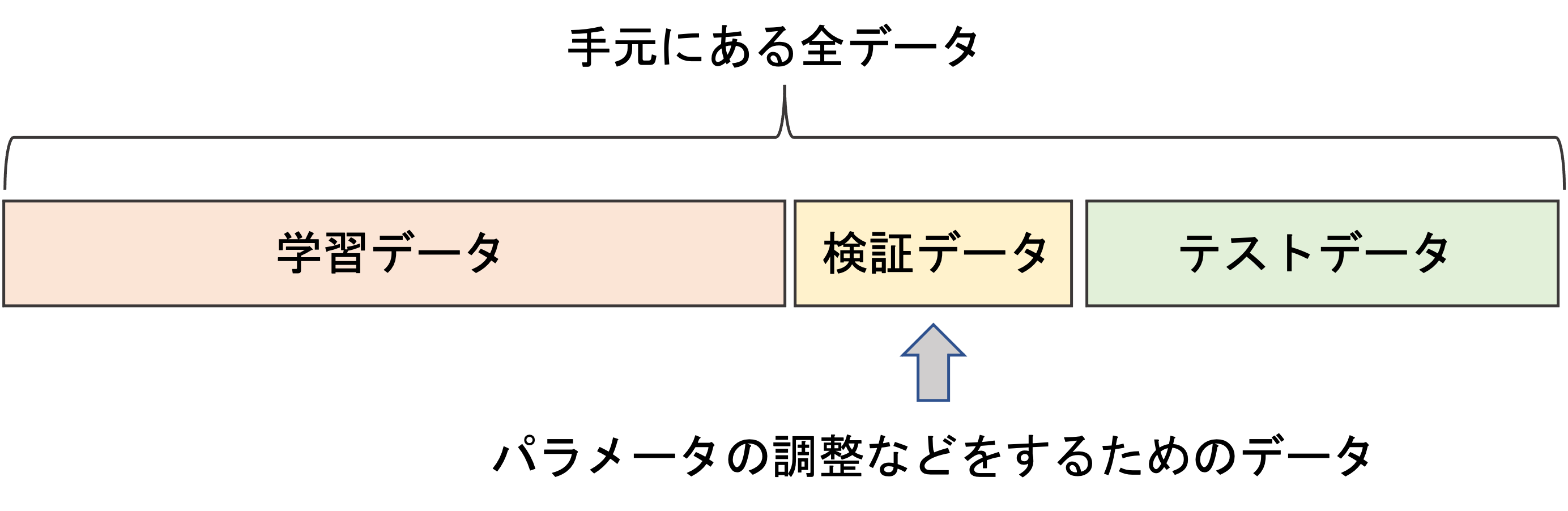
学習データで学習をしてテストデータで評価した際に,思ったより精度が低かったのでさらにモデルのパラメータを変更して学習してテストデータで評価して...というのを繰り返すと,本来テストデータは未知のデータという前提なのに,テストデータに対して過学習したモデルができてしまう恐れがあります.
それを避けるために,検証データ(validation data)というデータを作っておき,学習プロセスのイテレーションに組み込み,学習データで学習したあとにテストデータを使うのではなく検証データを使ってパラメータを調整します.
このようにして,テストデータではあくまでも最終的な精度を測るためのものとします.検証データとテストデータは混合しやすいですが,役割が違うので注意ですね!
hold-outの欠点
このhold-out方は,非常にシンプルでいいんですが欠点があります.
それは「全てのデータを学習データとして使えない」ことです.機械学習では,学習データは多ければ多いほうがいいというのが基本です.(※必ずしもそうとは限らないケースもありますが,それについては別記事で解説します)
つまり,「ただでさえ手元にこれしかデータがないのに,この一部しか学習に使えないなんて困るよ!」ということが起こるわけです.
また,ランダムに分割しているので結果にランダム性が生じ,確かな結果を得ることができません.
これらの問題を緩和するための手法を次の記事で紹介します!hold-outはシンプルですが,実際の業務ではもっと一般的な手法があります.それについて次の記事で紹介したいと思います.
まとめ
今回は,過学習と汎化性能について述べ,汎化性能を測る最もシンプルな方法としてhold-out法を紹介しました.
これらの概念は機械学習をする上で非常に重要な概念なので常に頭に入れましょう!
- 学習データにフィットしすぎて,未知のデータに対して精度が低くなってしまうことを過学習という
- 未知のデータに対しても正しく予測できる能力のことを汎化性能という
- hold-out法は汎化性能を測る最もシンプルな方法
- hold-outは,全てのデータを学習データとテストデータにわけ,学習データのみで学習を行い,テストデータでモデルを評価する
- hold-outは全てのデータを学習データとして使えないため,一般的には精度が下がってしまう
- hold-outはランダムにデータを分割するため,結果にランダム性が伴い,確かな結果を得ることができない
次の記事では,hold-out法の欠点を緩和するための別の手法を紹介します!実務では次の記事で紹介する手法が最も一般的に使われるので,超重要記事となります.
それでは!
追記)次の記事書きました.