前々回までの記事で決定木について解説し,前回の記事でアンサンブル学習の概要について説明しました.(講座全体の説明と目次はこちら)
今回は,前回解説したバギングと決定木を組み合わせたランダムフォレストというアルゴリズムを紹介します.
ランダムフォレストは非常に精度が高く,今でもよく使われるアルゴリズムです.機械学習をする上では必修のアルゴリズムと言えます.
それではみていきましょう〜!
追記) 機械学習超入門本番編ではランダムフォレストについてさらに詳しく解説をしています.さらに理解を深めたい方は是非受講ください:)
目次
ランダムフォレストの概要
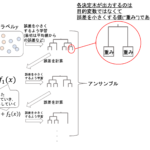
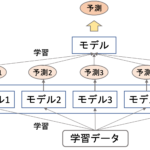
ランダムフォレスト(random forest)は,forest(森)というくらいなんで,決定木を複数使うアンサンブル学習のアルゴリズムです.(複数の決定木でフォレスト(=森)なんて,おしゃれな名前ですよね笑)
ランダムフォレストでは,アンサンブルの中でもバギングを使ったアルゴリズムです.
バギングは,ブートストラップ法を使ってサンプル抽出した複数のデータ群に対してそれぞれモデルを構築して,最後に平均や多数決を取るんでした(前回記事参照)
ランダムフォレストはこの「バギング+決定木」に少し工夫をしてさらに精度を向上させます.

ランダムフォレストでは,それぞれの決定木において,一部の特徴量のみを分割するようにします.
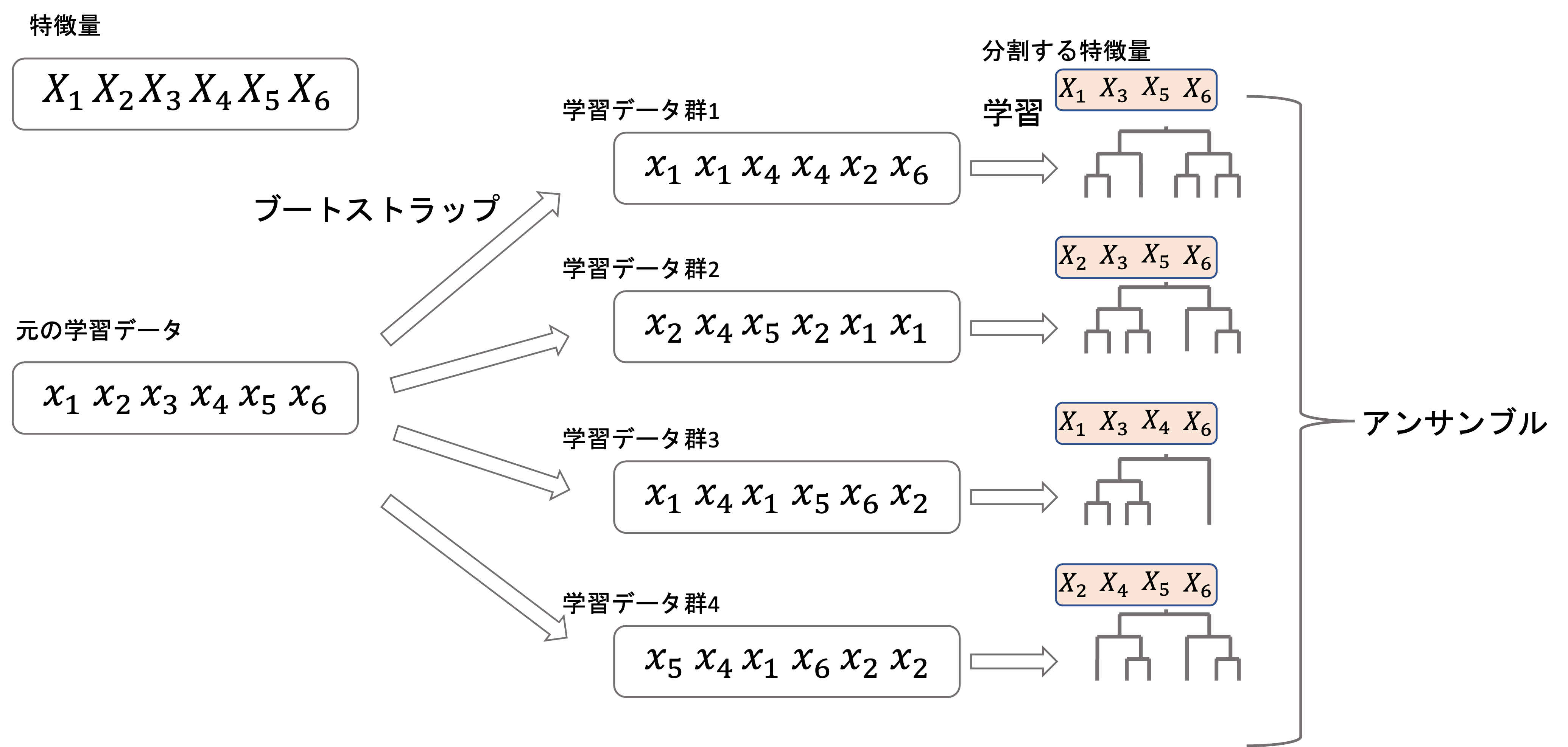
つまり,それぞれの決定木を構築する際に
- 一部の学習データを使わない
- 一部の特徴量でしか分割を行わない
この2点を行うことによって,ちょっとずつ違う決定木を作ろうとしているわけですね!
前回の記事でも解説した通り,アンサンブルのポイントはいかに「互いに相関が弱い」モデルを組み合わせるかです.ランダムフォレストではデータや特徴量を少しづつ変えることでそれを実現しています.
ランダムフォレストは”random”という名前の通り,それぞれの決定木モデルで分割する特徴量をランダムに選択します.
全部で\(n\)個の特徴量がある場合,一部の\(n’\)個の特徴量をそれぞれランダムに選択して,それぞれの決定木の分割に使います.
\(n’\)をいくつにするかはパラメータとして色々試してみればいいですが,よく使われるのは\(n’=\sqrt{n}\)です.
Pythonでランダムフォレストを作ってみる
それでは早速,Pythonでランダムフォレストを構築してみましょう!
scikit-learnには既にランダムフォレストを簡単に構築できるクラス, sklearn.ensemble.RandomForestClassifier と sklearn.ensemble.RandomForestRegressor が用意されています.それぞれ分類器用と回帰用ですが,両者はほとんど同じ仕様です.(今回は分類器の例です)
sklearn.tree ではなくて sklearn.ensemble に入っているので注意しましょう今回も第29回で扱ったタイタニックデータを使ってランダムフォレストを作ってみたいと思います.様々な特徴量を使って,搭乗者が生存したかどうかを予測する分類器を作ります.(タイタニックデータについてはデータサイエンスのためのPython第11回を参照ください)
データ準備
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd import seaborn as sns # データロード df = sns.load_dataset('titanic') # 欠損値drop df = df.dropna() # 特徴量 X = df.loc[:, (df.columns!='survived') & (df.columns!='alive')] # 質的変数をダミー変数化 X = pd.get_dummies(X, drop_first=True) # 目的変数 y = df['survived'] |
モデル構築
sklearn.ensemble.RandomForestClassifier クラスを使ってランダムフォレストを作ります.これには色々とパラメータを入れることができますが,重要なのは以下の引数です.
- n_estimators : アンサンブルする決定木の数.デフォルトは100. 数が多い方がいいがその分時間がかかるので注意
- max_depth : 決定木の深さ.何も指定しない( None )と,最後まで分割が走ってしまい時間がかかる上に過学習してしまうので注意(他の条件により途中で分割が終わるようなら None でもOK)
- min_samples_split : intで指定した場合は分割する際に必要な最低限のデータ数で,floatを指定すると全データ数の割合
- max_features : 決定木に使う特徴量の数.デフォルトは 'auto' で,特徴量数\(n\)とすると\(\sqrt{n}\)になる
- ccp_alpha : cost complexity pruningのalphaの値. これについては第29回で解説した通り
決定木の tree.DecisionTreeRegressor や tree.DecisionTreeClassifier で使っていた引数をそのまま使えるようになってます.
特に n_estimators はチューニングパラメータとして色々試していい引数です.今回はデフォルトの100で試してみますが,興味がある人は色々試してみてください.(基本的には大きい方がいいです)
また, max_features は,特に理由がなければデフォルトの\(\sqrt{n}\)でOKですが,チューニングパラメータとして色々試すのも良いかと思います.
今回は比較用に普通の決定木も作ります.第29回の結果から ccp_alpha=0.02 を指定します.
|
1 2 3 4 |
from sklearn.ensemble import RandomForestClassifier from sklearn import tree rf_model = RandomForestClassifier(random_state=0, ccp_alpha=0.02) dt_model = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=0.02) |
学習と評価
今回は5fold CVを行います.scikit-learnには,k-fold CVを複数回行ってくれるものがあります.さらに,今回はStratifiedバージョンのものを使ってみましょう
Stratified(層化)とは,学習データとテストデータを分ける際に,クラスの割合が元のデータセットと同じになるように分けることです.学習データとテストデータでクラスが偏ることを防ぎます.
これは, sklearn.model_selection.RepeatedStratifiedKFold クラスを使用すればOKです.引数には n_splits にk-foldのkを, n_repeats にCVを繰り返す回数を指定します.今回は5foldを3回で,計15回学習と評価を繰り返します.
あとは第9回同様, sklearn.model_selection.cross_val_score で精度を算出します.今回はaccuracyを評価指標とします.
|
1 2 3 4 5 |
from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=0) rf_scores = cross_val_score(rf_model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) dt_scores = cross_val_score(dt_model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) |
それではそれぞれのモデルのCV評価の結果をDataFrameにして,sns.barplotで表示してみましょう
|
1 2 |
score_df = pd.DataFrame({'random forest': rf_scores, 'decision tree': dt_scores}) sns.barplot(data=score_df) |
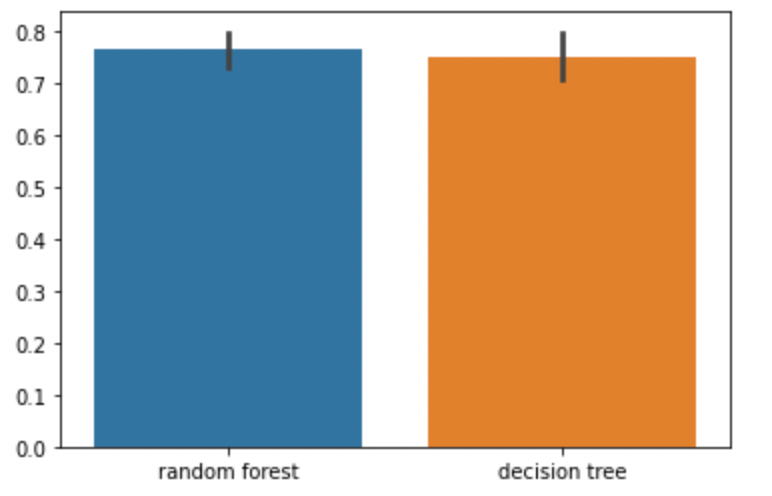
わずかですが,ランダムフォレストの方が精度が高い結果となっています.error barを見ると,ランダムフォレストの方が分散が小さいのがわかります.(これは複数の決定木の平均をとっているからですね.まさにvarianceを下げているわけです.)
例えば対応のあるt検定で有意差をみてもいいかもしれません.
|
1 2 |
from scipy import stats stats.ttest_rel(score_df['random forest'], score_df['decision tree']) |
|
1 |
Ttest_relResult(statistic=0.9517151387117377, pvalue=0.35738431321019015) |
p値>0.05なので,有意差なしという結果になっています.
一般的にランダムフォレストは一つの決定木よりも精度が高くなりますが,データやパラメータによってはそこまで差が出ない場合もあります.興味がある人は様々なパラメータで試してみてください!
特徴量の重要度を見る
ランダムフォレストは,各決定木の詳細を見るのは難しいですが,全体での特徴量の重要度を確認することができます.
決定木の分割の際,例えばジニ不純度が小さくなればなるだけその特徴量は重要だと言えます.ランダムフォレストは,アンサンブルに使用した決定木の各特徴量での分割でのジニ不純度の減少度合いの統計量を見ることによって,どの特徴量の重要度を出すことができます
|
1 2 |
rf_model.fit(X, y) plt.barh(X.columns, rf_model.feature_importances_) |
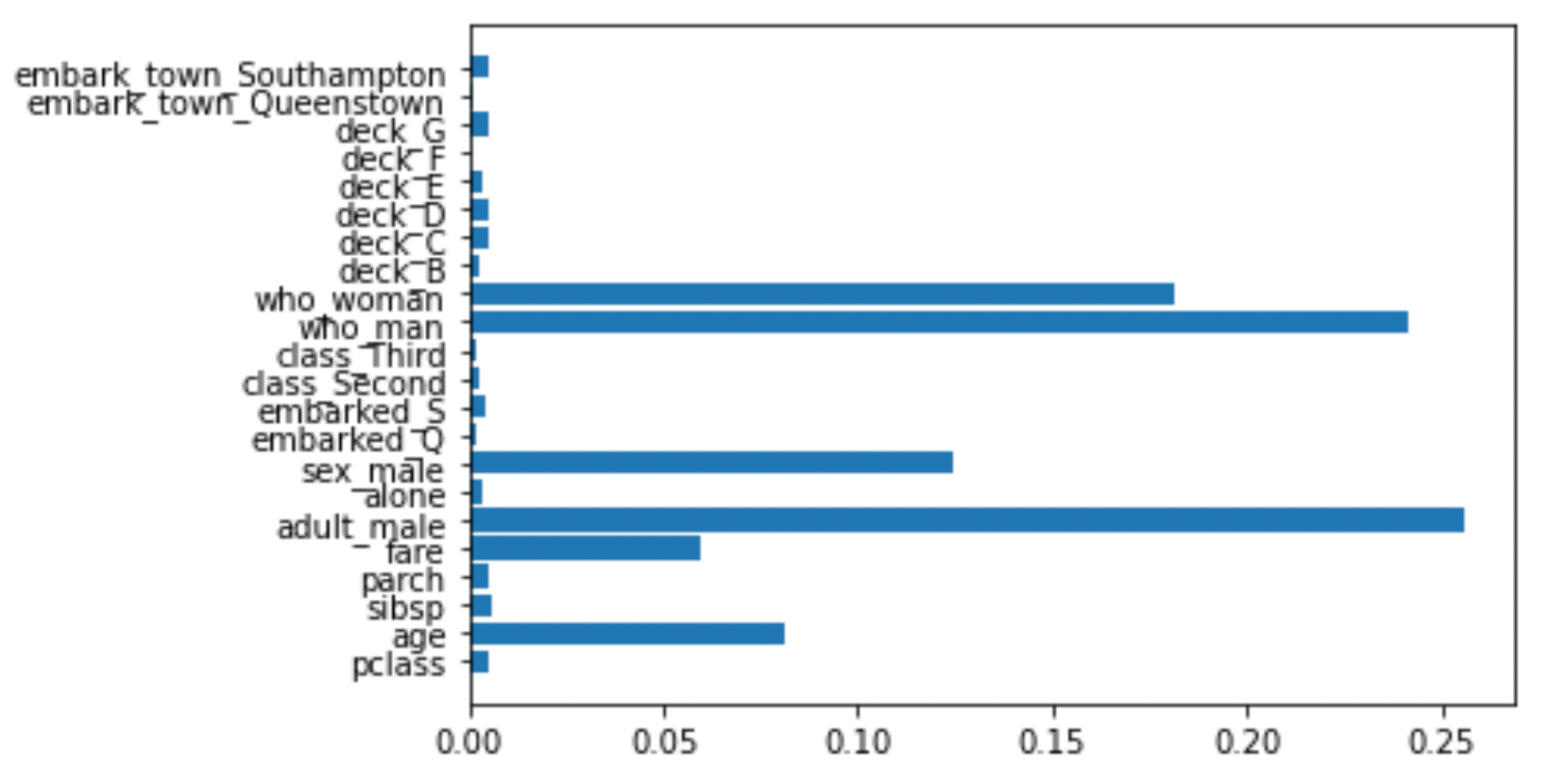
このようにplotすれば,どの特徴量が重要なのかが一目でわかります.性別や年齢,運賃の重要度が高いことがわかります.タイタニック号の生死を分けた重要なファクターとしては納得のいく結果ですね.
Pythonのライブラリの使い方があやしい人は是非動画講座で学習しましょう!☆4.8という超高評価をいただいております↓是非参考にしてください◎(下の記事でクーポンを発行しております.そちらも是非お使いください!)
まとめ
今回はランダムフォレストについて解説をしました.
- ランダムフォレストは,バギング+決定木にそれぞれの決定木で分割する特徴量をランダムに選択するよう工夫したアルゴリズム
- 各決定木でランダムに選択する特徴量の数\(n’\)は全ての特徴量の数を\(n\)とすると\(n’=\sqrt{n}\)とするのが一般的
- ランダムフォレストはバギングにより学習データを少し変え,ランダム性により特徴量を少し変えることで,互いに相関の低い複数の決定木を生成する
- ランダムフォレストは,使用した決定木全体での特徴量の重要度を算出することができる
ランダムフォレストは今でもよく使われるくらい精度が高いモデルです.
基本的にはより多くの決定木を使用した方がいいので,精度が上がらなくなるまで n_estimators を増やしていくといいでしょう.ただし,計算量も増大するので注意してください.1000を超える決定木を使うこともよくあります.
次回は,ブースティングと決定木を組み合わせたアルゴリズムを紹介していきます.バギングよりもブースティングの方が高い精度を期待できるので,次回の記事で紹介するアルゴリズムも非常に重要なものになります.
それでは!
追記)次回は”最強”と言われているXGBoostというブースティングのアルゴリズムを紹介します!